| .. | ||
| images | ||
| src | ||
| README.md | ||
2. Основные типы данных. Выражения
- 2.1. Идентификаторы
- 2.2. Литералы
- 2.3. Операции
- 2.3.1. l-значения и r-значения
- 2.3.2. Неявные преобразования чисел
- 2.3.3. Типы числовых операций
- 2.3.4. Первичные выражения
- 2.3.5. Постфиксные операции
- 2.3.6. Унарные операции
- 2.3.7. Возведение в степень
- 2.3.8. Мультипликативные операции
- 2.3.9. Аддитивные операции
- 2.3.10. Сдвиг
- 2.3.11. Выражения in
- 2.3.12. Сравнение
- 2.3.13. Поразрядные ИЛИ, ИСКЛЮЧАЮЩЕЕ ИЛИ и И
- 2.3.14. Логическое И
- 2.3.15. Логическое ИЛИ
- 2.3.16. Тернарная условная операция
- 2.3.17. Присваивание
- 2.3.18. Выражения с запятой
- 2.4. Итоги и справочник
Если вы когда-нибудь программировали на C, C++, Java или C#, то с основными типами данных и выражениями D у вас не будет никаких затруднений. Операции со значениями основных типов – неотъемлемая часть решений многих задач программирования. Эти средства языка, в зависимости от ваших предпочтений, могут сильно облегчать либо отравлять вам жизнь. Совершенного подхода не существует; нередко поставленные цели противоречат друг другу, заставляя руководствоваться собственным субъективным мнением. Это, в свою очередь, лишает язык возможности угодить всем до единого. Слишком строгая система обременяет программиста своими запретами: он вынужден бороться с компилятором, чтобы тот принял простейшие выражения. А сделай систему типизации чересчур снисходительной – и не заметишь, как окажешься по ту сторону корректности, эффективности или того и другого вместе.
Система основных типов D творит маленькие чудеса в границах, задаваемых его принадлежностью к семейству статически типизированных компилируемых языков. Определение типа по контексту, распространение интервала значений, всевозможные стратегии перегрузки операторов и тщательно спроектированная сеть автоматических преобразований вместе делают систему типизации D дотошным, но сдержанным помощником, который если и придирается, требуя внимания, то обычно не зря.
Основные типы данных можно распределить по следующим категориям:
- Тип без значения:
void, используется во всех случаях, когда формально требуется указать тип, но никакое осмысленное значение не порождается. - Тип null:
typeof(null)– тип константыnull, используется в основном в шаблонах, неявно приводится к указателям, массивам, ассоциативным массивам и объектным типам. - Логический (булев) тип:
boolс двумя возможными значениямиtrueиfalse. - Целые типы:
byte,short,intиlong, а также их эквиваленты без знакаubyte,ushort,uintиulong. - Вещественные типы с плавающей запятой:
float,doubleиreal. - Знаковые типы:
char,wcharиdchar, которые на самом деле содержат числа, предназначенные для кодирования знаков Юникода.
В табл. 2.1 вкратце описаны основные типы данных D с указанием их размеров и начальных значений по умолчанию. В языке D переменная инициализируется автоматически, если вы просто определили ее, не указав начального значения. Значение по умолчанию доступно для любого типа как <тип>.init; например int.init – это ноль.
Таблица 2.1. Основные типы данных D
| Тип данных | Описание | Начальное значение по умолчанию |
|---|---|---|
void |
Без значения | n/a |
typeof(null) |
Тип константы null |
n/a |
bool |
Логическое (булево) значение | false |
byte |
Со знаком, 8 бит | 0 |
ubyte |
Без знака, 8 бит | 0 |
short |
Со знаком, 16 бит | 0 |
ushort |
Без знака, 16 бит | 0 |
int |
Со знаком, 32 бита | 0 |
uint |
Без знака, 32 бита | 0 |
long |
Со знаком, 64 бита | 0 |
ulong |
Без знака, 64 бита | 0 |
float |
32 бита, с плавающей запятой | float.nan |
double |
64 бита, с плавающей запятой | double.nan |
real |
Наибольшее, какое только может позволить аппаратное обеспечение | real.nan |
char |
Без знака, 8 бит, в UTF-8 | 0xFF |
wchar |
Без знака, 16 бит, в UTF-16 | 0xFFFF |
dchar |
Без знака, 32 бита, в UTF-32 | 0x0000FFFF |
2.1. Идентификаторы
Идентификатор, или символ – это чувствительная к регистру строка знаков, начинающаяся с буквы или знака подчеркивания, после чего следует любое количество букв, знаков подчеркивания или цифр. Единственное исключение из этого правила: идентификаторы, начинающиеся с двух знаков подчеркивания, зарезервированы под ключевые слова самого D. Идентификаторы, начинающиеся с одного знака подчеркивания, разрешены, и в настоящее время даже принято именовать поля классов таким способом.
Интересная особенность идентификаторов D – их интернациональность: «буква» в определении выше – это не только буква латинского алфавита (от A до Z и от a до z), но и знак из универсального набора1, определенного в стандарте C992.
Например, abc, α5, _, Γ_1, _AbC, Ab9C и _9x – допустимые идентификаторы, а 9abc и __abc – нет.
Если перед идентификатором стоит точка (.какЗдесь), то компилятор ищет его в пространстве имен модуля, а не в текущем лексически близком пространстве имен. Этот префиксный оператор-точка имеет тот же приоритет, что и обычный идентификатор.
2.1.1. Ключевые слова
Приведенные в табл. 2.2 идентификаторы – это ключевые слова, зарезервированные языком для специального использования. Пользовательский код не может переопределять их ни при каких условиях.
Таблица 2.2. Ключевые слова языка D
abstract else macro switch
alias enum mixin synchronized
align export module
asm extern template
assert new this
auto false nothrow throw
final null true
body finally try
bool float out typeid
break for override typeof
byte foreach
function package ubyte
case pragma uint
cast goto private ulong
catch protected union
char ifIf public unittest
class immutable pure ushort
const import
continue in real version
inout ref void
dchar int return
debug interface wchar
default invariant scope while
delegate isIs short with
deprecated static
do long struct
double lazy super
Некоторые из ключевых слов распознаются как первичные выражения. Например, ключевое слово this внутри определения метода означает текущий объект, а ключевое слово super как статически, так и динамически заставляет компилятор обратиться к классу-родителю текущего класса (см. главу 6). Идентификатор $ разрешен только внутри индексного выражения или выражения получения среза и обозначает длину индексируемого массива. Идентификатор null обозначает пустой объект, массив или указатель.
Первичное выражение typeid(T) возвращает информацию о типе T (за дополнительной информацией обращайтесь к документации для вашей реализации компилятора).
2.2. Литералы
2.2.1. Логические литералы
Логические (булевы) литералы – это true («истина») и false («ложь»).
2.2.2. Целые литералы
D работает с десятичными, восьмеричными3, шестнадцатеричными и двоичными целыми литералами. Десятичная константа - это последовательность цифр, возможно, с суффиксом L, U, u, LU, Lu, UL или ul. Вывод о типе десятичного литерала делается исходя из следующих правил:
- нет суффикса: если значение «помещается» в
int, тоint, иначеlong; - только
U/u: если значение «помещается» вuint, тоuint, иначеulong. - только
L: тип константы -long. U/uиLсовместно: тип константы -ulong.
Например:
auto
a = 42, // a имеет тип int
b = 42u, // b имеет тип uint
c = 42UL, // c имеет тип ulong
d = 4_000_000_000, // long; в int не поместится
e = 4_000_000_000u, // uint; в uint не поместится
f = 5_000_000_000u; // ulong; в uint не поместится
Вы можете свободно вставлять в числа знаки подчеркивания (только не ставьте их в начало, иначе вы на самом деле создадите идентификатор). Знаки подчеркивания помогают сделать большое число более наглядным:
auto targetSalary = 15_000_000;
Чтобы написать шестнадцатеричное число, используйте префикс 0x или 0X, за которым следует последовательность знаков 0–9, a–f, A–F или _. Двоичный литерал создается с помощью префикса 0b или 0B, за которым идет последовательность из 0, 1 и тех же знаков подчеркивания. Как и у десятичных чисел, у всех этих литералов может быть суффикс. Правила, с помощью которых их типы определяются по контексту, идентичны правилам для десятичных чисел.
