| .. | ||
| images | ||
| README.md | ||
4. Массивы, ассоциативные массивы и строки
- 4.1. Динамические массивы
- 4.2. Массивы фиксированной длины
- 4.3. Многомерные массивы
- 4.4. Ассоциативные массивы
- 4.5. Строки
- 4.6. Опасный собрат массива – указатель
- 4.7. Итоги и справочник
Предыдущие главы лишь косвенно знакомили нас с массивами, ассоциативными массивами и строками (тут выражение, там литерал), пора уже познакомиться с ними по-настоящему. Оперируя только этими тремя типами данных, можно написать много хорошего кода, так что теперь, когда в нашем арсенале уже есть выражения и инструкции, самое время побольше узнать о массивах, ассоциативных массивах и строках.
4.1. Динамические массивы
Язык D предлагает очень простую, но гибкую абстракцию массивов. Для типа T справедливо, что T[] – это тип, представляющий собой непрерывную область памяти, содержащую элементы типа T. В терминах D T[] – это «массив значений типа T», или просто «массив значений T».
Динамический массив создается с помощью выражения new (см. раздел 2.3.6.1):
int[] array = new int[20]; // Создать массив для 20 целых чисел
Более простой и удобный вариант:
auto array = new int[20]; // Создать массив для 20 целых чисел
Все элементы только что созданного массива типа T[] инициализируются значением T.init (для целых чисел это 0). После того как массив создан, для доступа к его элементам служит индексирующее выражение array[n]:
auto array = new int[20];
auto x = array[5]; // Корректны индексы от 0 до 19
assert(x == 0); // Начальное значение для всех элементов массива: int.init = 0
array[7] = 42; // Элементам массива можно присваивать значения
assert(array[7] == 42);
Число элементов, заданное в выражении new, не обязательно константа. Например, следующая программа создает массив случайной длины и заполняет его случайными числами, для генерации которых вызывает функцию uniform из модуля std.random:
import std.random;
void main()
{
// От 1 до 127 элементов
auto array = new double[uniform(1, 128)];
foreach (i; 0 .. array.length)
{
array[i] = uniform(0.0, 1.0);
}
...
}
Цикл foreach можно переписать, чтобы обращаться непосредственно к каждому элементу массива, не используя индексы (см. раздел 3.7.5):
foreach (ref element; array)
{
element = uniform(0.0, 1.0);
}
Ключевое слово ref сообщает компилятору, что в нашем коде присваивания элементу element должны отражаться в исходном массиве. Иначе значения присваивались бы только копиям элементов массива.
Можно инициализировать массив особыми значениями (отличными от значений по умолчанию) с помощью литерала массива:
auto somePrimes = [ 2, 3, 5, 7, 11, 13, 17 ];
Еще один способ создать массив – дублировать существующий массив. При обращении к свойству .dup массива создается поэлементная копия этого массива:
auto array = new int[100];
...
auto copy = array.dup;
assert(array !is copy); // Это разные массивы,
assert(array == copy); // но с одинаковым содержимым
Наконец, если вы просто определите переменную типа T[], не инициализируя ее или инициализируя значением null, то получите «пустой массив» (null array). Пустой массив не имеет элементов, проверка на равенство такого массива константе null возвращает true.
string[] a; // То же, что string[] a = null
assert(a is null);
assert(a == null); // То же, что выше
a = new string[2];
assert(a !is null);
a = a[0 .. 0];
assert(a !is null);
Благодаря последней строке этого кода обнаруживается нечто странное: пустой массив – это необязательно null.
4.1.1. Длина
Динамические массивы всегда «помнят» свою длину. Доступ к этому значению предоставляет свойство .length массива:
auto array = new short[55];
assert(array.length == 55);
Выражение array.length часто используется внутри индексирующего выражения для массива array. Например, обратиться к последнему элементу массива array можно с помощью выражения array[array.length - 1]. Чтобы упростить подобную запись, было разрешено внутри индексирующих выражений обозначать длину индексируемого массива идентификатором $.
auto array = new int[10];
array[9] = 42;
assert(array[$ - 1] == 42);
Изменение длины массива обсуждается в разделах 4.1.8–4.1.10.
4.1.2. Проверка границ
Что произойдет, если выполнить следующий код?
auto array = new int[10];
auto invalid = array[100];
Учитывая, что массивы всегда знают свою длину, можно легко вставить соответствующие проверки, так что вопрос о выполнимости задачи не стоит. Все дело в том, что проверка границ – это одна из тех вещей, которые ставят программиста перед мучительным выбором между быстродействием и безопасностью.
По соображениям безопасности необходимо постоянно проверять каким-либо способом корректность обращений к массиву. Доступ к памяти за пределами массива может привести к неконтролируемому поведению программы, сделать ее уязвимой для эксплойтов, вызывать сбои.
В то же время при текущей технологии компилирования полная проверка границ все еще сильно влияет на быстродействие. Эффективная проверка границ – тема для серьезного исследования. Популярный подход состоит в том, что сначала расставляют проверки везде, где выполняется обращение к массиву, а затем убирают те из них, которые статический анализатор сочтет излишними. Обычно этот процесс быстро усложняется, особенно в тех случаях, когда при использовании массивов пересекаются границы процедур и модулей. Применяемые сегодня методы проверки границ требуют длительного анализа даже для скромных программ и позволяют избавиться лишь от части ненужных проверок.
В отношении головоломки с проверкой границ D находится между двух огней. Язык пытается одновременно предоставить как безопасность и удобство, свойственные современным языкам, так и предельное, ничем не ограниченное быстродействие, желательное для языка системного уровня. Проблема проверки границ подразумевает выбор между этими двумя крайностями, и D позволяет сделать этот выбор вам самим, вместо того чтобы сделать его за вас.
Во время компиляции D дважды делает выбор:
- между безопасным и системным модулями (см. раздел 11.2.2);
- между промежуточной (non-release) и итоговой (release) сборками (см. раздел 10.6).
D различает «безопасные» (safe) и «системные» (system) модули. Средний уровень безопасности – «доверенный» (trusted). Подразумеваются модули, которые предоставляют безопасный интерфейс, но могут осуществлять доступ системного уровня в рамках своей реализации. Выбор уровня доверенности написанных вами модулей – за вами. Во время компиляции безопасного модуля компилятор статически отключает все средства языка (включая непроверенную индексацию массивов), которые могут вызвать некорректный доступ к памяти. Компилируя системный или доверенный модуль, компилятор разрешает необработанный, непроверенный доступ к аппаратному обеспечению. Вы можете задать уровень определенной части модуля (безопасный, системный или доверенный), воспользовавшись специальной опцией командной строки или вставив атрибут:
@safe;
или
@trusted;
или
@system;
Выбранный уровень безопасности «действует» начиная с точки вставки соответствующего атрибута до следующей точки вставки или до конца файла (если больше нет вставленных атрибутов).
Механизм безопасности модулей подробно описан в главе 11, а сейчас главное из всей этой информации то, что вы как разработчик можете выбрать для своего модуля атрибут @safe, @trusted или @system.
Решение о выполнении итоговой сборки вашего приложения принимается независимо от безопасности модулей. Указать компилятору D собрать итоговую версию программы можно с помощью флага командной строки (-release в эталонной реализации). Для безопасного модуля границы проверяются всегда. Для системного модуля проверки границ вставляются только при промежуточной (не итоговой) сборке. При промежуточной сборке также вставляются и другие проверки, такие как выражения assert и проверки контрактов (последствия выбора итоговой сборки подробно обсуждаются в главе 10). Взаимосвязь между степенью безопасности модуля (безопасный/системный модуль) и режимом сборки (итоговая/промежуточная сборка) отражена в табл. 4.1.
Таблица 4.1. Проверка границ в зависимости от вида модуля и режима сборки
| Безопасный модуль | Системный модуль | |
|---|---|---|
| Промежуточная сборка | ✓ | ✓ |
Итоговая сборка (флаг -release для компилятора dmd) |
✓ | ☠ |
Вас предупредили.
4.1.3. Срезы
Срезы – это мощное средство, позволяющее выбирать и использовать непрерывный фрагмент массива. Например, можно напечатать только вторую половину массива:
import std.stdio;
void main()
{
auto array = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9];
// Напечатать только вторую половину
writeln(array[$ / 2 .. $]);
}
Эта программа напечатает:
5 6 7 8 9
Чтобы получить срез массива array, используйте форму записи array[m .. n] для выбора части массива, которая начинается элементом с индексом m и заканчивается элементом с индексом n-1 (включая и этот элемент). Срез имеет тот же тип, что и сам массив, поэтому, например, можно присвоить срез тому же массиву, с которого сделан этот срез:
array = array[$ / 2 .. $];
В выражениях, обозначающих начало и конец среза, может участвовать идентификатор $, как и в случае обычной индексации, обозначающий длину массива, срез которого требуется получить. Если m и n равны, это не является ошибкой: результатом в этом случае будет пустой срез. Нельзя задать m > n или n > array.length. Проверка таких «незаконных случаев» выполняется в соответствии с порядком, описанным в разделе 4.1.2.
Выражение array[0 .. $] получает срез, включающий все содержимое массива array. Это выражение встречается довольно часто, и тут язык помогает программистам, позволяя вместо записи array[0 .. $] использовать краткую форму array[].
4.1.4. Копирование
Объект массива содержит (или может почти мгновенно вычислить) как минимум два ключевых значения – верхнюю и нижнюю границы своих данных. Например, после выполнения кода
auto a = [1, 5, 2, 3, 6];
объект a окажется в состоянии, показанном на рис. 4.1. Массив «видит» только область, заключенную между его границами; заштрихованная область ему недоступна.
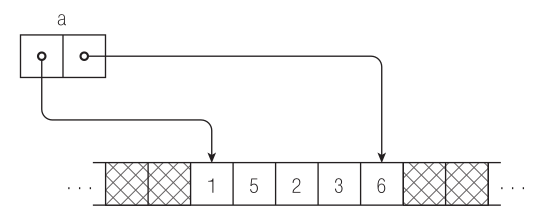
Рис. 4.1. Объект массива ссылается на область памяти, содержащую пять элементов
(Возможны и другие формы внутреннего представления массива, например, хранение адреса первого элемента и размера занимаемой области памяти или адреса первого элемента и адреса элемента, следующего за последним элементом. Тем не менее все представления в итоге предоставляют доступ к одной и той же существенной информации.)
