27 KiB
6. Классы. Объектно-ориентированный стиль
- 6.1. Классы
- 6.2. Имена объектов – это ссылки
- 6.3. Жизненный цикл объекта
- 6.3.1. Конструкторы
- 6.3.2. Делегирование конструкторов
- 6.3.3. Алгоритм построения объекта
- 6.3.4. Уничтожение объекта и освобождение памяти
- 6.3.5. Алгоритм уничтожения объекта
- 6.3.6. Стратегия освобождения памяти
- 6.3.7. Статические конструкторы и деструкторы
- 6.4. Методы и наследование
- 6.4.1. Терминологический «шведский стол»
- 6.4.2. Наследование – это порождение подтипа. Статический и динамический типы
- 6.4.3. Переопределение – только по желанию
- 6.4.4. Вызов переопределенных методов
- 6.4.5. Ковариантные возвращаемые типы
- 6.5. Инкапсуляция на уровне классов с помощью статических членов
- 6.6. Сдерживание расширяемости с помощью финальных методов
- 6.6.1. Финальные классы
- 6.7. Инкапсуляция
- 6.7.1. private
- 6.7.2. package
- 6.7.3. protected
- 6.7.4. public
- 6.7.5. export
- 6.7.6. Сколько инкапсуляции?
- 6.8. Основа безраздельной власти
- 6.8.1. string toString()
- 6.8.2. size_t toHash()
- 6.8.3. bool opEquals(Object rhs)
- 6.8.4. int opCmp(Object rhs)
- 6.8.5. static Object factory (string className)
- 6.9. Интерфейсы
- 6.9.1. Идея невиртуальных интерфейсов (NVI)
- 6.9.2. Защищенные примитивы
- 6.9.3. Избирательная реализация
- 6.10. Абстрактные классы
- 6.11. Вложенные классы
- 6.11.1. Вложенные классы в функциях
- 6.11.2. Статические вложенные классы
- 6.11.3. Анонимные классы
- 6.12. Множественное наследование
- 6.13. Множественное порождение подтипов
- 6.13.1. Переопределение методов в сценариях множественного порождения подтипов
- 6.14. Параметризированные классы и интерфейсы
- 6.14.1. И снова гетерогенная трансляция
- 6.15. Переопределение аллокаторов и деаллокаторов
- 6.16. Объекты scope
- 6.17. Итоги
С годами объектно-ориентированное программирование (ООП) из симпатичного малыша выросло в несносного прыщавого подростка, но в конце концов повзрослело и превратилось в нынешнего уравновешенного индивида. Сегодня мы гораздо лучше осознаем не только мощь, но и неизбежные ограничения объектно-ориентированной технологии. В свою очередь, это позволило сообществу программистов понять, что наиболее выгодный подход к созданию надежных проектов – сочетать сильные стороны ООП и других парадигм программирования. Это довольно отчетливая тенденция: все больше современных языков программирования или включают эклектичные средства, или изначально разработаны для применения ООП в сочетании с другими парадигмами. D принадлежит к последним, и его достижения в сфере гармоничного объединения разных парадигм программирования некоторые даже считают выдающимися. В этой главе исследуются объектно-ориентированные средства D и их взаимодействие с другими средствами языка. Хорошая стартовая площадка для глубокого изучения объектно-ориентированной парадигмы – классический труд Бертрана Мейера «Объектно-ориентированное конструирование программных систем» (для более формального изучения лучше подойдут «Типы в языках программирования» Пирса).