Рисунок 2.1, заменяющий 1024 слова, кратко и точно определяет синтаксис целых литералов. Правила интерпретации автомата таковы: 1) каждое ребро «поглощает» знаки, соответствующие его ребру, 2) автомат пытается «расходовать» как можно больше знаков из входной последовательности4. Достижение конечного состояния (двойной кружок) означает, что число успешно распознано.
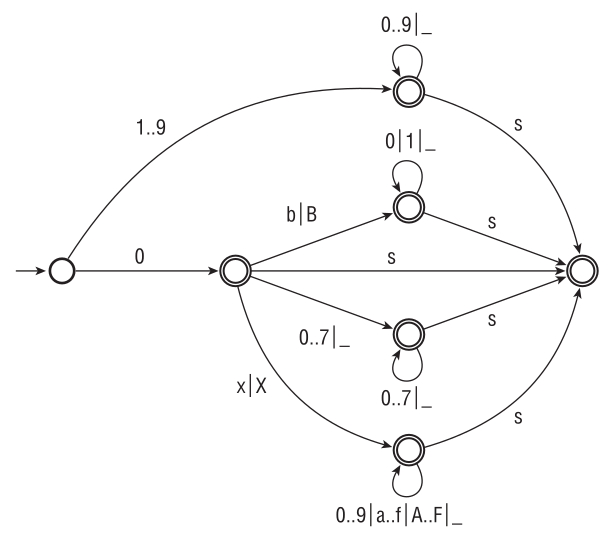
Рис. 2.1. Распознавание целых литералов в языке D. Автомат пытается сделать ряд последовательных шагов (поглощая знаки, соответствующие данному ребру), пока не остановится. Останов в конечном состоянии (двойной кружок) означает, что число успешно распознано. s обозначает суффикс вида U|u|L|UL|uL|Lu|LU
2.2.3. Литералы с плавающей запятой
Литералы с плавающей запятой могут быть десятичными и шестнадцатеричными. Десятичные литералы с плавающей запятой легко определить по аналогии с только что определенными десятичными целыми числами: десятичный литерал с плавающей запятой состоит из десятичного литерала, который также может содержать точку5 в любой позиции, за ней могут следовать показатель степени (характеристика) и суффикс. Показатель степени6 – это то, что обозначается как e, E, e+, E+, e- или E-, после чего следует целый десятичный литерал без знака7. В качестве суффикса может выступать f, F или L. Разумеется, хотя бы что-то одно из e/E и f/F должно присутствовать, иначе если в числе нет точки, вместо числа с плавающей запятой получим целое. Суффикс f/F заставляет компилятор определить тип литерала как float, а суффикс L – как real. Иначе литералу будет присвоен тип double.
Может показаться, что шестнадцатеричные константы с плавающей запятой – вещь странноватая. Однако, как показывает практика, они очень удобны, если нужно записать число очень точно. Внутреннее представление чисел с плавающей запятой характеризуется тем, что числа хранятся в двоичном виде, поэтому запись вещественного числа в десятичном виде повлечет преобразования, невозможные без округлений, поскольку 10 – не степень 2. Шестнадцатеричная форма записи, напротив, позволяет записать число с плавающей запятой точно так, как оно будет представлено. Полный курс по представлению чисел с плавающей запятой выходит за рамки этой книги; отметим лишь, что все реализации D гарантированно используют формат IEEE 754, полную информацию о котором можно найти в Сети (сделайте запрос «формат чисел с плавающей запятой IEEE 754»).
Шестнадцатеричный литерал с плавающей запятой состоит из префикса 0x или 0X, за которым следует строка шестнадцатеричных цифр, содержащая точку в любой позиции. Затем идет обязательный показатель степени8, который начинается с p, P, p+, P+, p- или P- и заканчивается десятичными (не шестнадцатеричными!) цифрами. Только так называемая мантисса – дробная часть перед показателем степени – выражается шестнадцатеричным числом; сам показатель степени – целое десятичное число. Показатель степени шестнадцатеричной константы с плавающей запятой означает степень 2 (а не 10, как в случае с десятичным представлением). Завершается литерал необязательным суффиксом f, F или L9. Рассмотрим несколько подходящих примеров:
auto
a = 1.0, // a имеет тип double
b = .345E2f, // b = 34.5 имеет тип float
c = 10f, // c имеет тип float из-за суффикса
d = 10., // d имеет тип double
e = 0x1.fffffffffffffp1023, // наибольшее возможное значение типа double
f = 0XFp1F; // f = 30.0, тип float
Рисунок 2.2 без лишних слов описывает литералы с плавающей запятой языка D. Правила интерпретации автомата те же, что и для автомата, иллюстрирующего распознавание целых литералов: переход выполняется по мере чтения знаков литерала с целью прочитать как можно больше. Представление в виде автомата проясняет несколько фактов, которые было бы утомительно описывать, не используя формальный аппарат. Например, 0x.p1 и 0xp1 – вполне приемлемые, хотя и странные формы записи нуля, а конструкции типа 0e1, .e1 и 0x0.0 запрещены.
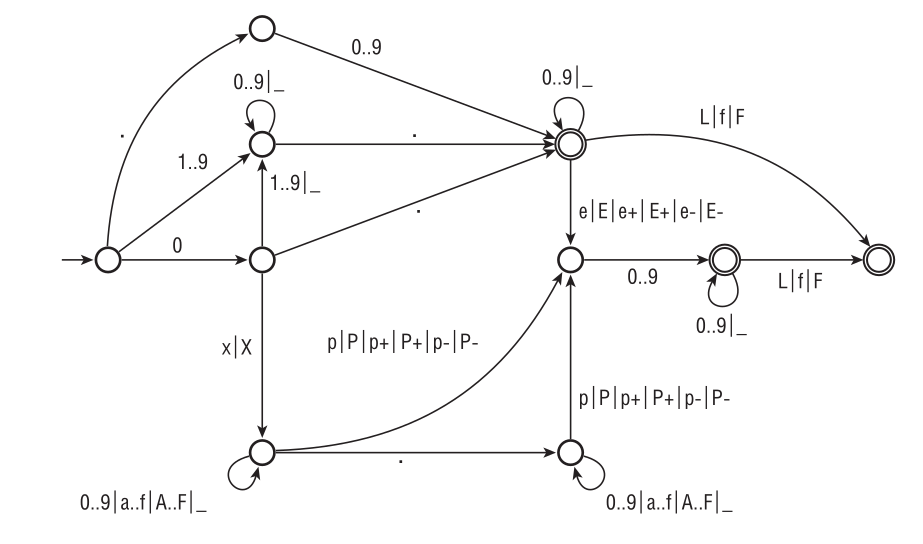
Рис. 2.2. Распознавание литералов с плавающей запятой
2.2.4. Знаковые литералы
Знаковый литерал – это один знак, заключенный в одиночные кавычки, например 'a'. Если в качестве знака выступают сами кавычки, их нужно экранировать с помощью обратной косой черты: '\''. На самом деле в D, как и в других языках, определены несколько разных escape-последовательностей10 (см. табл. 2.3). В дополнение к стандартному набору управляющих непечатаемых символов D предоставляет следующие возможности записать знаки Юникода: '\u03C9' (знаки \u, за которыми следуют ровно 4 шестнадцатеричные цифры), '\U0000211C' (знаки \U, за которыми следуют ровно 8 шестнадцатеричных цифр) и '\©' (имя, окруженное знаками \& и ;). Первый из этих примеров – знак ω в Юникоде, второй – красивая письменная ℬ, а последний – грозный знак ©. Если вам нужен полный список знаков, которые можно отобразить, поищите в Интернете информацию о таблице знаков Юникода.