Инициализация массива другим массивом (auto b = a), равно как и присваивание одного массива другому (int[] b; … b = a;) не влечет скрытого автоматического копирования данных. Как показано на рис. 4.2, эти действия просто заставляют b ссылаться на ту же область памяти, что и a.
Более того, получение среза массива b сокращает область памяти, «видимую» b, также без всякого копирования b. При условии что исходное состояние массива задано на рис. 4.2, выполнение инструкции
b = b[1 .. $ - 2];
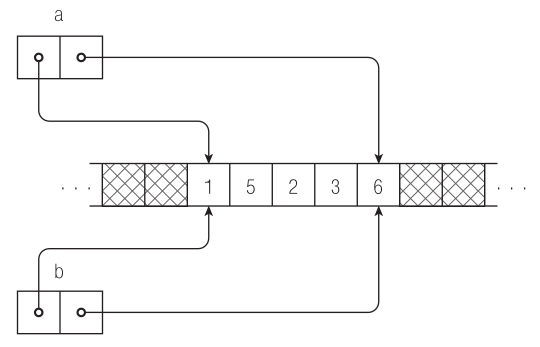
Рис. 4.2. При выполнении инструкции auto b = a; содержимое a не копируется: вместо этого создается объект типа «массив», который ссылается на те же данные
приведет лишь к сокращению диапазона, доступного b, без какого-либо копирования данных (рис. 4.3).
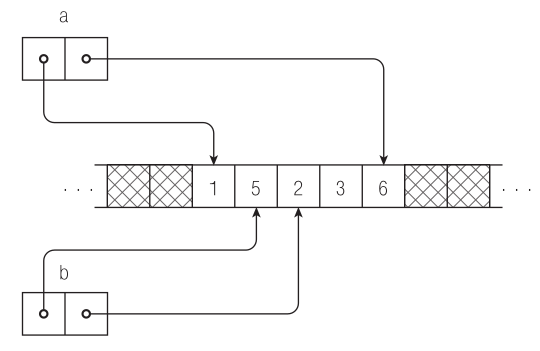
Рис. 4.3. Выполнение инструкции b = b[1 .. $ - 2]; ведет к сужению области памяти, управляемой переменной b, при этом выбранный срез не копируется
Прямым следствием совместного использования (разделения) данных, проиллюстрированного рис. 4.2 и 4.3, является то, что изменение элемента одного массива может отразиться и на других массивах:
int[] array = [0, 1, 2];
int[] subarray = array[1 .. $];
assert(subarray.length == 2);
subarray[1] = 33;
assert(array[2] == 33); // Изменение массива subarray отразилось на массиве array
4.1.5. Проверка на равенство
Выражение a is b (см. раздел 2.3.4.3) сравнивает границы двух массивов на равенство и возвращает true, если и только если a и b привязаны в точности к одной и той же области памяти. Никакая проверка содержимого массивов не производится.
Для поэлементной проверки на равенство массивов a и b служит операция вида a == b или противоположная ей a != b (см. раздел 2.3.12).
auto a = ["hello", "world"];
auto b = a;
assert(a is b); // Тест пройден, у a и b одни те же границы
assert(a == b); // Естественно, тест пройден
b = a.dup;
assert(a == b); // Тест пройден, a и b равны, хотя занимают разные области памяти
assert(a !is b); // Тест пройден, a и b различны, хотя имеют одинаковое содержимое
При поэлементном сравнении массивов просматриваются все элементы обоих массивов и соответствующие пары сравниваются по очереди с помощью оператора ==.
4.1.6. Конкатенация
Конструкция
содержимое1 ~ содержимое2
представляет собой выражение конкатенации. Результатом конкатенации является новый массив, содержимое которого представляет собой содержимое1, за которым следует содержимое2. Операндами в выражении конкатенации могут быть: два массива (типы T[] и T[]), массив и значение (типы T[] и T), значение и массив (типы T и T[]).
int[] a = [0, 10, 20];
int[] b = a ~ 42;
assert(b == [0, 10, 20, 42]);
a = b ~ a ~ 15;
assert(a.length == 8);
Под результирующий массив всегда выделяется новая область памяти.
4.1.7. Поэлементные операции
Некоторые операции применяются к массиву в целом, без явного указания на элементы массива. Чтобы применить поэлементную операцию, в выражении рядом с каждым срезом (в том числе слева от оператора присваивания) укажите [] или [m .. n], как здесь:
auto a = [ 0.5, -0.5, 1.5, 2 ];
auto b = [ 3.5, 5.5, 4.5, -1 ];
auto c = new double[4]; // Память под массив должна быть уже выделена
c[] = (a[] + b[]) / 2; // Рассчитать среднее арифметическое a и b
assert(c == [ 2.0, 2.5, 3.0, 0.5 ]);
В поэлементной операции могут участвовать:
- простое значение, например
5; - срез, явно указанный с помощью
[]или[m .. n], напримерa[]илиa[1 .. $ - 1]; - любое корректное выражение на D с участием сущностей, определенных в двух предыдущих пунктах, унарных операторов
-и~, а также бинарных операторов+,-,*,/,%,^^,^,&,|,=,+=,-=,*=,/=,%=,^=,&=и|=.
Поэлементная операция равносильна циклу, в котором поочередно каждому элементу массива, указанного слева от оператора присваивания, присваивается результат операции над элементами массивов с тем же индексом, расположенной справа от оператора присваивания. Например, присваивание
auto a = [1.0, 2.5, 3.6];
auto b = [4.5, 5.5, 1.4];
auto c = new double[3];
c[] += 4 * a[] + b[];
равносильно циклу
foreach (i; 0 .. c.length)
{
c[i] += 4 * a[i] + b[i];
}
Проверка границ выполняется в соответствии с порядком, описанным в разделе 4.1.2.
Используя явно заданные срезы (заканчивающиеся парой скобок [] или обозначением диапазона [m .. n]), числа и допустимые операторы, с помощью круглых скобок можно создавать выражения любой глубины и сложности, например:
double[] a, b, c;
double d;
...
a[] = -(b[] * (c[] + 4)) + c[] * d;
Из поэлементных операций чаще всего применяются простое заполнение ячеек (элементов) массива содержимым и их копирование:
int[] a = new int[128];
int[] b = new int[128];
...
b[] = -1; // Заполнить все ячейки b значением -1
a[] = b[]; // Скопировать все данные из b в a
Предупреждение
Поэлементные операции очень мощны, а чем больше мощность, тем больше ответственность. Именно вы отвечаете за отсутствие перекрывания между l- и r-значениями каждого присваивания в поэлементной операции. Приводя высокоуровневые операции к примитивным операциям над векторами, которые может выполнять конечный процессор (на котором будет исполняться программа), компилятор вправе считать, что это именно так. Если вы намеренно используете перекрывание, то напишите циклы обработки элементов массива вручную, чтобы компилятор не смог выполнить какие-то непроверенные присваивания.
4.1.8. Сужение
Сужение массива означает, что массив должен «забыть» о некотором количестве своих начальных или конечных элементов без перемещения остальных. Ограничение на перемещение очень важно; если бы оно не было обязательным, массивы было бы легко сужать, просто создавая новую копию с теми элементами, которые требуется оставить.
Тем не менее сузить массив очень просто: нужно просто присвоить массиву срез его самого:
auto array = [0, 2, 4, 6, 8, 10];
array = array[0 .. $ - 2]; // Сужение справа на два элемента
assert(array == [0, 2, 4, 6]);
array = array[1 .. $]; // Сужение слева на один элемент
assert(array == [2, 4, 6]);
array = array[1 .. $ - 1]; // Сужение с обеих сторон
assert(array == [4]);
Все операции сужения выполняются за одно и то же время, которое не зависит от длины массива (практически они состоят из пары присваиваний с операндами-словами). Технически простое сужение массива с обоих концов – очень полезное средство языка D. (Другие языки позволяют легко сужать массивы справа, но не слева, поскольку такая операция повлекла бы перемещение всех элементов массива, чтобы сохранить положение левой границы массива.) В языке D вы можете получить копию массива и последовательно сужать ее, постоянно обрабатывая элементы в начале и в конце массива, в полной уверенности, что операции сужения, выполняемые за фиксированное время, не нанесут ощутимого ущерба быстродействию программы.
Напишем для примера маленькую программу, определяющую, является ли массив, переданный в командной строке, палиндромом. Массив-палиндром симметричен относительно своей середины, то есть [5, 17, 8, 17, 5] – это палиндром, а [5, 7, 8, 7] – нет. Для решения этой задачи нам потребуются несколько помощников. Сначала нужно извлечь аргументы командной строки в массив значений типа string. Эту задачу любезно возьмет на себя функция main, если определить ее как main(string[] args). Затем нужно преобразовать эти значения типа string в значения типа int, для чего мы воспользуемся функцией с говорящим именем to из модуля std.conv. Результат вычисления выражения to!int(str) – распознанное в строке str значение типа int. Все это помогает нам написать программу, которая проверяет, является ли введенный массив палиндромом:
import std.conv, std.stdio;
int main(string[] args)
{
// Избавиться от имени программы
args = args[1 .. $];
while (args.length >= 2)
{
if (to!int(args[0]) != to!int(args[$ - 1]))
{
writeln("не палиндром");
return 1;
}
args = args[1 .. $ - 1];
}
writeln("палиндром");
return 0;
}
Сначала программе нужно удалить свое имя из списка аргументов, формат которого соответствует традициям языка C. Если вызвать нашу программу (назовем ее palindrome) следующим образом:
palindrome 34 95 548
то содержимое массива args примет вид ["palindrome", "34", "95", "548"]. Вот где пригодилось сужение слева args = args[1 .. $]: оно сокращает массив args до массива ["34", "95", "548"]. Затем программа пошагово сравнивает элементы на концах массива. Если они не равны, то дальше можно не сравнивать: пишем "не палиндром" и закругляемся. А если проверка прошла успешно, то сужаем массив args с обоих концов. Только если все проверки возвратят true, а в массиве args останется не больше одного элемента (пустые массивы и массивы из одного элемента программа считает палиндромами), программа напечатает "палиндром" и завершится. Несмотря на то что программа активно манипулирует массивами, после инициализации массива args память не перераспределялась ни разу. Работа начинается c обращения к массиву args (память под который была выделена заранее), а потом он только сужается.