6.1. Классы
Единицей объектной инкапсуляции в D служит класс. С помощью классов можно создавать объекты, как вырезают печенье с помощью формочек. Класс может определять константы, состояния классов, состояния объектов и методы. Например:
class Widget
{
// Константа
enum fudgeFactor = 0.2;
// Разделяемое неизменяемое значение
static immutable defaultName = "A Widget";
// Некоторое состояние, определенное для всех экземпляров класса Widget
string name = defaultName;
uint width, height;
// Статический метод
static double howFudgy()
{
return fudgeFactor;
}
// Метод
void changeName(string another)
{
name = another;
}
// Метод, который нельзя переопределить
final void quadrupleSize()
{
width *= 2;
height *= 2;
}
}
Объект типа Widget создается с помощью выражения new, результат вычисления которого сохраняется в именованном объекте: new Widget (см. раздел 2.3.6.1). Для обращения к идентификатору, определенному внутри класса Widget, расположите его после имени объекта, с которым вы хотите работать, и разделите эти два идентификатора точкой. Если член класса, к которому нужно обратиться, является статическим, перед его идентификатором достаточно указать имя класса. Например:
unittest
{
// Обратиться к статическому методу класса Widget
assert(Widget.howFudgy() == 0.2);
// Создать экземпляр класса Widget
auto w = new Widget;
// Поиграть с объектом типа Widget
assert(w.name == w.defaultName); // Или Widget.defaultName
w.changeName("Мой виджет");
assert(w.name == "Мой виджет");
}
Обратите внимание на небольшую хитрость. В приведенном коде использовано выражение w.defaultName, а не Widget.defaultName. Для обращения к статическому члену класса всегда можно вместо имени класса использовать имя экземпляра класса. Это возможно, потому что при обработке выражения слева от точки сначала выполняется разрешение имени и только потом идентификация объекта (если потребуется). Выражение w в любом случае вычисляется: будет оно использовано или нет.
6.2. Имена объектов – это ссылки
Проведем небольшой эксперимент:
import std.stdio;
class A
{
int x = 42;
}
unittest
{
auto a1 = new A;
assert(a1.x == 42);
auto a2 = a1;
a2.x = 100;
assert(a1.x == 100);
}
Этот эксперимент завершается успешно (все проверки пройдены), а значит, a1 и a2 не являются разными объектами: изменение объекта a2 действительно отразилось и на ранее созданном объекте a1. Эти две переменные – всего лишь два разных имени одного и того же объекта, следовательно, изменение a2 влияет на a1. Инструкция auto a2 = a1; не создает новый объект типа A, а только дает существующему объекту еще одно имя (рис. 6.1).
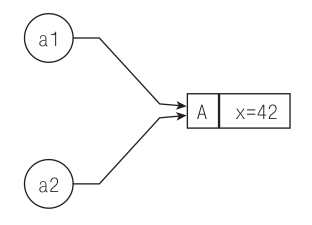
Рис. 6.1. Инструкция auto a2 = a1 только вводит дополнительное имя для того же внутреннего объекта
Такое поведение соответствует принципу: все экземпляры класса являются сущностями, то есть обладают «индивидуальностью» и не предполагают копирования без серьезных причин. Экземпляры значения (например, встроенные числа), напротив, характеризуются полным копированием; новый тип-значение определяется с помощью структуры (см. главу 7).
Итак, в мире классов сначала нам встречаются объекты (экземпляры класса), а затем ссылки на них. Воображаемые стрелки, присоединяющие ссылки к объектам, называются привязками (bindings); мы, например, говорим, что идентификаторы a1 и a2 привязаны к одному и тому же объекту, другими словами, имеют одну и ту же привязку. С объектами можно работать только через ссылки на них. Получив при создании место в памяти, объект остается там навсегда (по крайней мере до тех пор, пока он вам нужен). Если вам надоест какой-то объект, просто привяжите его ссылку к другому объекту. Например, если нужно, чтобы две ссылки обменялись привязками:
unittest
{
auto a1 = new A;
auto a2 = new A;
a1.x = 100;
a2.x = 200;
// Заставим a1 и a2 обменяться привязками
auto t = a1;
a1 = a2;
a2 = t;
assert(a1.x == 200);
assert(a2.x == 100);
}
Вместо трех последних строк можно было бы использовать универсальную вспомогательную функцию swap из модуля std.algorithm: swap(a1, a2), но явная запись процесса обмена нагляднее. На рис. 6.2 продемонстрированы привязки до и после обмена.