Таблица 2.3. Экранирующие последовательности в D
| Escape-последовательность | Тип | Описание |
|---|---|---|
\" |
char |
Двойная кавычка (если двусмысленно) |
\\ |
char |
Обратная косая черта |
\a |
char |
Звуковой сигнал (Bell, ASCII 7) |
\b |
char |
Backspace (ASCII 8) |
\f |
char |
Смена страницы (ASCII 12) |
\n |
char |
Перевод строки (ASCII 10) |
\r |
char |
Возврат каретки (ASCII 13) |
\t |
char |
Табуляция (ASCII 9) |
\v |
char |
Вертикальная табуляция (ASCII 11) |
\<1–3 восьмеричные цифры> |
char |
Знак UTF-8 в восьмеричном представлении (не больше 3778) |
\x<2 шестнадцатеричные цифры> |
char |
Знак UTF-8 в шестнадцатеричном представлении |
\u<4 шестнадцатеричные цифры> |
wchar |
Знак UTF-16 в шестнадцатеричном представлении |
\U<8 шестнадцатеричных цифр> |
dchar |
Знак UTF-32 в шестнадцатеричном представлении |
\&<имя знака>; |
dchar |
Имя знака Юникод |
2.2.5. Строковые литералы
Теперь, когда мы знаем, как представляются отдельные знаки, строковые литералы для нас пустяк. D прекрасно справляется с обработкой строк отчасти благодаря своим мощным средствам представления строковых литералов. Как и другие языки, работающие со строками, D различает строки, заключенные в кавычки (внутри которых можно размещать экранированные последовательности из табл. 2.3), и WYSIWYG-строки11 (которые компилятор распознает «вслепую», не пытаясь обнаружить и расшифровать никакие escape-последовательности). Стиль WYSIWYG очень удобен для представления строк, где иначе пришлось бы использовать множество экранированных знаков; два выдающихся примера – регулярные выражения и пути к файлам в системе Windows. Строки, заключенные в кавычки (quoted strings), – это последовательности знаков в двойных кавычках, "как в этом примере". В таких строках все escape-последовательности из табл. 2.3 являются значимыми. Строки всех видов, расположенные подряд, автоматически подвергаются конкатенации:
auto crlf = "\r\n";
auto a = "В этой строке есть \"двойные кавычки\", а также
перевод строки, даже два" "\n";
Текст умышленно перенесен на новую строку после слова также: строковый литерал может содержать знак перевода строки (реальное начало новой строки в исходном коде, а не комбинацию \n), который будет сохранен именно в этом качестве.
2.2.5.1. Строковые литералы: WYSIWYG, с разделителями, строки токенов, шестнадцатеричные и импортированные
WYSIWYG-строка либо начинается с r" и заканчивается на " (r"как здесь"), либо начинается и заканчивается грависом12 (как здесь). В WYSIWYG-строке может встретиться любой знак (кроме соответствующих знаков начала и конца литерала), который хранится так же, как и выглядит. Это означает, что вы не можете представить, например, знак двойной кавычки внутри заключенной в такие же двойные кавычки WYSIWYG-строки. Это не проблема, потому что всегда можно сделать конкатенацию строк, представленных с помощью разных синтаксических правил. Например:
auto a = r"Строка с \ и " `"` " внутри.";
Из практических соображений можно считать, что двойная кавычка внутри r"такой строки" обозначается последовательностью 〈"`"`"〉, а гравис внутри такой строки – последовательностью 〈`"`"`〉. Счастливого подсчета кавычек.
Иногда бывает удобно описать строку, ограниченную с двух сторон какими-то символами. Для этих целей D предоставляет особый вид строковых литералов – литерал с разделителями.
auto a = q"[Какая-то строка с "кавычками", `обратными апострофами` и [квадратными скобками]]";
Теперь в a находится строка, содержащая кавычки, обратные апострофы и квадратные скобки, то есть все, что мы видим между q"[ и ]". И никаких обратных слэшей, нагромождения ненужных кавычек и прочего мусора. Общий формат этого литерала: сначала идет префикс q и двойная кавычка, за которой сразу без пробелов следует знак-разделитель. Оканчивается строка знаком-разделителем и двойной кавычкой, за которой может следовать суффикс, указывающий на тип литерала: c, w или d. Допустимы следующие парные разделители: [ и ], ( и ), < и >, { и }. Допускаются вложения парных разделителей, то есть внутри пары скобок может быть другая пара скобок, которая становится частью строки. В качестве разделителя можно также использовать любой знак, например:
auto a = q"/Просто строка/"; // Эквивалентно строке "Просто строка"
При этом строка распознается до первого вхождения ограничивающего знака:
auto a = q"/Просто/строка/"; // Ошибка.
auto b = q"[]]"; // Опять ошибка.
auto с = q"[[]]"; // А теперь все нормально, т. к. разделители [] допускают вложение.
Если в качестве разделителя нужно использовать какую-то последовательность знаков, открывающую и закрывающую последовательности следует писать на отдельной строке:
auto a = q"EndOfString
Несколько
строк
текста
EndOfString";
Кроме того, D предлагает такой вид строкового литерала, как строка токенов. Такой литерал начинается с последовательности q{ и заканчивается на }. При этом текст, расположенный между { и }, должен представлять из себя последовательность токенов языка D и интерпретируется как есть.
auto a = q{ foo(q{hello}); }; // Эквивалентно " foo(q{hello}); "
auto b = q{ № }; // Ошибка! "№" - не токен языка
auto a = q{ __EOF__ }; // Ошибка! __EOF__ - не токен, а конец файла
Также D определяет еще один вид строковых литералов – шестнадцатеричную строку, то есть строку, состоящую из шестнадцатеричных цифр и пробелов (пробелы игнорируются) между x" и ". Шестнадцатеричные строки могут быть полезны для определения сырых данных; компилятор не пытается интерпретировать содержимое литералов никак знаки Юникода, ни как-то еще – только как шестнадцатеричные цифры. Пробелы внутри строк игнорируются.
auto
a = x"0A", // То же самое, что "\x0A"
b = x"00 F BCD 32"; // То же самое, что "\x00\xFB\xCD\x32"
Если ваш хакерский мозг уже начал прикидывать, как внедрить в программы на D двоичные данные, вы будете счастливы услышать об очень мощном способе определения строки: из файла!
auto x = import("resource.bin");
Во время компиляции переменная x будет инициализирована непосредственно содержимым файла resource.bin. (Это отличается от действия директивы C #include, поскольку в рассмотренном примере файл включается в качестве данных, а не кода.) По соображениям безопасности допустимы только относительные пути и пути поиска контролируются флагами компилятора. Эталонная реализация dmd использует флаг -J для управления путями поиска.
Строка, возвращаемая функцией import, не проверяется на соответствие кодировке UTF-8. Это сделано намеренно – для реализации возможности включать двоичные данные.
2.2.5.2. Тип строкового литерала
Каков тип строкового литерала? Проведем простой эксперимент:
import std.stdio;
void main()
{
writeln(typeid(typeof("Hello, world!")));
}
Встроенный оператор typeof возвращает тип выражения, а typeid конвертирует его в печатаемую строку. Наша маленькая программа печатает:
immutable(char)[]
открывая нам то, что строковые литералы – это массивы неизменяемых знаков. На самом деле, тип string, который мы использовали в примерах, – это краткая форма записи (или псевдоним), означающая immutable(char)[]. Рассмотрим подробно все три составляющие типа строковых литералов: неизменяемость, длина и базовый тип данных – знаковый.
Неизменяемость
Строковые литералы живут в неизменяемой области памяти. Это вовсе не говорит о том, что они хранятся на действительно не стираемых кристаллах ЗУ или в защищенной области памяти операционной системы. Это означает, что язык обязуется не перезаписывать память, выделенную под строку. Ключевое слово immutable воплощает это обязательство, запрещая во время компиляции любые операции, которые могли бы модифицировать содержимое неизменяемых данных, помеченных этим ключевым словом:
auto a = "Изменить этот текст нельзя";
a[0] = 'X'; // Ошибка! Нельзя модифицировать неизменяемую строку!
Ключевое слово immutable – это квалификатор типа (квалификаторы обсуждаются в главе 8); его действие распространяется на любой тип, указанный в круглых скобках после него. Если вы напишете immutable(char)[] str, то знаки в строке str нельзя будет изменять по отдельности, однако str можно заставить ссылаться на другую строку:
immutable(char)[] str = "One";
str[0] = 'X'; // Ошибка! Нельзя присваивать значения переменным типа immutable(char)!
str = "Two"; // Отлично, присвоим str другую строку
С другой стороны, если круглые скобки отсутствуют, квалификатор immutable будет относиться ко всему массиву:
immutable char[] a = "One";
a[0] = 'X'; // Ошибка!
a = "Two"; // Ошибка!
У неизменяемости масса достоинств, а именно: квалификатор immutable предоставляет достаточно гарантий, чтобы разрешить неразборчивое совместное использование данных модулями и потоками (см. главу 13). Поскольку знаки строки неизменяемы, никогда не возникает споров, и совместный доступ безопасен и эффективен.