4.1.9. Расширение
Перейдем к расширению массивов. Расширить массив позволяет оператор присоединения ~=, например:
auto a = [87, 40, 10];
a ~= 42;
assert(a == [87, 40, 10, 42]);
a ~= [5, 17];
assert(a == [87, 40, 10, 42, 5, 17]);
У расширения массивов есть пара тонких моментов, связанных с перераспределением памяти. Рассмотрим код:
auto a = [87, 40, 10, 2];
auto b = a; // Теперь a и b ссылаются на одну и ту же область памяти
a ~= [5, 17]; // Присоединить к a
a[0] = 15; // Изменить a[0]
assert(b[0] == 15); // Будет ли пройден тест?
Повлияет ли выполненное после присоединения присваивание элементу a[0] на b[0]? Другими словами, будут ли a и b разделять данные после перераспределения памяти? Коротко на этот вопрос можно ответить так: b[0] может содержать 15, а может и не содержать – язык не дает никаких гарантий.
Реальность такова, что в конце массива a не всегда достаточно места, чтобы перераспределить память под измененный массив в том же месте. Иногда перенос массива в другую область памяти бывает неизбежен. Проще всего добиться корректного поведения программы в подобных случаях, всегда перераспределяя память под массив a после присоединения к нему новых элементов с помощью оператора ~=, то есть делая операцию a ~= b тождественной операции a = a ~ b, что означает: «Определить в новой области памяти массив, содержащий последовательность элементов массива a, к которой присоединена последовательность элементов массива b, и связать переменную a с полученным новым массивом». Такое поведение проще всего реализуется, но наносит серьезный урон быстродействию. Приведем пример. Обычно содержимое массивов пошагово наращивают в цикле:
int[] a;
foreach (i; 0 .. 100)
{
a ~= i;
}
При 100 элементах приемлема любая стратегия расширения и неважно, какой вариант будет выбран, но с ростом массивов только жесткие решения останутся относительно быстрыми. Не очень привлекательный подход состоит в том, чтобы разрешить удобный, но неэффективный синтаксис расширения a ~= b и применять его только с короткими массивами, а для длинных массивов использовать другой, менее удобный синтаксис. Маловероятно, что самый простой и интуитивно понятный синтаксис сработает как с короткими, так и с длинными массивами.
D оставляет оператору ~= свободу перераспределять память по своему усмотрению: он может выполнять расширение с переносом массива в новую область памяти, но старается оставить его на «старом месте», если после массива достаточно свободной памяти для размещения новых элементов. Выбор в пользу той или иной альтернативы определяется исключительно реализацией ~=, но с той гарантией, что программа, выполняющая много присоединений к одному и тому же массиву, будет обладать хорошим средним быстродействием.
На рис. 4.4 показаны два возможных исхода расширения a ~= [5, 17].
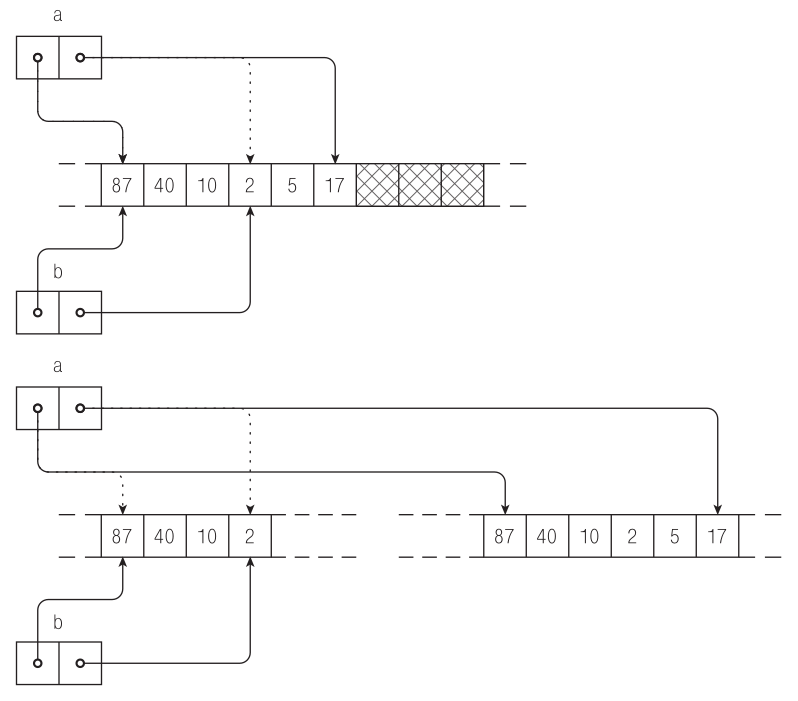
Рис. 4.4. Два возможных исхода попытки расширить массив a
В зависимости от того, как работает низкоуровневый менеджер памяти, массив может расширяться разными способами:
- Обычно менеджеры памяти выделяют память только фиксированными блоками (то есть блоками размера, кратного 2). Поэтому возможно, что при запросе 700 байт будет выделено 1024 байта памяти, из которых 324 будут пустовать. Получив запрос на расширение, массив может проверить, нет ли такой незанятой памяти, и использовать ее.
- Если собственной незанятой памяти не осталось, массив может затеять более сложные переговоры с низкоуровневым менеджером памяти: «Послушай, мне бы немного памяти на благое дело. Нет ли случайно рядом со мной свободного блока?» Если менеджер памяти обнаружит незанятый блок справа от текущего блока массива, то объединит их. Такая операция называется слиянием (coalescing). После этого расширение может продолжаться без перемещения каких-либо данных.
- Наконец, если справа от текущего блока совсем нет места, менеджер памяти выделяет новый блок памяти, и все содержимое массива копируется туда. Реализация менеджера памяти может принудительно резервировать дополнительную область памяти, например, обнаружив повторяющиеся расширения одного и того же массива.
Расширяющийся массив никогда не «наступит» на существующий массив. Например:
int[] a = [0, 10, 20, 30, 40, 50, 60, 70];
auto b = a[4 .. $];
a = a[0 .. 4];
// Сейчас a и b примыкают друг к другу
a ~= [0, 0, 0, 0];
assert(b == [40, 50, 60, 70]); // Тест пройден; массив a был перенесен в новую область памяти
Этот код искусно заставляет массив a думать, что в конце области памяти, которую он занимает, есть свободное место: первоначально массив a был больше по размеру, затем массив b занял вторую половину массива a, а сам массив a сузился до своей первой половины. Перед добавлением новых элементов в массив a массивы a и b занимали соседние области памяти: массив a находился слева от массива b. Однако успешное выполнение теста assert после добавления новых элементов в массив a подтвердило, что этот массив был перенесен в другую область памяти, а не расширился на том же месте. Оператор расширения добавляет в массив элементы без изменения адреса массива, только если уверен, что справа от расширяющегося массива нет другого массива, и при малейшем сомнении всегда готов подстраховаться, перераспределив память.
4.1.10. Присваивание значения свойству .length
Присвоив значение свойству .length массива, вы можете сузить или расширить его, в зависимости от отношения новой длины к старой. Например:
int[] array;
assert(array.length == 0);
array.length = 1000; // Расширяется
assert(array.length == 1000);
array.length = 500; // Сужается
assert(array.length == 500);
Если массив расширяется в результате присваивания свойству .length, добавленные элементы инициализируются значением T.init. Стратегия расширения и гарантии идентичности в этом случае аналогичны добавлению элементов с помощью оператора ~= (см. раздел 4.1.9).
Если массив сжимается в результате присваивания свойству .length, D гарантирует, что массив не будет перемещен. Практически, если n <= a.length, a.length = n эквивалентно a = a[0 .. n]. (Однако нет гарантии, что массив не будет перемещен в результате последующих расширений.)
Можно одновременно выполнить чтение, изменение и запись значения свойства .length следующим способом:
auto array = new int[10];
array.length += 1000; // Расширяется
assert(array.length == 1010);
array.length /= 10; // Сужается
assert(array.length == 101);
Здесь нет никакой магии; все, что необходимо сделать компилятору, – это переписать выражение array.length ‹о›= b в несколько иной форме: array.length = array.length ‹о› b. И все-таки немного магии тут есть (на самом деле, всего лишь ловкость рук): в переписанном выражении массив вычисляется всего лишь раз, что очень кстати, если реально array – это какое-то замысловатое выражение.
4.2. Массивы фиксированной длины
D также позволяет создать массив, длина которого известна во время компиляции. Пример объявления такого массива:
int[128] someInts;
Каждое сочетание типа T и размера n представляет собой уникальный тип T[n]: например, тип uint[10] отличается от типа uint[11], равно как и от типа int[10].
Память под все массивы фиксированной длины выделяется статически, в месте их объявления. Если значение массива определено глобально, память под него выделяется в сегменте данных программы, индивидуальном для каждого потока. Если же массив определяется внутри функции, он будет размещен в стеке этой функции при ее вызове. (Это означает, что определять слишком большие массивы внутри функций довольно опасно.) Однако если задать массив внутри функции с ключевым словом static, он займет блок памяти в сегменте данных потока, так что в этом случае риска переполнения стека нет.
При создании массива фиксированной длины типа T[n] все его элементы инициализируются значением T.init. Например:
int[3] a;
assert(a == [0, 0, 0]);
Также можно инициализировать массив типа T[n] с помощью литерала:
int[3] a = [1, 2, 3];
assert(a == [1, 2, 3]);
Но будьте осторожны: если в объявлении типа заменить int[3] ключевым словом auto, то по принятым в D правилам определения типов массиву a будет присвоен тип int[], а не int[3]. Несмотря на то что кажется логичным выбрать тип int[3], в некотором смысле более «точный», чем int[], на практике динамические массивы используются гораздо чаще массивов фиксированной длины, поэтому трактовка литералов массивов как массивов фиксированной длины отрицательно сказалась бы на удобстве языка, став источником многих неприятных сюрпризов. Кроме того, такое толкование литералов свело бы на нет смысл использования ключевого слова auto с массивами. Поэтому значениям, задаваемым литералом, T[] присваивается по умолчанию, а T[n] – если вы просите присвоить этот конкретный тип и при этом n соответствует числу значений в литерале (как в коде выше).