Сами объекты остаются на том же месте, то есть после создания они никогда не перемещаются в памяти. Просто замечательно, объект никогда не исчезнет: можно рассчитывать, что объект навсегда останется там, куда он был помещен при создании. (Сборщик мусора перерабатывает в фоновом режиме те объекты, которые больше не используются.) Ссылки на объекты (в данном случае a1 и a2) можно заставить «смотреть в другую сторону», переназначив их привязку. Когда библиотека времени исполнения обнаруживает, что для какого-то объекта больше нет привязанных к нему ссылок, она может заново использовать выделенную под него память (этот процесс называется сбором мусора).1 Такое поведение
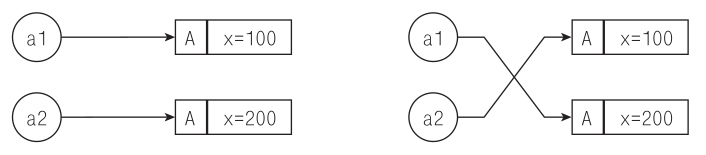
Рис. 6.2. Привязки до и после обмена. В процессе обмена меняются привязки к ссылкам; сами объекты остаются на том же месте
в корне отличается от семантики значения (например, int), в случае которого нет никаких косвенных изменений или привязок: каждое имя прочно закреплено за значением, которым манипулируют с помощью этого идентификатора.
Ссылка, не привязанная к какому-либо объекту, – это «пустая» ссылка (null). При инициализации по умолчанию с помощью свойства .init ссылки на классы получают значение null. Можно сравнивать ссылку с константой null и присваивать ссылке значение null. Следующие проверки пройдут успешно:
unittest
{
A a;
assert(a is null);
a = new A;
assert(a !is null);
a = null;
assert(a is null);
a = A.init;
assert(a is null);
}
Обращение к элементу непривязанной («пустой», null) ссылки ведет к аппаратной ошибке, экстренно останавливающей приложение (или на некоторых системах и при некоторых обстоятельствах запускающей отладчик). Если вы попытаетесь осуществить доступ к нестатическому элементу ссылки и компилятор может статически доказать, что эта ссылка в любом случае в этот момент окажется пустой, он откажется компилировать код.
A a;
a.x = 5; // Ошибка! Ссылка a пуста!
Иногда компилятор ведет себя сдержанно, стараясь не слишком надоедать вам: если ссылка только может быть пустой (но не всегда будет таковой), коду дается «зеленый свет» и все разговоры об ошибках откладываются до времени исполнения программы. Например:
A a;
if (‹условие›)
{
a = new A;
}
...
if (‹условие›)
{
a.x = 43; // Все в порядке
}
Компилятор «пропускает» такой код, даже несмотря на то, что между двумя вычислениями ‹условие› может изменить значение. В общем случае было бы непросто проверить, насколько корректна инициализация объекта, так что компилятор решает, что вы сами знаете, что делаете (кроме самых простых случаев, когда он уверен, что вы пытаетесь использовать пустую ссылку неподобающим образом).
В языке D применяется такой же основанный на ссылочной семантике подход к обработке объектов классов, как и во многих других объектно-ориентированных языках. Использование для объектов классов ссылочной семантики и сбора мусора имеют как положительные, так и отрицательные следствия, включая следующие:
- Полиморфизм. Уровень косвенности, достигаемый благодаря последовательному использованию ссылок, делает возможной поддержку полиморфизма. Все ссылки обладают одинаковым размером, а ассоциированные с ними объекты могут иметь разные размеры, даже если имеют якобы один и тот же тип (что осуществляется через наследование, о котором речь пойдет очень скоро). Поскольку ссылки обладают одним и тем же размером независимо от размера объектов, на которые они ссылаются, вы всегда можете использовать вместо ссылок на объекты классов-потомков ссылки на объекты родительских классов. Кроме того, как следует работают массивы объектов – даже когда объекты в массиве обладают разными размерами. Если вы имели дело с C++, вам, конечно же, известно о необходимости использования указателей для организации полиморфизма и о разнообразных летальных проблемах, с которыми сталкивается программист, если забывает об этом.