Длина
Очевидно, что длина строкового литерала (13 для "Hello, world!") известна во время компиляции. Поэтому может казаться естественным давать наиболее точное определение каждой строке; например, строка "Hello, world!" может быть типизирована как char[13], что означает «массив ровно из 13 знаков». Однако опыт языка Паскаль показал, что статические размеры крайне неудобны. Так что в D тип литерала не включает информацию о его длине. Тем не менее, если вы действительно хотите работать со строкой фиксированного размера, то можете создать такую, явно указав ее длину:
immutable(char)[13] a = "Hello, world!";
char[13] b = "Hello, world!";
Типы массивов фиксированного размера T[N] могут неявно конвертироваться в типы динамических массивов T[] для всех типов T. В процессе преобразования информация не теряется, так как динамические массивы «помнят» свою длину:
import std.stdio;
void main()
{
immutable(char)[3] a = "Hi!";
immutable(char)[] b = a;
writeln(a.length, " ", b.length); // Печатает "3 3"
}
Базовый тип данных – знаковый
Последнее, но немаловажное, что нужно сказать о строковых литералах, – в качестве их базового типа может выступать char, wchar или dchar13. Использовать многословные имена типов необязательно: string, wstring и dstring – удобные псевдонимы для immutable(char)[], immutable(wchar)[] и immutable(dchar)[] соответственно. Если строковый литерал содержит хотя бы один 4-байтный знак типа dchar, то строка принимает тип dstring; иначе, если строка содержит хотя бы один 2-байтный знак типа wchar, то строка принимает тип wstring, иначе строка принимает знакомый тип string. Если ожидается тип, отличный от определяемого по контексту, литерал молча уступит, как в этом примере:
wstring x = "Здравствуй, широкий мир!"; // UTF-16
dstring y = "Здравствуй, еще более широкий мир!"; // UTF-32
Если вы хотите явно указать тип строки, то можете снабдить строковый литерал суффиксом: c, w или d, которые заставляют тип строкового литерала принять значение string, wstring или dstring соответственно.
2.2.6. Литералы массивов и ассоциативных массивов
Cтрока – это частный случай массива со своим синтаксисом литералов. А как представить литерал массива другого типа, например int или double? Литерал массива задается заключенным в квадратные скобки списком значений, разделенных запятыми14:
auto somePrimes = [ 2u, 3, 5, 7, 11, 13 ];
auto someDoubles = [ 1.5, 3, 4.5 ];
Размер массива вычисляется по количеству разделенных запятыми элементов списка. В отличие от строковых литералов, литералы массивов изменяемы, так что вы можете изменить их после инициализации:
auto constants = [ 2.71, 3.14, 6.023e22 ];
constants[0] = 2.21953167; // "Константа дивана"
auto salutations = [ "привет", "здравствуйте", "здорово" ];
salutations[2] = "Да здравствует Цезарь";
Обратите внимание: можно присвоить новую строку элементу массива salutations, но нельзя изменить содержимое старой строки, хранящееся в памяти. Этого и следовало ожидать, потому что членство в массиве не отменяет правил работы с типом string.
Тип элементов массива определяется «соглашением» между всеми элементами массива, которое вычисляется с помощью оператора сравнения ?: (см. раздел 2.3.16). Для литерала lit, содержащего больше одного элемента, компилятор вычисляет выражение true ? lit[0] : lit[1] и сохраняет тип этого выражения как тип L. Затем для каждого i-го элемента lit[i] до последнего элемента в lit компилятор вычисляет тип true ? L.init : lit[i] и снова сохраняет это значение в L. Конечное значение L и есть тип элементов массива.
На самом деле, все гораздо проще, чем кажется, – тип элементов массива устанавливается аналогично Польскому демократическому соглашению15: ищется тип, в который можно неявно конвертировать все элементы массива. Например, тип массива [1, 2, 2.2] – double, а тип массива [1, 2, 3u] – uint, так как результатом операции ?: с аргументами int и uint будет uint.
Литерал ассоциативного массива задается так:
auto famousNamedConstants = [ "пи" : 3.14, "e" : 2.71, "константа дивана" : 2.22 ];
Каждая ячейка литерала ассоциативного массива имеет вид ключ: значение. Тип ключей литерала ассоциативного массива вычисляется по массиву, в который неявно записываются все эти ключи, с помощью описанного выше способа. Тип значений вычисляется аналогично. После вычисления типа ключей K и типа значений V литерал типизируется как V[K]. Например, константа famousNamedConstants принимает тип double[string].
2.2.7. Функциональные литералы
В некоторых языках имя функции задается в ее определении; впоследствии такие функции вызываются по именам. Другие языки предоставляют возможность определить анонимную функцию (так называемую лямбда-функцию) прямо там, где она должна использоваться. Такое средство помогает строить мощные конструкции, задействующие функции более высокого порядка, то есть функции, принимающие в качестве аргументов и/или возвращающие другие функции. Функциональные литералы D позволяют определять анонимные функции in situ16 – когда бы ни ожидалось имя функции.
Задача этого раздела – всего лишь показать на нескольких интересных примерах, как определяются функциональные литералы. Примеры более действенного применения этого мощного средства отложим до главы 5. Вот базовый синтаксис функционального литерала:
auto f = function double(int x) { return x / 10.; };
auto a = f(5);
assert(a == 0.5);
Функциональный литерал определяется по тем же синтаксическим правилам, что и функция, с той лишь разницей, что определению предшествует ключевое слово function, а имя функции отсутствует. Рассмотренный пример в общем-то даже не использует анонимность, так как анонимная функция немедленно связывается с идентификатором f. Тип f – «указатель на функцию, принимающую int и возвращающую double». Этот тип записывается как double function(int) (обратите внимание: ключевое слово function и возвращаемый тип поменялись местами), так что эквивалентное определение f выглядит так:
double function(int) f = function double(int x) { return x / 10.; };
Кажущаяся странной перестановка function и double на самом деле сильно облегчает всем жизнь, позволяя отличить функциональный литерал по типу. Формулировка для легкого запоминания: слово function стоит в начале определения литерала, а в типе функции замещает имя функции.
Для простоты в определении функционального литерала можно опустить возвращаемый тип – компилятор определит его для вас по контексту, ведь ему тут же доступно тело функции.
auto f = function(int x) { return x / 10.; };
Наш функциональный литерал использует только собственный параметр x, так что его значение можно выяснить, взглянув лишь на тело функции и не принимая во внимание окружение, в котором она используется. Но что если функциональному литералу потребуется использовать данные, которые присутствуют в точке вызова, но не передаются как аргумент? В этом случае нужно заменить слово function словом delegate:
int c = 2;
auto f = delegate double(int x) { return c * x / 10.; };
auto a = f(5);
assert(a == 1);
c = 3;
auto b = f(5);
assert(b == 1.5);
Теперь тип f – delegate double(int x). Все правила распознавания типа для function применимы без изменений к delegate. Отсюда справедливый вопрос: если конструкции delegate могут делать все, на что способны function-конструкции (в конце концов конструкции delegate могут, но не обязаны использовать переменные своего окружения), зачем же сначала возиться с функциями? Нельзя ли всегда использовать конструкции delegate? Ответ прост: все дело в эффективности. Очевидно, что конструкции delegate обладают доступом к большему количеству информации, а по непреложному закону природы за такой доступ приходится расплачиваться. На самом деле, размер function равен размеру указателя, а delegate – в два раза больше (один указатель на функцию, один – на окружение).
2.3. Операции
В следующих главах подробно описаны все операторы D в порядке убывания приоритета. Это естественный порядок, в котором вы бы группировали и вычисляли небольшие подвыражения в группах все большего размера.
С операторами тесно связаны две независимые темы: l- и r-значения и правила преобразования чисел. Необходимые определения приведены в следующих двух разделах.
2.3.1. l-значения и r-значения
Множество операторов срабатывает только тогда, когда l-значения удовлетворяют ряду условий. Например, не нужно быть гением, чтобы понять: присваивание 5 = 10 не соответствует правилам. Для успеха присваивания необходимо, чтобы левый операнд был l-значением. Пора дать точное определение l-значения (а заодно и сопутствующего ему r-значения). Названия терминов происходят от реального положения этих значений относительно оператора присваивания. Например, в инструкции a = b значение a расположено слева от оператора присваивания, поэтому оно называется l-значением; соответственно значение b, расположенное справа, – это r-значение17.