Если вы инициализируете массив фиксированной длины типа T[n] с помощью единственного значения типа T, все ячейки массива будут заполнены этим значением.
int[4] a = -1;
assert(a == [-1, -1, -1, -1]);
Если вы планируете оставить массив неинициализированным и заполнить его во время исполнения программы, просто укажите в качестве инициализирующего значения ключевое слово void:
int[1024] a = void;
Возможность выделять память под массив, не инициализируя ее, особенно полезна, когда требуется задать большой массив под временный буфер. Будьте осторожны: неинициализированное целое число, скорее всего, никому особо не навредит, а вот неинициализированные значения ссылочных типов (таких как многомерные массивы) небезопасны. Доступ к элементам массива фиксированной длины осуществляется по индексу a[i], как и к элементам динамических массивов. Просмотр массива фиксированной длины также практически идентичен просмотру динамического массива. Например, так создается массив, содержащий 1024 случайных числа:
import std.random;
void main()
{
double[1024] array;
foreach (i; 0 .. array.length)
{
array[i] = uniform(0.0, 1.0);
}
...
}
В цикле можно не использовать индекс, осуществляя доступ к элементу массива по ссылке:
foreach (ref element; array)
{
element = uniform(0.0, 1.0);
}
4.2.1. Длина
Очевидно, что массив фиксированной длины знает свой размер, потому что он «прошит» в его типе. В отличие от длины динамических массивов, свойство .length массива фиксированной длины неизменяемо и является статической константой. Это означает, что вы можете использовать это свойство везде, где требуется значение, известное во время компиляции, например, в качестве размера другого массива фиксированной длины при его определении1:
int[100] quadrupeds;
int[4 * quadrupeds.length] legs; // Все в порядке, 400 ног
В индексирующем выражении массива а вместо записи a.length можно использовать идентификатор $, и значение этого выражения также будет известно во время компиляции.
4.2.2. Проверка границ
Проверка границ массивов фиксированной длины имеет интересную особенность. Если индексирование осуществляется с помощью выражения, вычисляемого во время компиляции, компилятор всегда проверяет, корректно ли оно, и отказывается компилировать программу, если обнаруживает попытку доступа к памяти за пределами массива. Например:
int[10] array;
array[15] = 5; // Ошибка! Индекс 15 находится за пределами a[0 .. 10]!
Однако если индексирующее выражение вычисляется в процессе исполнения программы, проверка границ во время компиляции осуществляется настолько, насколько это возможно, а проверка границ во время исполнения программы делается по тем же правилам, что и проверка границ динамических массивов (см. раздел 4.1.2).
4.2.3. Получение срезов
Получение среза массива типа T[n] порождает массив типа T[] без копирования данных:
int[5] array = [40, 30, 20, 10, 0];
auto slice1 = array[2 .. $]; // slice1 имеет тип int[]
assert(slice1 == [20, 10, 0]);
auto slice2 = array[]; // Такой же, как array[0 .. $]
assert(slice2 == array);
Проверка границ во время компиляции выполняется для одной из границ массива или для обеих границ, если они известны на этом этапе.
Если вы примените к массиву типа T[n] оператор среза, указав в качестве границ среза числа a1 и a2, известные во время компиляции, и при этом укажете, что должен быть возвращен массив типа T[a2 - a1], компилятор удовлетворит ваш запрос. (По умолчанию, то есть при наличии ключевого слова auto, возвращается тип среза T[].) Например:
int[10] a;
int[] b = a[1 .. 7]; // Все в порядке
auto c = a[1 .. 7]; // Все в порядке, c также имеет тип int[]
int[6] d = a[1 .. 7]; // Все в порядке, срез a[1 .. 7] скопирован в d
4.2.4. Копирование и неявные преобразования
В отличие от динамических массивов, массивы фиксированной длины копируются по значению. Это означает, что при копировании массива, передаче его внутрь функции в качестве аргументов и возврате из функции копируется весь массив. Например:
int[3] a = [1, 2, 3];
int[3] b = a;
a[1] = 42;
assert(b[1] == 2); // b – независимая копия a
int[3] fun(int[3] x, int[3] y)
{
// x и y – копии переданных аргументов
x[0] = y[0] = 100;
return x;
}
auto c = fun(a, b); // c имеет тип int[3]
assert(c == [100, 42, 3]);
assert(b == [1, 2, 3]); // Вызов fun никак на отразился на b
Передача целых массивов по значению может быть неэффективной в случае большого массива, но у такого способа много преимуществ. Одно из них в том, что короткие массивы и передача по значению часто используются в высокопроизводительных вычислениях. Другое – в том, что от передачи по значению есть простое средство: когда бы вы ни пожелали передать массив по ссылке, просто используйте ключевое слово ref или автоматическое приведение к типу T[] (см. следующий абзац). Наконец, передача по значению делает работу с массивами фиксированной длины более согласованной с другими аспектами языка. (Раньше в D массивы фиксированной длины копировались по ссылке, но при такой семантике копирования многие случаи требуют особой обработки, что нарушает логику пользовательского кода.)
Массив типа T[n] может быть неявно преобразован к типу T[]. Память под динамический массив, полученный таким способом, не выделяется заново: он просто привязывается к границам исходного массива. Поэтому преобразование считается небезопасным, если исходный массив расположен в стеке. Неявное преобразование типов облегчает передачу массивов фиксированной длины типа T[n] в функции, ожидающие значение типа T[]. Тем не менее, если функция возвращает значение типа T[n], результат ее вызова не может быть автоматически преобразован к типу T[].
double[3] point = [0, 0, 0];
double[] test = point; // Все в порядке
double[3] fun(double[] x)
{
double[3] result;
result[] = 2 * x[]; // Операция над массивом в целом
return result;
}
auto r = fun(point); // Все в порядке, теперь r имеет тип double[3]
Свойство .dup позволяет получить дубликат массива фиксированной длины (см. раздел 4.1), но вы получите не объект типа T[n], а динамически выделенный массив типа T[], содержащий копию массива фиксированной длины. Такое поведение оправданно, ведь чтобы получить копию статического массива а того же типа, не нужно прибегать ни к каким дополнительным ухищрениям – просто напишите auto copy = a.
4.2.5. Проверка на равенство
Массивы фиксированной длины можно проверять на равенство с помощью операторов is и ==, как и динамические массивы (см. раздел 4.1.5). Также можно смело использовать в проверках одновременно массивы обоих видов:
int[4] fixed = [1, 2, 3, 4];
auto anotherFixed = fixed;
assert(anotherFixed !is fixed); // Не то же самое (копирование по значению)
assert(anotherFixed == fixed); // Те же данные
auto dynamic = fixed[]; // Получает границы массива fixed
assert(dynamic is fixed);
assert(dynamic == fixed); // Естественно
dynamic = dynamic.dup; // Создает копию
assert(dynamic !is fixed);
assert(dynamic == fixed);
4.2.6. Конкатенация
Конкатенация выполняется по тем же правилам, что и для динамических массивов (см. раздел 4.1.6). Нужно лишь помнить важную деталь. Вы получите массив фиксированной длины, только если явно запросите массив фиксированной длины. Иначе вы получите заново выделен ный динамический массив. Например:
double[2] a;
double[] b = a ~ 0.5; // Присоединить к double[2] значение, получить double[]
auto c = a ~ 0.5; // То же самое
double[3] d = a ~ 1.5; // Все в порядке, явный запрос массива фиксированной длины
double[5] e = a ~ d; // Все в порядке, явный запрос массива фиксированной длины
Если в качестве результата конкатенации ~ явно указан массив фиксированной длины, никогда не происходит динамического выделения памяти: статически выделяется блок памяти, и результат конкатенации копируется в него.
4.2.7. Поэлементные операции
Поэлементные операции с массивами фиксированной длины работают так же, как и одноименные операции для динамических массивов (см. раздел 4.1.7). Компилятор всегда старается проверить корректность доступа к элементам массивов фиксированной длины в поэлементных выражениях.
4.3. Многомерные массивы
Поскольку запись T[] означает динамический массив элементов типа T, а T[], в свою очередь, – тоже тип, легко сделать вывод, что T[][] – это массив элементов типа T[], то есть массив массивов элементов типа T. Каждый элемент «внешнего» массива – это, в свою очередь, тоже массив, предоставляющий обычную функциональность, присущую массивам. Рассмотрим T[][] на практике:
auto array = new double[][5]; // Массив из пяти массивов, содержащих элементы типа double, первоначально каждый из них – null
// Сделать треугольную матрицу
foreach (i, ref e; array)
{
e = new double[array.length - i];
}
Здесь определен массив треугольной формы: первая строка содержит пять элементов типа double, вторая – четыре и так далее до последней строки (с номером 4), в которой всего один элемент. Многомерный массив, полученный простым составлением из динамических массивов, называют зубчатым массивом (jagged array), поскольку его строки могут иметь разную длину (в отличие от массива с ровным правым краем, содержащего строки одинаковой длины). На рис. 4.5 показано расположение массива array в памяти.
Чтобы получить доступ к элементу зубчатого массива, поочередно укажите индексы для каждого измерения, например array[3][1] – обращение ко второму элементу четвертой строки зубчатого массива.
Рис. 4.5. Зубчатый массив из примера, содержащий треугольную матрицу
Зубчатые массивы не являются непрерывными. Плюс этого свойства в том, что такой массив может быть рассредоточен по разным областям памяти и не требует слишком большого непрерывного блока. Кроме того, возможность хранить строки разной длины позволяет хорошо экономить память. Минусом же является то, что «высокий и худой» массив с большим числом строк и малым числом столбцов требует больших накладных расходов, поскольку для хранения содержимого каждого столбца требуется массив. Например, массив из 1 000 000 строк, в каждом из которых всего по 10 значений типа int, занимает 2 000 000 слов (одна строка – один массив) плюс дополнительные расходы на неиспользованную память при выделении 1 000 000 маленьких блоков, что, в зависимости от реализации менеджера памяти, может оказаться ощутимо гораздо больше затрат на хранение содержимого каждой строки (на каждые 10 целых чисел нужно всего по 40 байт).
При работе с зубчатыми массивами могут возникнуть проблемы со скоростью доступа и дружелюбностью кэша. Каждое обращение к элементам такого массива – это на самом деле два косвенных обращения: на первом шаге через внешний массив осуществляется доступ к нужной строке, а на втором – через внутренний массив – к столбцу. Построчный просмотр зубчатого массива – не проблема, если сначала получить строку, а потом ее использовать. Однако просмотр по столбцам – неиссякаемый источник кэш-промахов.
Если число столбцов известно во время компиляции, можно легко совместить массив фиксированной длины с динамическим массивом:
enum size_t columns = 128;
// Определить матрицу c 64 строками и 128 столбцами
auto matrix = new double[columns][64];
// Не нужно выделять память под каждую строку – они и так уже существуют
foreach (ref row; matrix)
{
... // Использовать строку типа double[columns]
}
В цикле из этого примера нужно обязательно использовать ключевое слово ref. Без него из-за передачи массива double[columns] по значению (см. раздел 4.2.4) создавалась бы копия каждой просматриваемой строки, что, скорее всего, отразилось бы на скорости выполнения кода.