- Безопасность. Многие воспринимают сбор мусора только как удобное средство, которое облегчает процесс кодирования, освобождая программиста от обязанности управлять памятью. Возможно, это прозвучит неожиданно, но модель вечной жизни (которая воплощается благодаря сбору мусора) и безопасность памяти прочно связаны. Там, где жизнь вечна, нет «висячих» ссылок, то есть ссылок на некоторый переставший существовать объект, память которого была заново использована – отдана в распоряжение совершенно постороннего объекта. Заметим, что той же степени безопасности можно добиться, везде используя семантику значения (команда
auto a2 = a1дублирует экземпляр классаA, на который ссылаетсяa1, и привязываетa2к копии). Такой подход, однако, вряд ли интересен, поскольку лишает возможности создавать какие-либо ссылочные структуры данных (такие как списки, графы и вообще любые разделяемые ресурсы). – Цена выделения памяти. В общем случае классы должны располагаться в куче, подлежащей сбору мусора, что обычно медленнее работает и съедает больше памяти, чем при размещении в стеке. В последнее время разница сильно уменьшилась, но она все же есть. – Связанность идентификаторов, определенных далеко друг от друга. Основной риск при использовании ссылок – неумеренное порождение псевдонимов. При повсеместном применении ссылочной семантики очень просто получить ссылки на один и тот же объект в разных – и самых неожиданных – местах. Переменныеa1иa2на рис. 6.1 могут находиться сколь угодно далеко друг от друга, т. к. по логике приложения кроме них у того же объекта может быть множество других, висячих ссылок. Любопытно, но если объект неизменяем, проблема исчезает: пока никто не изменяет объект, нет и связанности. Сложности возникают, когда некоторое изменение, имевшее место в некотором контексте, неожиданно и драматично повлияет на состояние (как это видится из другой части приложения). Один из способов улучшить такое положение дел заключается в постоянном явном дублировании, которое обычно осуществляется с помощью специального методаclone. Минусы этой техники: она зависит от дисциплинированности человека, и такой образ действий может снизить скорость работы приложения, если некоторые его части решат консервативно клонировать объекты из принципа «как бы чего не вышло».
Сравним ссылочную семантику с семантикой значений а-ля int. У семантики значений есть свои преимущества, среди которых выделяется логический вывод: в выражениях всегда можно заменять равные значения друг на друга, при этом результат не изменяется. (А к ссылкам, использующим для изменения состояния объектов вызовы методов, такой подход неприменим.) Другое важное преимущество семантики значений – скорость. Но даже если вы воспользуетесь динамической щедростью полиморфизма, от ссылочной семантики никуда не деться. Некоторые языки пытались предоставить возможность использовать и ту, и другую семантику и заслужили прозвище «нечистых» (в противоположность чисто объектно-ориентированным языкам, использующим ссылочную семантику унифицированно для всех типов). D нечист и очень гордится этим. Во время разработки необходимо принять решение: если вы желаете работать с некоторым типом в рамках объектно-ориентированной парадигмы, следует выбрать тип class; иначе придется использовать тип struct и поступиться всеми удобствами ООП, присущими ссылочной семантике.
-
Язык D также предоставляет возможность «ручного» управления памятью (manual memory management) и на данный момент позволяет принудительно уничтожать объекты с помощью оператора delete:
delete obj;, при этом значение ссылкиobjбудет установлено вnull(см. ниже), а память, выделенная под объект, будет освобождена. Еслиobjуже содержитnull, ничего не произойдет. Однако следует соблюдать осторожность: повторное уничтожение одного объекта или обращение к удаленному объекту по другой ссылке приведет к катастрофическим последствиям (сбои и порча данных в памяти, источники которых порой очень трудно обнаружить), и эта опасность усугубляет необходимость в сборщике мусора. Из-за этих рисков операторdeleteпланируют убрать из самого языка, оставив в виде функции в стандартной библиотеке. Но при этом ручное управление памятью позволяет более эффективно ее использовать. Вердикт: задействуйте эту возможность, если уверены, что на момент вызоваdeleteобъектobjточно не удален иobj– последняя ссылка на данный объект, и не удивляйтесь, если в один прекрасный деньdeleteисчезнет из реализаций языка. – Прим. науч. ред. ↩︎