К l-значениям относятся:
- все переменные, включая параметры функций, даже те, которые запрещено изменять (то есть определенные с квалификатором
immutable); - элементы массивов и ассоциативных массивов;
- поля структур и классов (о них мы поговорим позже);
- возвращаемые функциями значения, помеченные ключевым словом
ref; - разыменованные указатели.
Любое l-значение может выступить в роли r-значения. К r-значениям также относится все, что не вошло в этот список: литералы, перечисляемые значения (которые вводятся с помощью ключевого слова enum; см. раздел 7.3) и результаты таких выражений, как x + 5. Обратите внимание: для присваивания быть l-значением необходимо, но не достаточно – нужно успешно пройти еще несколько семантических проверок, таких как проверка прав на доступ (см. главу 6) и проверка прав на изменение (см. главу 8).
2.3.2. Неявные преобразования чисел
Мы только что коснулись темы преобразований; теперь пора рассмотреть ее подробнее. Здесь достаточно запомнить всего несколько простых правил:
- Если числовое выражение компилируется в C и также компилируется в D, то его тип будет одинаковым в обоих языках (обратите внимание: D не обязан принимать все выражения на C).
- Никакое целое значение не преобразуется к типу меньшего размера.
- Никакое значение с плавающей запятой не преобразуется неявно в целое значение.
- Любое числовое значение (целое или с плавающей запятой) неявно преобразуется к любому значению с плавающей запятой.
Правило 1 лишь незначительно усложняет работу компилятора, и это обоснованное усложнение. Поскольку D достаточно сильно «пересекается» с C и C++, это вдохновляет людей на бездумное копирование целых функций на этих языках в программы на D. Так пусть уж лучше D из соображений безопасности и переносимости отказывается время от времени от некоторых конструкций, чем если бы компилятор «проглотил» модуль из 2000 строк, а полученная программа заработала бы не так, как ожидалось, что определенно осложнило бы жизнь незадачливому программисту. Однако с помощью правила 2 язык D закручивает гайки посильнее, чем C и C++. Так что при переносе кода из этих языков на D диагностирующие сообщения время от времени будут указывать вам на «сырые» куски кода, рекомендуя вставить подходящие проверки и явные преобразования типов.
Рисунок 2.3 иллюстрирует правила преобразования для всех числовых типов. Для преобразования выбирается кратчайший путь; для двух путей одинаковой длины результаты преобразований совпадают. Независимо от количества шагов преобразование считается одношаговым процессом, преобразования неупорядочены и им не назначены приоритеты – тип или преобразуется к другому типу, или нет.
2.3.2.1. Распространение интервала значений
В соответствии с приведенными выше правилами обыкновенное число, такое как 42, будет недвусмысленно оценено как число типа int. А теперь взгляните на столь же заурядную инициализацию:
ubyte x = 42;
По неумолимым законам проверки типов вначале 42 распознается как int. Затем это число типа int будет присвоено переменной x, а это уже влечет насильственное преобразование типов. Разрешать такое грубое преобразование опасно (ведь многие значения типа int на самом деле не поместятся в ubyte). С другой стороны, требовать преобразования типов для очевидно безошибочного кода было бы очень неприятно.
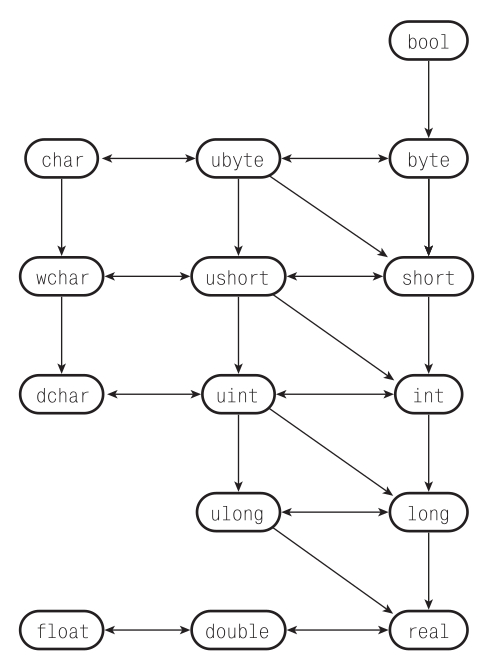
Рис. 2.3. Неявные преобразования чисел. Значение одного типа может быть автоматически преобразовано в значение другого типа тогда и только тогда, когда существует направленный путь от исходного типа до желаемого. Выбирается кратчайший путь, и преобразование считается одношаговым независимо от действительной длины пути. Преобразование в обратном направлении возможно, если оно осуществимо на основе метода распространения интервала значений (см. раздел 2.3.2.1)
Язык D элегантно разрешает эту проблему с помощью способа, прообразом которого послужила техника оптимизации компиляторов, известная как распространение интервала значений (value range propagation): каждому значению в выражении ставится в соответствие интервал с границами в виде наименьшего и наибольшего возможных значений. Эти границы отслеживаются во время компиляции. Компилятор разрешает присвоить значение некоторого типа значению более «узкого» типа тогда и только тогда, когда интервальная оценка присваиваемого значения покрывается «целевым» типом. Очевидно, что для такой константы, как 42, как наибольшим, так и наименьшим значением будет 42, поэтому для присваивания нет преград.
Конечно же, в такой типовой ситуации можно было бы использовать гораздо более простой алгоритм, однако в общем случае логично применять метод распространения интервала значений, так как он прекрасно справляется и со сложными ситуациями. Рассмотрим функцию, которая извлекает из значения типа int младший и старший байты:
void fun(int val)
{
ubyte lsByte = val & 0xFF;
ubyte hsByte = val >>> 24;
...
}
Этот код корректен независимо от того, каким будет введенное значение val. В первом выражении на значение накладывается маска, сбрасывающая все биты его старшего байта, а во втором делается сдвиг, в результате которого старший байт val перемещается на место младшего, а оставшиеся биты обнуляются.
И в самом деле, компилятор правильно типизирует функцию fun, так как сначала он вычисляет интервал val & 0xFF и получает [0; 255] независимо от val, затем вычисляет интервал для val >>> 24 и получает то же самое. Если бы вместо этих операций вы поставили операции, результат которых необязательно вместится в ubyte (например, val & 0x1FF или val >>> 23), компилятор не принял бы такой код.
Метод распространения интервала значений применим для всех арифметических и логических операций; например, значение типа uint, разделенное на 100 000, всегда вместится в ushort. Кроме того, этот метод правильно работает и со сложными выражениями, такими как маскирование, после которого следует деление. Например:
void fun(int val)
{
ubyte x = (val & 0xF0F0) / 300;
...
}
В приведенном примере оператор & устанавливает границы интервала в 0 и 0хF0F0 (то есть 61 680 в десятичной системе счисления). Затем операция деления устанавливает границы в 0 и 205. Любое число из этого диапазона вмещается в ubyte.
Определение корректности преобразований к меньшему типу по методу распространения интервала значений – несовершенный и консервативный подход. Одна из причин в том, что интервалы значений отслеживаются близоруко, внутри одного выражения, а не в нескольких смежных выражениях. Например:
void fun(int x)
{
if (x >= 0 && x < 42)
{
ubyte y = x; // Ошибка! Нельзя втиснуть int в ubyte!
...
}
}
Совершенно ясно, что инициализация не содержит ошибок, но компилятор не поймет этого. Он бы мог, но это серьезно усложнило бы реализацию и замедлило процесс компиляции. Выбор был сделан в пользу менее чувствительного распространения интервала значений в рамках одного выражения. Проведенный нами опыт показал, что такой умеренный анализ помогает программе избежать самых грубых ошибок, возникающих из-за ненадлежащего преобразования типов. Для оставшихся ошибок первого рода вы можете использовать выражения cast (см. раздел 2.3.6.7).
2.3.3. Типы числовых операций
В следующих разделах представлены операторы, применимые к числовым типам. Тип значения как результат различных операций с числами определяется с помощью нескольких правил. Это не лучшие правила, которые можно было бы придумать, но они достаточно просты, единообразны и систематичны.
В результате унарной операции всегда получается тот же тип, что и у операнда, кроме случая с оператором отрицания ! (см. раздел 2.3.6.6), применение которого всегда дает значения типа bool. Тип результата бинарных операций рассчитывается так:
- Если хотя бы один из операндов – число с плавающей запятой, то тип результата – наибольший из задействованных типов с плавающей запятой.