Если во время компиляции известно число и строк, и столбцов многомерного массива, то можно использовать массив фиксированной длины массивов фиксированной длины, как в примере:
enum size_t rows = 64, columns = 128;
// Выделить память под матрицу с 64 строками и 128 столбцами
double[columns][rows] matrix;
// Вообще не нужно выделять память под массив – это значение
foreach (ref row; matrix)
{
... // Использовать строку типа double[columns]
}
Чтобы получить доступ к элементу в строке i и столбце j, напишите matrix[i][j]2. Немного странно, что в объявлении типа массива размеры измерений указаны «справа налево» (то есть double[столбцы][строки]), а при обращении к элементам массива индексы указываются «слева направо». Это объясняется тем, что [] и [n] в типах привязываются справа налево, а в выражениях – слева направо.
Сочетая массивы фиксированной длины с динамическими массивами, можно получать разнообразные многомерные массивы. Например, int[5][][15] – это трехмерный массив из 15 динамически размещаемых массивов, состоящих из блоков по 5 элементов типа int.
4.4. Ассоциативные массивы
Можно было бы представить массив как функцию, отображающую положительные целые числа (индексы) на значения некоторого произвольного типа (содержимое массива). Функция определена только для целых чисел на промежутке [0; длина_массива - 1] и задана в виде таблицы значений (собственно содержимого массива).
С этой точки зрения ассоциативные массивы – некая обобщенная форма массивов. В качестве области определения ассоциативных массивов можно использовать (почти) любой тип. Каждому значению из области определения можно поставить в соответствие значение другого типа – точно так же, как это делается с ячейками массивов. Метод записи, применяемый в случае ассоциативных массивов, и другие связанные с ними алгоритмы отличаются от метода и алгоритмов для других массивов, но, как и обычный массив, ассоциативный массив предоставляет возможность быстро сохранить и выбрать значение по ключу.
Как и ожидалось, тип ассоциативного массива задается как V[K], где K – тип ключей, а V – тип ассоциированных с ними значений. Например, создадим и инициализируем ассоциативный массив, который отображает строки на целые числа:
int[string] aa = [ "здравствуй":42, "мир":75 ];
Литерал ассоциативного массива (см. раздел 2.2.6) – это список разделенных запятыми пар вида ключ : значение, заключенный в квадратные скобки. В нашем примере литерал достаточно информативен, так что можно не указывать тип переменной aa явно, а просто написать:
auto aa = [ "здравствуй":42, "мир":75 ];
4.4.1. Длина
Для любого ассоциативного массива aa свойство aa.length типа size_t возвращает число ключей в aa (а значит, и число значений, учитывая, что между ключами и значениями отношение один-к-одному).
Ассоциативный массив, созданный по умолчанию (без литерала), имеет нулевую длину, а проверка на равенство такого массива константе null возвращает true.
string[int] aa;
assert(aa == null);
assert(aa.length == 0);
aa = [0:"zero", 1:"not zero"];
assert(aa.length == 2);
В отличие от одноименного свойства массивов, свойство .length ассоциативных массивов предназначено только для чтения. Тем не менее можно очистить ассоциативный массив, присвоив его переменной значение null.
4.4.2. Чтение и запись ячеек
Чтобы записать в ассоциативный массив aa новую пару ключ–значение, или заменить значение, уже поставленное в соответствие этому ключу, просто присвойте новое значение выражению aa[key]3, как здесь:
// Создать ассоциативный массив с соответствием строка/строка
auto aa = [ "здравствуй":"salve", "мир":"mundi" ];
// Перезаписать значения
aa["здравствуй"] = "ciao";
aa["мир"] = "mondo";
// Создать несколько новых пар ключ–значение
aa["капуста"] = "cavolo";
aa["моцарелла"] = "mozzarella";
Чтобы прочитать из ассоциативного массива значение по ключу, просто воспользуйтесь выражением aa[key]. (Компилятор различает чтение и запись и вызывает для этого функции, которые немного отличаются друг от друга.) Продолжим предыдущий пример:
assert(aa["здравствуй"] == "ciao");
Если вы попытаетесь прочитать значение по ключу, которого нет в ассоциативном массиве, возникнет исключительная ситуация. Но обычно генерация исключения в случае, когда ключ не обнаружен, – слишком строгая мера, чтобы быть полезной, поэтому для чтения ассоциативных массивов предоставляется альтернативная функция, возвращающая значение по умолчанию, если ключ не найден в массиве. Она реализована в виде метода get, принимающего два аргумента. Если при вызове aa.get(ключ, значeние_по_умолчанию) в массиве найден ключ, то функция возвращает соответствующее ему значение, а выражение значение_по__умолчанию не вычисляется; иначе значение_по__умолчанию вычисляется и метод возвращает результат этого вычисления.
assert(aa["здравствуй"] == "ciao");
// Ключ "здравствуй" существует, поэтому второй аргумент игнорируется
assert(aa.get("здравствуй", "salute") == "ciao");
// Ключ "здорово" не существует, возвратить второй аргумент
assert(aa.get("здорово", "buongiorno") == "buongiorno");
Если вы просто хотите проверить, существует ли определенный ключ в ассоциативном массиве, воспользуйтесь оператором in4:
assert("здравствуй" in aa);
assert("эй" !in aa);
// Попытка прочесть aa["эй"] вызвала бы исключение
4.4.3. Копирование
Ассоциативный массив – это всего лишь ссылка с поверхностным копированием: при копировании или присваивании ассоциативных массивов создаются только новые псевдонимы для тех же данных внутри. Например:
auto a1 = [ "Jane":10.0, "Jack":20, "Bob":15 ];
auto a2 = a1; // a1 и a2 ссылаются на одни данные
a1["Bob"] = 100; // Изменяя a1,...
assert(a2["Bob"] == 100); // ...мы изменяем a2...
a2["Sam"] = 3.5; // ...и
assert(a1["Sam"] == 3.5); // наоборот
При этом у ассоциативных массивов, как и у обычных, есть свойство .dup, создающее поэлементную копию массива.
4.4.4. Проверка на равенство
Операторы is, == и != работают так, как и можно было ожидать. Для двух ассоциативных массивов a и b одного и того же типа выражение a is b истинно тогда и только тогда, когда переменные a и b ссылаются на один и тот же ассоциативный массив (то есть одной из переменных было присвоено значение другой). Выражение a == b поочередно сравнивает пары ключ–значение двух массивов с помощью оператора ==. Чтобы a и b были равны, необходимо, чтобы в них совпали все ключи и значения для этих ключей.
auto a1 = [ "Jane":10.0, "Jack":20, "Bob":15 ];
auto a2 = [ "Jane":10.0, "Jack":20, "Bob":15 ];
assert(a1 !is a2);
assert(a1 == a2);
a2["Bob"] = 18;
assert(a1 != a2);
4.4.5. Удаление элементов
Чтобы удалить из таблицы соответствий пару ключ–значение, передайте ключ в метод remove, имеющийся у каждого ассоциативного массива.
auto aa = [ "здравствуй":1, "до свидания":2 ];
aa.remove("здравствуй");
assert("здравствуй" !in aa);
aa.remove("эй"); // Ничего не происходит, т. к. в массиве aa нет ключа "эй"
Метод remove возвращает логическое значение: true, если удаленный ключ присутствовал в массиве, иначе – false.
4.4.6. Перебор элементов
Вы можете перебирать элементы ассоциативного массива с помощью старой доброй конструкции foreach (см. раздел 3.7.5). Пары ключ–значение просматриваются без определенного порядка:
import std.stdio;
void main()
{
auto coffeePrices = [
"французская ваниль" : 262,
"ява" : 239,
"французская обжарка" : 224
];
foreach (kind, price; coffeePrices)
{
writefln("%s стоит %s руб. за 100 г", kind, price);
}
}
Эта программа печатает стоимость разных сортов кофе:
французская ваниль стоит 262 руб. за 100 г
ява стоит 239 руб. за 100 г
французская обжарка стоит 224 руб. за 100 г
Свойство .keys массива позволяет скопировать сразу все ключи из этого массива. Для любого ассоциативного массива aa типа V[K] выражение aa.keys возвращает тип K[].
auto gammaFunc = [-1.5:2.363, -0.5:-3.545, 0.5:1.772];
double[] keys = gammaFunc.keys;
assert(keys == [ -1.5, 0.5, -0.5 ]);
Аналогично для любого ассоциативного массива aa свойство aa.values возвращает все значения из aa в виде массива типа V[]. В общем случае для перебора элементов ассоциативного массива предпочтительно использовать цикл foreach, а не свойства .keys и .values, так как обращение к любому из этих свойств требует выделения памяти под новый массив, причем довольно большого объема в случае больших ассоциативных массивов.
Есть два метода, позволяющих организовать перебор ключей и значений ассоциативного массива, не создавая новые массивы: с помощью выражения aa.byKey() можно просмотреть только ключи ассоциативного массива aa, а с помощью выражения aa.byValue() – только значения этого массива. Например:
auto gammaFunc = [-1.5:2.363, -0.5:-3.545, 0.5:1.772];
// Вывести все ключи
foreach (k; gammaFunc.byKey())
{
writeln(k);
}
4.4.7. Пользовательские типы
Ассоциативные массивы организованы так, что для обеспечения быстрого поиска используют хеширование и сортировку ключей. Чтобы использовать пользовательский тип для ключей ассоциативного массива, для него необходимо определить два специальных метода: toHash и opCmp. Мы еще не научились определять собственные типы и методы, поэтому отложим этот разговор до главы 6.
4.5. Строки
К строкам в D особое отношение. Два решения, принятые на ранней стадии развития языка (еще при его определении), оказались выигрышными. Во-первых, в качестве своего стандартного набора знаков D принял Юникод. (А Юникод сегодня – самый популярный и всеобъемлющий стандарт определения и представления текстовых данных.) Во-вторых, D использует кодировки UTF-8, UTF-16 и UTF-32, не отдавая предпочтения ни одной из них и не препятствуя использованию в вашем коде любой другой кодировки.