- Иначе если хотя бы один из операндов имеет тип
ulong, то другой операнд до выполнения операции неявно преобразуется к типуulongи результат также имеет типulong. - Иначе если хотя бы один из операндов имеет тип
long, то другой операнд до выполнения операции неявно преобразуется к типуlongи результат также имеет типlong. - Иначе если хотя бы один из операндов имеет тип
uint, то другой операнд до выполнения операции неявно преобразуется к типуuintи результат также имеет типuint. - Иначе оба операнда до выполнения операции неявно преобразуются к типу
intи результат имеет типint.
Для всех неявных преобразований выбирается кратчайший путь (см. рис. 2.3). Это важная деталь. Например:
ushort x = 60_000;
assert(x / 10 == 6000);
В операции деления 10 имеет тип int и в соответствии с указанными правилами x неявно преобразуется к типу int до выполнения операции. На рис. 2.3 есть несколько возможных путей, в том числе прямое преобразование ushort → int и более длинное (на один шаг) ushort → short → int. Второе нежелательно, так как преобразование числа 60 000 к типу short породит значение –5536, которое затем будет расширено до int и приведет инструкцию assert к ошибке. Выбор кратчайшего пути в графе преобразований помогает лучше защитить значение от порчи.
2.3.4. Первичные выражения
Первичные выражения – элементарные частицы вычислений. Нам уже встречались идентификаторы (см. раздел 2.1), логические литералы true и false (см. раздел 2.2.1), целые литералы (см. раздел 2.2.2), литералы с плавающей запятой (см. раздел 2.2.3), знаковые литералы (см. раздел 2.2.4), строковые литералы (см. раздел 2.2.5), литералы массивов (см. раздел 2.2.6) и функциональные литералы (см. раздел 2.2.7); все это первичные выражения, так же как и литерал null. В следующих разделах описаны другие первичные подвыражения: assert, mixin, is и выражения в круглых скобках.
2.3.4.1. Выражение assert
Некоторые выражения и инструкции, включая assert, используют нотацию ненулевых значений. Эти значения могут: 1) иметь числовой или знаковый тип (в этом случае смысл термина «ненулевое значение» очевиден), 2) иметь логический тип («ненулевое значение» интерпретируется как true) или 3) быть массивом, ссылкой или указателем (и тогда «ненулевым значением» считается не-null).
Выражение assert(выражение) вычисляет выражение. Если результат ненулевой, ничего не происходит. В противном случае выражение assert порождает исключение типа AssertError. Форма вызова assert(выражение, сообщение) делает сообщение (которое должно быть приводимо к типу string) частью сообщения об ошибке, хранимого внутри объекта типа AssertError (сообщение не вычисляется, если выражение ненулевое). Во всех случаях собственный тип assert – void.
Для сборки наиболее эффективного варианта программы компилятор D предоставляет специальный флаг (-release в случае эталонной реализации dmd), позволяющий игнорировать все выражения assert в компилируемом модуле (то есть вообще не вычислять выражение). Учитывая этот факт, к assert следует относиться как к инструменту отладки, а не как к средству проверки условий, поскольку оно может дать законный сбой. По той же причине некорректно использовать внутри выражений assert выражения с побочными эффектами, если поведение программы зависит от этих побочных эффектов. Более подробную информацию об итоговых сборках вы найдете в главе 11.
Ситуации, наподобие assert(false), assert(0) и других, когда функция assert вызывается с заранее известным статическим нулевым значением, обрабатываются особым образом. Такие проверки всегда в силе (независимо от значений флагов компилятора) и порождают машинный код с инструкцией HLT, которая аварийно останавливает выполнение процесса. Такое прерывание может дать операционной системе подсказку сгенерировать дамп памяти или запустить отладчик с пометкой на виновной строке.
Предвосхищая рассказ о логических выражениях с логическим ИЛИ (см. раздел 2.3.15), упомянем простейшую концептуальную идею – всегда вычислять выражение и гарантировать его результат с помощью конструкции (выражение) || assert(false).
В главе 10 подробно обсуждаются механизмы обеспечения корректности программы, в том числе выражения assert.
2.3.4.2. Выражение mixin
Если бы выражения были отвертками разных видов, выражение mixin было бы электрической отверткой со сменными насадками, регулятором скоростей, адаптером для операций на мозге, встроенной беспроводной камерой и функцией распознавания речи. Оно на самом деле такое мощное.
Короче говоря, выражение mixin позволяет вам превратить строку в исполняемый код. Синтаксис выражения выглядит как mixin(выражение), где выражение должно быть строкой, известной во время компиляции. Это ограничение исключает возможность динамически создавать программный код, например читать строку с терминала и интерпретировать ее. Нет, D – не интерпретируемый язык, и его компилятор не является частью средств стандартной библиотеки времени исполнения. Хорошие новости заключаются в том, что D на самом деле запускает полноценный интерпретатор во время компиляции, а значит, вы можете собирать строки настолько изощренными способами, насколько этого требуют условия вашей задачи.
Возможность манипулировать строками и преобразовывать их в код во время компиляции позволяет создавать так называемые предметно-ориентированные встроенные языки программирования, которые их фанаты любовно обозначают аббревиатурой DSEL18. Типичный DSEL, реализованный на D, принимал бы инструкции в качестве строковых литералов, обрабатывал их в процессе компиляции, создавал соответствующий код на D в виде строки и с помощью mixin преобразовывал ее в готовый к исполнению код на D. Хорошим примером полезных DSEL могут служить SQL-команды, регулярные выражения и спецификации грамматик (а-ля yacc). На самом деле, даже вызывая printf, вы каждый раз используете DSEL. Спецификатор формата, применяемый функцией printf, – это настоящий маленький язык, ориентированный на описание шаблонов для текстовых данных.
D позволяет вам создать какой угодно DSEL без дополнительных инструментов (таких как синтаксические анализаторы, сборщики, генераторы кода и т. д.); например, функция bitfields из стандартной библиотеки (модуль std.bitmanip) принимает определения битовых полей и генерирует оптимальный код на D для их чтения и записи, хотя сам язык не поддерживает битовые поля.
2.3.4.3. Выражения is
Выражения is отвечают на вопросы о типах («Существует ли тип Widget?» или «Наследует ли Widget от Gadget?») и являются важной частью мощного механизма интроспекции во время компиляции, реализованного в D. Все выражения is вычисляются во время компиляции и возвращают логическое значение. Как показано ниже, есть несколько видов выражения is.
1.
Выражения is(Тип) и is(Тип Идентификатор) проверяют, существует ли указанный Тип. Тип может быть недопустим или, гораздо чаще, просто не существует. Примеры:
bool
a = is(int[]), // True, int[] – допустимый тип
b = is(int[5]), // True, int[5] – также допустимый тип
c = is(int[-3]), // False, размер массива задан неверно
d = is(Blah); // False (если тип с именем Blah не был определен)
Во всех случаях Тип должен быть записан корректно с точки зрения синтаксиса, даже если запись в целом лишена смысла; например, выражение is([[]x[]]) породит ошибку во время компиляции, а не вернет значение false. Другими словами, вы можете наводить справки только о том, что синтаксически выглядит как тип.
Если присутствует Идентификатор, он становится псевдонимом типа Тип в случае истинности выражения is. Пока что неизвестная команда static if позволяет различать случаи истинности и ложности этого выражения. Подробное описание static if вы найдете в главе 3, но на самом деле все просто: static if вычисляет свое условие во время компиляции и позволяет компилировать вложенные в него инструкции, только если тестируемое выражение истинно.
static if (is(Widget[100][100] ManyWidgets))
{
ManyWidgets lotsOfWidgets;
...
}
2.
Выражения is(Тип1 == Тип2) и is(Тип1 Идентификатор == Тип2) возвращают True, если Тип1 и Тип2 идентичны. (Они могут иметь различные имена в результате применения alias.)
alias uint UInt;
assert(is(uint == UInt));
Если присутствует Идентификатор, он становится псевдонимом типа Тип1 в случае истинности выражения is.
3.
Выражения is(Тип1 : Тип2) и is(Тип1 Идентификатор : Тип2) возвращают True, если Тип1 идентичен или может быть неявно преобразован к типу Тип2. Например:
bool
a = is(int[5] : int[]), // true, int[5] может быть преобразован к int[]
b = is(int[5] == int[]), // false; это разные типы
c = is(uint : long), // true
d = is(ulong : long); // true
Аналогично, если присутствует Идентификатор, он становится псевдонимом типа Тип1 в случае истинности выражения is.
4.
Выражения is(Тип == Вид) и is(Тип Идентификатор == Вид) проверяют, принадлежит ли Тип к категории Вид. Вид – это одно из следующих ключевых слов: struct, union, class, interface, enum, function, delegate, super, const, immutable, inout, shared и return. Выражение is истинно, если Тип соответствует указанному Виду. Если присутствует Идентификатор, он должен быть задан в зависимости от значения Вид (табл. 2.4).
Таблица 2.4. Зависимости для значения Идентификатор в выражении is(Тип Идентификатор == Вид)
| Вид | Идентификатор – псевдоним для... |
|---|---|
struct |
Тип |
union |
Тип |
class |
Тип |
interface |
Тип |
enum |
Базовый тип перечисления |
function |
Кортеж типов аргументов функции |
delegate |
Функциональный тип delegate |
super |
Родительский класс |
const |
Тип |
immutable |
Тип |
inout |
Тип |
shared |
Тип |
return |
Тип, возвращаемый функцией, оператором delegate или указателем на функцию |
2.3.4.4. Выражения в круглых скобках
Круглые скобки переопределяют обычный порядок выполнения операций: для любых выражений, (<выражение>) обладает более высоким приоритетом, чем <выражение>.
2.3.5. Постфиксные операции
2.3.5.1. Доступ ко внутренним элементам
Оператор доступа ко внутренним элементам a.b предоставляет доступ к элементу с именем b, расположенному внутри объекта или типа a. Если a – сложное значение или сложный тип, допустимо заключить его в круглые скобки. В качестве b также может выступать выражение с ключевым словом new (см. главу 6).
2.3.5.2. Увеличение и уменьшение на единицу
Постфиксный вариант операции увеличения и уменьшения на единицу (значение++ и значение-- соответственно) определен для всех числовых типов и указателей и имеет тот же смысл, что и одноименная операция в C и C++: применение этой операции увеличивает или уменьшает на единицу значение (которое должно быть l-значением), возвращая копию этого значения до его изменения. (Аналогичный префиксный вариант операции увеличения и уменьшения на единицу описан в разделе 2.3.6.3.)
2.3.5.3. Вызов функции
Уже знакомый оператор вызова функции fun() инициирует выполнение кода функции fun. Синтаксис fun(<список аргументов, разделенных запятыми>) передает в тело fun список аргументов. Все аргументы вычисляются слева направо перед вызовом fun. Количество и типы значений в списке аргументов должны соответствовать количеству и типам формальных параметров. Если функция определена с атрибутом @property, то указание просто имени функции эквивалентно вызову этой функции без аргументов. Обычно fun – это имя функции, указанное в ее определении, но может быть и функциональным литералом (см. раздел 2.2.7) или выражением, возвращающим указатель на функцию или delegate. Подробно функции описаны в главе 5.
2.3.5.4. Индексация
Выражение arr[i] позволяет получить доступ к i-му элементу массива или ассоциативного массива arr (элементы массива индексируются начиная с 0). Если массив неассоциативный, то значение i должно быть целым. Иначе значение i должно иметь тип, который может быть неявно преобразован к типу ключа массива arr. Если индексирующее выражение находится слева от оператора присваивания (например, arr[i] = e) и arr – ассоциативный массив, выполняется вставка элемента в массив, если его там не было. Иначе если i относится к элементу, которого нет в массиве arr, выражение порождает исключение типа RangeError. В качестве arr и i также могут выступать указатель и целое соответственно. Операции индексации с помощью указателей автоматически не проверяются. В некоторых режимах сборки (небезопасные итоговые сборки; см. раздел 4.1.2) отменяется проверка границ и в случае неассоциативных массивов.
2.3.5.5. Срезы массивов
Если arr – линейный (неассоциативный) массив, выражение arr[i .. j] возвращает массив, ссылающийся на интервал внутри arr от i-го до j-го элемента (не включая последний). Значения i и j, отмечающие границы среза, должны допускать неявное преобразование в целое. Выражение arr[] позволяет адресовать срез массива величиной в целый массив arr. Данные не копируются «по-настоящему», поэтому изменение среза массива влечет к изменению содержимого исходного массива arr. Например:
int[] a = new int[5]; // Создать массив из пяти целых чисел
int[] b = a[3 .. 5]; // b ссылается на два последних элемента a
b[0] = 1;
b[1] = 3;
assert(a == [ 0, 0, 0, 1, 3 ]); // a был изменен
Если i > j или j > a.length, генерируется исключение типа RangeError. Иначе если i == j, будет возвращен пустой массив. В качестве arr в выражении arr[i .. j] можно использовать указатель. В этом случае будет возвращен массив, отражающий область памяти начиная с адреса arr + i до arr + j (не включая элемент с адресом arr + j). Если i > j, генерируется ошибка RangeError, иначе при получении среза указателя границы не проверяются. И снова в некоторых режимах сборки (небезопасные итоговые сборки, см. раздел 4.1.2) все проверки границ при получении срезов могут быть отключены.
2.3.5.6. Создание вложенного класса
Выражение вида a.new T, где a – значение типа class, создает объект типа T, чье определение вложено в определение a. Что-то непонятно? Это потому что мы еще не определили ни классы, ни вложенные классы, и даже сами выражения new пока не рассмотрели. Определение выражения new уже совсем близко (в разделе 2.3.6.1), а чтобы познакомиться с определениями классов и вложенных классов, придется подождать до главы 6 (точнее до раздела 6.11). А до тех пор считайте этот раздел просто заглушкой, необходимой для целостности изложения.
2.3.6. Унарные операции
2.3.6.1. Выражение new
Допустимы несколько вариантов выражения new:
new (‹адрес›)опционально ‹Тип›
new (‹адрес›)опционально ‹Тип›(‹список_аргументов›опционально)
new (‹адрес›)опционально ‹Тип›[‹список_аргументов›]
new (‹адрес›)опционально ‹Анонимный класс›
Забудем на время про необязательный (<адрес>). Два первых варианта new T и new T(<список_аргументов>опционально) динамически выделяют память для объекта типа T. Второй вариант позволяет передать аргументы конструктору T. (Формы new T и new T() тождественны друг другу и создают объект, инициализированный по умолчанию.) Мы пока что не рассматривали типы с конструкторами, поэтому давайте отложим этот разговор до главы 6, предоставляющей подробную информацию о классах (см. раздел 6.3), и главы 7, посвященной пользовательским типам (см. раздел 7.1.3). Также отложим вопрос создания анонимных классов (последний в списке вариант выражения new), см. раздел 6.11.3.
А здесь сосредоточимся на создании уже хорошо известных массивов. Выражение new T[n] выделяет непрерывную область памяти, достаточную для размещения n объектов типа T подряд, заполняет эти места значениями T.init и возвращает ссылку на них в виде значения типа T[]. Например:
auto arr = new int[4];
assert(arr.length == 4);
assert(arr == [ 0, 0, 0, 0 ]); // Инициализирован по умолчанию
Тот же результат можно получить, чуть изменив синтаксис:
auto arr = new int[](4);
На этот раз выражение интерпретируется как new T(4), где под T понимается int[]. Опять же результатом будет массив из четырех элементов, доступ к которому предоставляет переменная arr типа int[].
У второго варианта действительно больше возможностей, чем у первого. Если требуется выделить память под массив массивов, в круглых скобках можно указать несколько аргументов. Эти значения инициализируют массивы по строкам. Например, память под массив, состоящий из четырех массивов по восемь элементов, можно выделить так:
auto matrix = new int[][](4, 8);
assert(matrix.length == 4);
assert(matrix[0].length == 8);
Первая строка в рассмотренном коде заменяет более многословную запись:
auto matrix = new int[][](4);
foreach (ref row; matrix)
{
row = new int[](8);
}
Во всех рассмотренных случаях память выделяется из кучи с автоматической сборкой мусора. Память, которая больше не используется и недоступна программе, отправляется обратно в кучу. Библиотека времени исполнения из эталонной реализации предоставляет множество специализированных средств для управления памятью в модуле core.gc, в том числе изменение размера только что выделенного блока памяти и освобождение памяти вручную. Управление памятью вручную – рискованное занятие, поэтому всегда избегайте его, кроме случаев, когда это абсолютно необходимо.