Чтобы понять, как D работает с текстом, нужно кое-что знать о Юникоде и UTF. Если хотите изучить эти предметы в полном объеме, книга «Unicode Explained» послужит вам полезным источником информации, а документированный стандарт «Консорциума Юникода» – сейчас в пятом издании, что соответствует версии 5.1 стандарта Юникод, – самая полная и точная справка по стандарту.
4.5.1. Кодовые точки
Нужно пояснить: Юникод различает «абстрактный знак», или кодовую точку (code point), и его представление, или кодировку (encoding). Об этой тонкости мало кто знает, отчасти потому, что в стандарте ASCII нет такого отдельного представления. Старый добрый стандарт ASCII каждому знаку, часто встречающемуся в англоязычных текстах, (и каждому из немногих «управляющих кодов») ставит в соответствие число в диапазоне от 0 до 127, то есть 7 бит. Когда был предложен стандарт ASCII, большинство компьютеров уже использовали 8-битный байт (октет) в качестве адресуемой единицы, и вопрос о «кодировании» ASCII-текста не стоял. (Оставшийся бит оставлял простор для творчества, что закончилось «Кембрийским взрывом»5 взаимно несовместимых расширений.)
Юникод же, напротив, сначала определяет кодовые точки, то есть, попросту говоря, числа, поставленные в соответствие абстрактным знакам. Абстрактный знак A получает номер 65, абстрактный знак € – номер 8364 и т. д. Принятие решений о том, какие знаки заслуживают быть включенными в таблицу знаков Юникода и как присваивать им номера, – одно из важных дел, которыми занимается организация «Консорциум Юникода». И это здорово, потому что все могут использовать установленное ею соответствие между абстрактными знаками и числами, не беспокоясь о таких мелочах, как его определение и документирование.
По версии стандарта Юникод 5.1 кодовые точки Юникод находятся в диапазоне от 0 до 1 114 111 (верхний предел гораздо чаще приводят в шестнадцатеричном представлении: 0x10FFFF, или U+10FFFF – в особой юникодовской форме записи). Возможно, обычное заблуждение о том, что двумя байтами можно представить любой из знаков таблицы Юникода, столь распространено из-за того, что некоторые языки приняли в качестве стандарта двухбайтное представление знаков (что, в свою очередь, стало следствием именно такого представления в более ранних версиях стандарта Юникод). На самом деле, число знаков Юникод ровно в 17 раз превышает 65 536 (максимальное число, доступное для двух байтного представления). (По правде говоря, кодовые точки с большими значениями практически не используются, а многие из них вообще пока не имеют представления.)
В любом случае, когда дело касается кодовых точек, можно не думать об их представлении. Отвлеченно можно считать кодовые точки огромной таблицей значений функции, ставящей в соответствие целым числам от 0 до 1 114 111 абстрактные знаки. Порядок назначения номеров из этого диапазона имеет множество нюансов, но это не умаляет правильности нашего высокоуровневого описания. О конкретном представлении кодовой точки из таблицы Юникод в виде последовательности байтов позаботится кодировка.
4.5.2. Кодировки
Если бы Юникод не задумываясь последовал общему подходу ASCII, он бы просто расширил верхнюю границу 0x10FFFF до следующего байта, чтобы каждая кодовая точка представлялась бы тремя байтами. Но у такого решения есть определенный недостаток. В большинстве текстов на английском или другом языке с основанным на латинице алфавитом была бы задействована статистически очень малая часть от общего количества кодовых точек (чисел), то есть память тратилась бы понапрасну. Размер обычных текстов на латинице просто-напросто вырос бы втрое. Алфавиты с большим количеством знаков (такие как азиатские системы письменности) нашли бы трем байтам лучшее применение, и это нормально, ведь в целом в тексте было бы меньше знаков (но каждый знак был бы более информативен).
Чтобы не занимать лишнее место, Юникод принял несколько схем кодирования с переменной длиной представления знаков. Такие схемы используют один или несколько «более узких» кодов для представления всего диапазона кодовых точек Юникода. Узкие коды (обычно 8- или 16-битные) называются кодовыми единицами (code units). Каждая кодовая точка представляется одной или несколькими кодовыми единицами.
Первой стандартизированной кодировкой, работающей по этому принципу, стала кодировка UTF-8. UTF-8, которую Кен Томпсон придумал однажды вечером в небольшом ресторанчике в Нью-Джерси, – почти образцовый пример оригинального и надежного решения. Основная идея UTF-8: использовать для кодирования любого заданного знака от 1 до 6 байт; добавлять управляющие биты, по которым можно будет различать представления знаков разной длины. Представления первых 127 кодовых точек в кодировке UTF-8 идентичны представлениям в ASCII. То есть все ASCII-тексты автоматически становятся корректными с точки зрения UTF-8, что само по себе блестящий ход. Для кодовых точек, не входящих в диапазон ASCII, UTF-8 использует представления разной длины (табл. 4.2).
Таблица 4.2. Битовые представления UTF-8. Длина представления определяется по контрольным битам, что позволяет выполнять синхронизацию посреди потока, восстановление после ошибок и просмотр строки в обратном направлении
| Кодовая точка (в шестнадцатиричном представлении) | Бинарное представление |
|---|---|
00000000–0000007F |
0xxxxxxx |
00000080–000007FF |
110xxxxx 10xxxxxx |
00000800–0000FFFF |
1110xxxx 10xxxxxx 10xxxxxx |
00010000–001FFFFF |
11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
00200000–03FFFFFF |
111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx |
04000000–7FFFFFFF |
1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx |
Поскольку на сегодня верхней границей диапазона кодовых точек Юникод является число 0x10FFFF, две последние последовательности зарезервированы для использования в будущем; в настоящее время корректны только четырехбайтные представления.
Выбранные последовательности управляющих битов обладают двумя любопытными свойствами:
- Первый байт представления всегда отличается от остальных его байтов.
- Первый байт однозначно определяет длину представления.
Первое свойство является ключевым, так как находит два важных применения. Первое – простая синхронизация: начав принимать передаваемую информацию в кодировке UTF-8, прямо посреди потока легко можно выяснить, где начинается представление следующей кодовой точки (просто найдите следующий байт, начинающийся не с 10). Второе применение этого свойства – просмотр в обратном направлении: по строке UTF-8 можно легко перемещаться от конца к началу, не сбиваясь. Возможность просматривать строки UTF-8 в обратном направлении позволяет организовать множество алгоритмов (например, эффективный поиск последнего вхождения одной строки в другую). Второе свойство последовательностей управляющих битов не столь значимо, но оно упрощает и ускоряет обработку строк.
В идеале часто встречающиеся кодовые точки должны иметь малые представления, а редко встречающиеся – большие. При таких условиях кодировка UTF-8 работает как хороший статистический кодировщик, обозначая более часто встречающиеся знаки меньшим количеством битов. Это удобно для языков с алфавитом на основе латиницы, где для большинства букв достаточно одного байта, а для редких букв с диакритическими знаками – двух.
UTF-16 – тоже кодировка с переменной длиной, но в ней применяется другой (пожалуй, менее элегантный) подход к кодированию. Кодовые точки со значениями в диапазоне от 0 до 0xFFFF кодируются одной 16-битной кодовой единицей, а кодовые точки со значениями в диапазоне от 0x10000 до 0x10FFFF представляются суррогатными парами, то есть двумя кодовыми единицами, первая из которых находится в диапазоне от 0xD800 до 0xDBFF, а вторая – в диапазоне от 0xDC00 до 0xDFFF. Ради этой кодировки Юникод отказался от отображения кодовых точек на значения в диапазоне 0xD800–0xDBFF. Диапазоны значений первой и второй кодовых единиц называются верхней суррогатной зоной (high surrogate area) и нижней суррогатной зоной (low surrogate area) соответственно.
Обычно UTF-16 критикуют за то, что в этой кодировке статистически редкие случаи также становятся наиболее сложными в обработке и требуют самого тщательного рассмотрения. К сожалению, не все, но большинство знаков Юникода – так называемая базовая многоязыковая плоскость (Basic Multilingual Plane, BMP) – действительно могут быть закодированы единственной кодовой единицей кодировки UTF-16, поэтому множество программ, работающих с UTF-16, автоматически принимают одну кодовую единицу за представление одного знака, отказываясь от проверок на наличие суррогатных пар в пользу эффективности. Еще больше усугубляет путаницу то, что некоторые языки изначально выбрали поддержку предшественницы UTF-16 – кодировки UCS-2 (в которой одной кодовой точке соответствуют ровно 16 бит), а позже решили добавить поддержку UTF-16, что осложнило использование старого кода, полагающегося на соответствие между знаками и их кодовыми единицами вида один-к-одному.
Наконец, кодировка UTF-32 использует 32 бита для одной кодовой единицы. Это означает, что в кодировке UTF-32 принято самое простое и легкое в использовании, но в то же время самое «прожорливое» представление кодовых точек. Обычно рекомендуют придерживаться следующей политики: кодировку UTF-8 использовать для хранения, а к кодировке UTF-32 обращаться лишь временно, во время обработки, и только при необходимости.
4.5.3. Знаковые типы
В языке D определено три знаковых типа: char, wchar и dchar, обозначающие кодовые единицы кодировок UTF-8, UTF-16 и UTF-32 соответственно. В качестве значений свойства .init этих типов намеренно выбраны некорректные значения: char.init равно 0xFF, wchar.init – 0xFFFF, а dchar.init – 0x0000FFFF.
Из табл. 4.2 видно, что константа 0xFF не может быть частью корректного битового представления знака в кодировке UTF-8, а значению 0xFFFF Юникод намеренно не ставит в соответствие никакую кодовую точку.
Используемые по отдельности, значения этих трех знаковых типов ведут себя в основном как целые числа без знака и иногда могут использоваться для хранения некорректных UTF-представлений кодовых точек (компилятор не заботится о том, чтобы везде использовались корректные представления кодовых точек), но изначально задуманное назначение типов char, wchar и dchar – служить UTF-представлениями кодовых точек. А для работы с 8-, 16- и 32-битными целыми числами без знака и для представления кодировок, не входящих в группу UTF, лучше всего использовать типы ubyte, ushort и uint соответственно. Например, для работы с применявшимися до появления Юникода 8-битными кодовыми страницами вы можете взять за основу значения типа ubyte, а не char.
4.5.4. Массивы знаков + бонусы = строки
Сформированный массив любого знакового типа – такого как char[], wchar[] или dchar[] – компилятор и библиотека средств поддержки времени исполнения считают строками Юникода в одной из UTF-кодировок. Следовательно, массивы знаков сочетают в себе мощь и гибкость, свойственные массивам, и некоторые дополнительные преимущества, предоставляемые Юникодом.
На самом деле, в D уже определены три типа строк, соответствующие трем размерам представления знаков: string, wstring и dstring. Это не особые типы, а всего лишь псевдонимы массивов знаковых типов с одним отличием: знаковый тип снабжен квалификатором immutable, запрещающим произвольное изменение отдельных знаков в строке. Например, тип string – более короткий синоним для типа immutable(char)[]. Подробное обсуждение квалификаторов типов (в том числе immutable) мы отложим до главы 8, но для строк в любой кодировке действие immutable объясняется очень просто: свойства значения типа string, также известного как immutable(char)[], идентичны свойствам значения типа char[] (а свойства значения типа immutable(wchar)[] – свойствам значения типа wchar[]), за исключением маленького отличия: нельзя присвоить новое значение отдельному знаку строки:
string a = "hello";
char h = a[0]; // Все в порядке
a[0] = 'H'; // Ошибка! Присваивать типу immutable(char) запрещено!
Чтобы изменить в строке какой-то конкретный знак, требуется создать новое значение типа string, применив конкатенацию:
string a = "hello";
a = 'H' ~ a[1 .. $]; // Все в порядке, делает выражение a == "Hello" истинным
Почему было принято такое решение? В конце концов в приведенном выше примере совершенно бессмысленно выделять новую область памяти под целую строку (вспомните, в разделе 4.1.6 говорилось, что оператор ~ всегда требует выделения новой области памяти под новый массив), вместо того чтобы просто изменить уже имеющуюся строку. В пользу квалификатора immutable говорит то, что его наличие упрощает ситуации, когда объект типа string, wstring или dstring копируется, а потом изменяется. Квалификатор гарантирует отсутствие лишних ссылок на одну и ту же строку. Например:
string a = "hello";
string b = a; // Переменная b теперь тоже указывает на значение "hello"
string c = b[0 .. 4]; // Переменная c указывает на строку "hell"
// Если бы такое присваивание было разрешено, это изменило бы a, b, и c: a[0] = 'H';
// Конкатенация оставляет переменные b и c нетронутыми:
a = 'H' ~ a[1 .. $];
assert(a == "Hello" && b == "hello" && c == "hell");
Неизменяемость отдельных знаков позволяет работать с несколькими переменными, ссылающимися на одну и ту же строку, не боясь, что изменение одной из них отразится и на других. Копировать строковые объекты очень дешево, поскольку не реализуется никакая особая стратегия копирования (например, раннее копирование или копирование при записи).
Не менее весомая причина запретить изменения в строках на уровне кодовых единиц – такие изменения все равно лишены смысла. Элементы string имеют разную длину, а в большинстве случаев требуется заменить логические знаки (кодовые точки), а не физические (кодовые единицы), поэтому желание проводить хирургические операции над отдельными знаками возникает редко. Гораздо легче записать правильный UTF-код, отказавшись от присваивания отдельным знакам, но уделив больше внимания работе с целыми строками и их фрагментами. Стандартная библиотека D задает тон, поддерживая работу со строками как с едиными сущностями (а не с индексами и отдельными знаками). Тем не менее писать UTF-код не так легко; например, в предыдущем примере в конкатенации 'H' ~ a[1 .. $] допущена ошибка: эта запись предполагает, что первая кодовая точка занимает ровно один байт. Правильное решение выглядит так:
a = 'H' ~ a[stride(a, 0) .. $];
Функция stride из модуля std.utf стандартной библиотеки возвращает длину кода знака в указанной позиции строки. Для доступа к функции stride и другому полезному содержимому библиотеки вставьте где-нибудь ближе к началу программы строку:
import std.utf;
В нашем случае вызов stride(a, 0) возвращает количество байт двоичного представления первого знака (кодовой точки) в строке a. Именно это число мы используем при получении среза, помечая начало второго знака.
Наглядный пример поддержки Юникода языком можно обнаружить в строковых литералах, с которыми мы уже успели познакомиться (см. раздел 2.2.5). Строковые литералы D «понимают» кодовые точки из таблицы Юникод и автоматически кодируют их в соответствии с любой выбранной вами кодировкой. Например:
import std.stdio;
void main()
{
string a = "Независимо от представления \u03bb стоит \u20AC20.";
wstring b = "Независимо от представления \u03bb стоит \u20AC20.";
dstring c = "Независимо от представления \u03bb стоит \u20AC20.";
writeln(a, '\n', b, '\n', c);
}
Несмотря на то что внутренние представления строк a, b и c сильно отличаются друг от друга, вам не нужно об этом беспокоиться, потому что вы задаете литерал в абстрактном виде, используя кодовые точки. Компилятор заботится обо всех тонкостях кодирования, так что в итоге программа печатает три строки с одним и тем же текстом:
Независимо от представления λ стоит €=20.
Кодировка литерала определяется контекстом, в котором этот литерал используется. В предыдущем примере компилятор преобразует строковый литерал, без какой-либо обработки во время исполнения программы, из кодировки UTF-8 в кодировку UTF-16, а потом в кодировку UTF-32 (соответствующие типам string, wstring и dstring), хотя написание литералов во всех трех случаях одинаково. Если требуемая кодировка литерала не может быть однозначно определена, добавьте к нему суффикс c, w или d (например, "как_здесь"d): строка будет преобразована в кодировку UTF-8, UTF-16 или UTF-32 соответственно (см. раздел 2.2.5.2).
4.5.4.1. Цикл foreach применительно к строкам
Если просматривать строку str (в любой кодировке) таким способом:
foreach (c; str)
{
... // Использовать c
}
то переменная c поочередно примет значение каждой из кодовых единиц строки str. Например, если str – массив элементов типа char (с квалификатором immutable или без), то переменной c присваивается тип char. Это ожидаемо, если вспомнить, как ведет себя цикл просмотра с массивами, но иногда для строк такое поведение нежелательно. Например, напечатаем знаки строки типа string, заключив каждый из них в квадратные скобки.
void main()
{
string str = "Hall\u00E5, V\u00E4rld!";
foreach (c; str)
{
write('[', c, ']');
}
writeln();
}
Но напечатает эта программа совсем не то, что ожидалось:
[H][a][l][l][<EFBFBD>][<EFBFBD>][,][ ][V][<EFBFBD>][<EFBFBD>][r][l][d][!]
Негатив знака <EFBFBD> (может отличаться в зависимости от операционной системы и используемого шрифта) – это немой протест консоли против отображения некорректного UTF-кода. Разумеется, попытка напечатать отдельный элемент типа char, обретающий смысл только в сочетании с другими элементами типа char, обречена на провал.
Но самое интересное начинается, если вы укажете для c другой знаковый тип. Например, назначим переменной c тип dchar:
...тот же самый код, добавлен только тип "dchar"...
foreach (dchar c; str)
{
write('[', c, ']');
}
В этом случае компилятор автоматически вставляет код для перекодировки «на лету» каждой кодовой единицы в str в представление, диктуемое типом переменной c. Наш цикл напечатает:
[H][a][l][l][å][,][ ][V][ä][r][l][d][!]
а это указывает на то, что каждый из двухбайтных знаков å и ä был правильно преобразован к соответствующему знаку типа dchar, и поэтому они были напечатаны верно. То же самое будет напечатано, если задать для переменной c тип wchar, поскольку указанные в литерале два знака, отсутствующие в таблице ASCII, вмещаются в единственную кодовую единицу кодировки UTF-16, но это не общий случай (суррогатные пары будут обработаны неверно). Однако чтобы обеспечить максимально возможную степень безопасности, конечно же, лучше всего при просмотре строк использовать тип dchar.
В рассмотренном примере в инструкции foreach выполнялось перекодирование в направлении от «узкого» к более «широкому» представлению, но обратное преобразование также возможно. Например, можно начать со значения типа dstring, а затем просмотреть его по одному (закодированному) знаку типа char.
4.6. Опасный собрат массива – указатель
Объект массива отслеживает в памяти группу типизированных объектов, сохраняя адреса ее верхней и нижней границ. Указатель – «наполовину массив»: он позволяет отслеживать только один объект. Поэтому указатель не знает, где начинается и заканчивается группа объектов. Если вы получите эту информацию откуда-то извне, то сможете использовать ее для организации перемещения указателя, заставляя его указывать на соседние элементы.
Указатель на объект типа T обозначается как тип T* и по умолчанию имеет значение null (то есть указывает «в никуда»). Направить указатель на объект можно с помощью оператора получения адреса &, а использовать этот объект – с помощью оператора разыменования * (см. раздел 2.3.6.2). Например:
int x = 42;
int* p = &x; // Получить адрес x
*p = 10; // *p можно использовать там же, где и x
++*p; // Обычные операторы также применимы
assert(x == 11); // Переменная x была изменена с помощью указателя p
Указатели могут участвовать в арифметических операциях, что делает чрезвычайно заманчивым их применение в качестве курсоров внутри массивов. Если увеличить указатель на единицу, он будет указывать на следующий элемент массива, если уменьшить на единицу – на предыдущий элемент. Прибавив к указателю целое число n, получим указатель на объект, отстоящий от элемента, на который указывал исходный указатель, на n позиций вправо, если n больше нуля, и влево, если n меньше нуля. Ради упрощения операции индексирования выражение p[n] эквивалентно выражению *(p + n). Наконец, разница между двумя указателями p2 - p1 соответствует такому целому числу n, что p1 + n == p2.
Можно получить адрес первого элемента массива arr с помощью выражения вида arr.ptr. Следовательно указатель на последний элемент непустого массива arr можно получить с помощью выражения arr.ptr + arr.length - 1, а указатель на область памяти сразу за последним элементом массива – с помощью выражения arr.ptr + arr.length. Проиллюстрируем все сказанное примером:
auto arr = [ 5, 10, 20, 30 ];
auto p = arr.ptr;
assert(*p == 5);
++p;
assert(*p == 10);
++*p;
assert(*p == 11);
p += 2;
assert(*p == 30);
assert(p - arr.ptr == 3);
Однако будьте осторожны: если вы не обладаете информацией об адресах границ массива (указатель вам об этом не сообщит, а значит, это должно быть известно откуда-то еще), ситуация вскоре может стать непредсказуемой. Никакие операции с участием указателей не проверяются: указатель – это всего лишь адрес памяти длиной в слово6, и арифметические операции, которые вы к нему применяете, просто слепо исполняют то, о чем вы просите. Это делает указатели невероятно быстрыми и при этом ужасно неосведомленными. Указатель недостаточно умен даже для того, чтобы понять, что он указывает на отдельный объект (в отличие от указания на элемент массива):
auto x = 10;
auto y = &x;
++y; // Хм...
Указателю также неизвестно, когда он вышел за границу массива:
auto x = [ 10, 20 ];
auto y = x.ptr;
y += 100; // Хм...
*y = 0xdeadbeef; // Русская рулетка
Присваивать значение с помощью указателя, который не указывает на корректные данные, – значит играть в русскую рулетку с целостностью своей программы: записи могут «приземлиться» где угодно, растоптав самые тщательно оберегаемые данные, а то и код. Все это делает указатели небезопасным для памяти (memory-unsafe) средством.
Поэтому старательно избегайте указателей, отдавая предпочтение массивам, ссылкам на классы (см. главу 6), аргументам функций, переданным с ключевым словом ref (см. раздел 5.2.1), и автоматическому управлению памятью. Все эти средства безопасны, могут эффективно проверяться и почти не снижают быстродействие.
В действительности, массивы – весьма полезная абстракция, тщательно спроектированная с единственною целью: создать самое быстрое после указателей средство с учетом ограничений безопасности для памяти. Очевидно, что сам по себе указатель не имеет доступа к достаточному количеству информации, чтобы выяснить что-то самостоятельно; массив, напротив, знает свой размер, поэтому может легко проверять, что все операции над ними совершаются в пределах границ расположения данных.
С точки зрения высокого уровня можно отметить, что массивы слишком низкоуровневые и что их реализация недотягивает до абстрактного типа данных. С другой стороны, если мыслить низкоуровневыми категориями, может показаться, что в массивах нет необходимости, так как они могут быть реализованы с помощью указателей. Ответ на оба эти аргумента против массивов все тот же: «Я все объясню».
Ценность массивов в том, что из всех абстракций эта абстракция – самая низкоуровневая, но при этом она уже безопасна. Если бы язык предоставлял только указатели, то был бы не способен обеспечить безопасность различных пользовательских конструкций более высокого уровня, построенных на базе указателей. Массивы также не должны быть слишком высокоуровневыми, потому что являются встроенными, а значит, все остальное будет создаваться, используя их как основу. Хорошее встроенное средство должно быть низкоуровневым и быстрым, чтобы можно было строить на его базе абстракции более высокого уровня, необязательно столь же быстрые. Именно так и развиваются абстракции.
Существует «урезанная» безопасная версия D, известная как SafeD (см. главу 11), также есть флаг компилятора, установка которого включает проверку принадлежности используемых в программе инструкций и типов данных этому безопасному подмножеству средств языка. Естественно, в безопасном D (SafeD) запрещено большинство операций с указателями. Встроенные массивы – это важное средство, позволяющее создавать мощные, выразительные программы на SafeD.
4.7. Итоги и справочник
В табл. 4.3 собрана информация об операциях над динамическими массивами, в табл. 4.4. – об операциях над массивами фиксированной длины, а в табл. 4.5 – об операциях над ассоциативными массивами.
Таблица 4.3. Операции над динамическими массивами (a и b – два значения типа T[]; t, t1, ..., tk – значения типа T; n – значение, приводимое к типу размер_t)
| Выражение | Тип | Описание |
|---|---|---|
new T[n] |
T[] |
Создает массив (см. раздел 4.1) |
[t1,t2, ..., tk] |
T[] |
Литерал массива; T определяется по типу t1 (см. разделы 2.2.6 и 4.1) |
a = b |
T[] |
Присваивает один массив другому (см. раздел 4.1.4) |
a[‹в›] |
ref T |
Предоставляет доступ к элементу по индексу (символ $ в выражении ‹в› заменяется на a.length, ‹в› должно быть приводимым к типу размер_t; кроме того, должно соблюдаться условие ‹в› < a.length) () |
a[‹в1› .. ‹в2›] |
T[] |
Получает срез массива a (знак $ в ‹в1› и ‹в2› заменяется на a.length, ‹в1› и ‹в2› должны быть приводимыми к типу размер_t, также должно соблюдаться условие ‹в1› <= ‹в2› && ‹в2› <= a.length) () |
a[] |
T[] |
Поэлементная операция () или альтернативное написание выражения a[0 .. $], возвращающего содержимое всего массива |
a.dup |
T[] |
Получает дубликат массива () |
a.length |
размер_t |
Читает длину массива () |
a.length = n |
размер_t |
Изменяет длину массива () |
a is b |
bool |
Проверяет, идентичны ли массивы друг другу () |
a !is b |
bool |
То же, что !(a is b) |
a == b |
bool |
Поэлементно сравнивает массивы на равенство () |
a != b |
bool |
То же, что !(a == b) |
a ~ t |
T[] |
Конкатенирует массив и отдельное значение () |
t ~ a |
T[] |
Конкатенирует отдельное значение и массив () |
a ~ b |
T[] |
Конкатенирует два массива () |
a ~= t |
T[] |
Присоединяет элемент к массиву () |
a ~= b |
T[] |
Присоединяет один массив к другому () |
a.ptr |
T* |
Возвращает адрес первого элемента массива a (небезопасная операция) () |
Таблица 4.4. Операции над массивами фиксированной длины (a и b – два значения типа T[]; t, t1, ..., tk – значения типа T; n – значение, приводимое к типу размер_t)
| Выражение | Тип | Описание |
|---|---|---|
[t1, ..., tk] |
T[k] |
Литерал массива, но только если тип T[k] запрошен явно; T определяется по типу t1 () |
a = b |
ref T[n] |
Копирует содержимое одного массива в другой () |
a[‹в›] |
ref T |
Предоставляет доступ к элементу по индексу (символ $ в ‹в› заменяется на a.length, ‹в› должно быть приводимым к типу размер_t; кроме того, должно соблюдаться условие ‹в› < a.length) () |
a[‹в1› .. ‹в2›] |
T[]/T[k] |
Получает срез массива a (символ $ в ‹в1› и ‹в2› заменяется на a.length, ‹в1› и ‹в2› должны быть приводимыми к типу размер_t, также должно соблюдаться условие ‹в1› <= ‹в2› && ‹в2› <= a.length) ()) |
a[] |
T[] |
Поэлементная операция () или приведение a (массива фиксированной длины) к типу динамического массива, то же, что и a[0 .. $] |
a.dup |
T[] |
Получает дубликат массива () |
a.length |
размер_t |
Читает длину массива () |
a is b |
bool |
Проверяет, идентичны ли массивы друг другу () |
a !is b |
bool |
То же, что и !(a is b) |
a == b |
bool |
Поэлементно сравнивает массивы на равенство () |
a != b |
bool |
То же, что и !(a == b) |
a ~ t |
T[] |
Конкатенирует массив и отдельное значение () |
t ~ a |
T[] |
Конкатенирует отдельное значение и массив () |
a ~ b |
T[] |
Конкатенирует два массива () |
a.ptr |
T* |
Возвращает адрес первого элемента массива a (небезопасная операция) |
Таблица 4.5. Операции над ассоциативными массивами (a и b – два значения типа V[K]; k, k1, ..., ki – значения типа K; v, v1, ..., vk – значения типа V)
| Выражение | Тип | Описание |
|---|---|---|
[t1:v1, ..., ti:vi] |
V[K] |
Литерал ассоциативного массива; K определяется по типу k1, а V – по типу v1 () |
a = b |
V[K] |
Присваивает ассоциативный массив b переменной a типа «ассоциативный массив» () |
a[k] |
V |
Предоставляет доступ к элементу по индексу (если ключ k не найден, возникает исключение) () |
a[k] = v |
V |
Ставит в соответствие ключу k значение v (переопределяет предыдущее соответствие, если оно уже было назначено) () |
k in a |
V* |
Ищет k в a, возвращает null, если не находит, иначе – указатель на значение, ассоциированное с k () |
k !in a |
bool |
То же, что и !(k in a) |
a.length |
размер_t |
Читает значение, соответствующее числу элементов в a () |
a is b |
bool |
Проверяет, идентичны ли массивы друг другу () |
a !is b |
bool |
То же, что и !(a is b) |
a == b |
bool |
Поэлементно сравнивает массивы на равенство () |
a != b |
bool |
То же, что и !(a == b) |
a.remove(k) |
bool |
Удаляет пару с ключом k, если такая есть; возвращает true, если и только если ключ k присутствовал в a () |
a.dup |
V[K] |
Создает дубликат ассоциативного массива a () |
a.get(k, v) |
V |
Возвращает значение из a, соответствующее ключу k; по умолчанию возвращается значение v () |
a.byKey() |
int delegate(int delegate(ref K)) |
Возвращает делегат, пригодный для использования в цикле foreach для итерации по ключам |
a.byValue() |
int delegate(int delegate(ref V)) |
Возвращает делегат, пригодный для использования в цикле foreach для итерации по значениям |
-
quadrupeds (англ.) – четвероногие. – Прим. пер. ↩︎
-
Заметим также, что переход по нужному индексу статического многомерного массива происходит за один раз, а сам массив хранится в непрерывной области памяти. Например, для хранения массива
arrтипаint[5][5]выделяется область размером5 * 5 * int.sizeofбайт, а переход по адресуarr[2][2]выглядит как&arr + 2 * 5 + 2. Если же статический массив размещается в сегменте данных (как глобальная переменная или как локальная с атрибутомstatic), а индексы известны на этапе компиляции, то переход по указателю вообще не потребуется. – Прим. науч. ред. ↩︎ -
При этом для массива типа
V[K]передаваемые ключи должны иметь типimmutable(K)или неявно приводимый к нему. Это требование введено для того, чтобы в процессе работы программы значение ключа не могло быть изменено косвенным образом, что повлекло бы нарушение структуры ассоциативного массива. – Прим. науч. ред. ↩︎ -
Как уже говорилось, оператор
inвозвращает указатель на элемент, соответствующий ключу, илиnull, если такой ключ отсутствует в массиве. – Прим. науч. ред. ↩︎ -
Кембрийский взрыв – неожиданное появление в раннекембрийских отложениях окаменелостей представителей многих подразделений животного царства на фоне отсутствия их окаменелостей или окаменелостей их предков в докембрийских отложениях. – Прим. пер. ↩︎
-
В архитектуре x86 тип указатель размером в 4 байта соответствует двойному слову (
DW), а слову соответствует типshortразмером 2 байта. – Прим. науч. ред. ↩︎