Необязательный адрес, расположенный сразу после ключевого слова new, вводит конструкцию, называемую новым размещением. По смыслу вариант new(адрес) T отличается от других: вместо выделения памяти под новый объект происходит размещение объекта по заданному адресу. Такие низкоуровневые средства в обычном коде не применяются. Вы можете использовать их, например, чтобы распределять память из кучи C с помощью malloc и затем использовать ее для хранения значений языка D.
2.3.6.2. Получение адреса и разыменование
Поскольку мы еще будем говорить об указателях, сейчас упомянем лишь о парных операторах получения адреса и разыменования. Выражение &значение получает адрес значения (которое должно быть l-значением) и возвращает указатель с типом T*, если значение имеет тип T.
Обратная операция *p разыменовывает указатель, отменяя операцию получения адреса; выражение *&значение преобразуется к виду значение. Подробный разговор об указателях намеренно отложен до главы 7, потому что в D можно многого добиться и без использования указателей – низкоуровневых и опасныx средств языка.
2.3.6.3. Увеличение и уменьшение на единицу (префиксный вариант)
Выражения ++значение и --значение соответственно увеличивают и уменьшают значение (которое должно быть числом или указателем) на единицу, возвращая в качестве результата только что измененное значение.
2.3.6.4. Поразрядное отрицание
Выражение ~a инвертирует (изменяет на противоположное значение) каждый бит в a и возвращает значение того же типа, что и a. a должно быть целым числом.
2.3.6.5. Унарный плюс и унарный минус
Выражение +значение не делает ничего особенного: оператор унарный плюс включен в язык лишь из соображений сохранения целостности. Выражение -значение равносильно выражению 0 - значение; унарный минус используется только с операндом-числом.
Одна из странностей поведения унарного минуса: применив этот оператор к числу без знака, получим также число без знака (по правилам, изложенным в разделе 2.3.3), например -55u – это 4_294_967_241, то есть uint.max - 55 + 1.
То, что числа без знака на самом деле не являются натуральными, – суровая правда жизни. Для D, как и для других языков, двоичная арифметика со своими простыми правилами переполнения – неизбежная реальность, от которой пользователя не защитят никакие абстракции. Один из способов не ошибиться в трактовке выражения -значение, где значение – любое целое число, – считать его краткой записью ~значение + 1; другими словами, инвертировать каждый из разрядов значения и прибавить 1 к полученному результату. Такая процедура не вызывает вопросов, связанных с наличием знака у типа переменной значение.
2.3.6.6. Отрицание
Выражение !значение имеет тип bool и возвращает false, если значение ненулевое (определение ненулевого значения приведено в разделе 2.3.4.1), иначе возвращается true.
2.3.6.7. Приведение типов
Оператор приведения типов подобен могущественному доброму Джинну из лампы, который всегда рад выручить. При этом, как и герой мультфильма, он своенравен, чуть глуховат и не упустит случая развлечься, слишком буквально выполняя нечетко сформулированные желания, что обычно приводит к катастрофе.
Несмотря на сказанное, в редких случаях приведение типов бывает полезно, если система статической типизации недостаточно проницательна, чтобы отследить все ваши «эксплойты». Выглядит приведение типов так: cast(Тип) a.
Перечислим виды приведения типов по убыванию безопасности использования.
- Приведение ссылок – преобразование между ссылками на объекты
classиinterface. Такие приведения всегда динамически проверяются. - Приведение чисел – принудительное преобразование данных любого числового типа в данные любого другого числового типа.
- Приведение массивов – преобразование между разными типами массивов; общий размер исходного массива должен быть кратен размеру элементов целевого массива.
- Приведение указателей – преобразование указателя одного типа в указатель другого типа.
- Приведение указатель/число – перевод указателя в целый тип достаточного размера, чтобы вместить этот указатель, и наоборот.
Будьте предельно осторожны со всеми непроверяемыми приведениями типов, особенно с тремя последними, поскольку они могут нарушить целостность системы типов.
2.3.7. Возведение в степень
Синтаксис выражения возведения в степень: основание ^^ показатель (основание возводится в степень показатель). И основание, и показатель должны быть числами. То же самое делает функция pow(основание, показатель), которую можно найти в стандартных библиотеках языков C и D (обратитесь к документации для своего модуля std.math). Тем не менее запись некоторых числовых выражений действительно выигрывает от синтаксического упрощения.
Результат возведения нуля в нулевую степень – единица, а в любую другую – ноль.
2.3.8. Мультипликативные операции
К мультипликативным операциям относятся умножение (a * b), деление (a / b) и получение остатка от деления (a % b). Они применимы исключительно к числовым типам.
Если в целочисленных операциях a / b или a % b в качестве b участвует ноль, будет сгенерирована аппаратная ошибка. Дробный результат деления всегда округляется в меньшую сторону (например, в результате 7 / 3 получим 2, а результатом -7 / 3 будет -1). Операция a % b определена так, что a == (a / b) * b + a % b, поэтому в результате 7 % 3 получим 1, а результатом -7 % 3 будет -1.
В языке D также можно определить остаток от деления для чисел с плавающей запятой. Это более запутанное определение. Если в выражении a % b в качестве а или b выступает число с плавающей запятой, результатом становится наибольшее (по модулю) число с плавающей запятой r, удовлетворяющее следующим условиям:
aиrне имеют противоположных знаков;rменьшеbпо модулю, то естьabs(r) < abs(b);- существует такое целое число
q, чтоr == a - q * b.
Если такое число найти невозможно, результатом a % b будет особое значение NaN.
2.3.9. Аддитивные операции
Аддитивные операции – это сложение a + b, вычитание a - b и конкатенация a ~ b.
Сложение и вычитание применимы только к числам. Тип результата определяется в соответствии с правилами из раздела 2.3.3.
Операция конкатенации может быть применена к операндам a и b, если хотя бы один из них является массивом элементов некоторого типа T. В качестве другого операнда должен выступать либо массив элементов типа T, либо значение типа, неявно преобразуемого к типу T. В результате получается новый массив, созданный из размещенных друг за другом a и b.
2.3.10. Сдвиг
В языке D есть три операции сдвига, в каждой из которых участвуют
два целочисленных операнда: a << b, a >> b и a >>> b. Во всех случаях
значение b должно иметь тип без знака; значение со знаком необходимо
привести к значению беззнакового типа (разумеется, предварительно
убедившись, что b >= 0; результат сдвига на отрицательное количество
разрядов непредсказуем). a << b сдвигает a влево (то есть в направлении
самого старшего разряда a) на b бит, а a >> b сдвигает a вправо на b бит.
Если a – отрицательное число, знак после сдвига сохраняется.
a >>> b – это беззнаковый сдвиг независимо от знаковости a. Это означа
ет, что ноль гарантированно займет самый старший разряд a. Проил
люстрируем сюрпризы, которые готовит применение операции сдвига
к числам со знаком:
int a = -1; // То есть 0xFFFF_FFFF
int b = a << 1;
assert(b == -2); // 0xFFFF_FFFE
int с = a >> 1;
assert(c == -1); // 0xFFFF_FFFF
int d = a >>> 1;
assert(d == +2147483647); // 0x7FFF_FFFF
Сдвиг на число разрядов большее, чем в типе a, запрещается во время компиляции, если b – статически заданное, заранее известное значение. Если же b определяется во время исполнения программы, то результат такого сдвига зависит от реализации компилятора:
int a = 50;
uint b = 35;
a << 33; // Ошибка во время компиляции
auto c = a << b; // Результат зависит от реализации
auto d = a >> b; // Результат зависит от реализации
В любом случае тип результата определяется в соответствии с правилами из раздела 2.3.3.
Раньше было популярно с помощью операции сдвига реализовывать быстрое целочисленное умножение на 2 (a << 1) или деление на 2 (a >> 1) – или в общем случае умножение и деление на различные степени 2. Эта техника вышла из употребления, подобно видеокассетам. Пишите просто: a * k или a / k; если значение k известно на этапе компиляции, компилятор гарантированно сгенерирует для вас оптимальный код с операциями сдвига и всем, что еще нужно, избавив вас от волнений по поводу тонкостей работы со знаком. Не ищите сдвига на свою голову.
2.3.11. Выражения in
Если ключ – это значение типа K, a массив – ассоциативный массив типа V[K], то выражение вида ключ in массив порождает значение типа V* (указатель на V). Если ассоциативный массив содержит пару 〈ключ, значение〉, то указатель указывает на значение. В противном случае полученный указатель – null.
Для обратной, отрицательной проверки вы, конечно, можете написать !(ключ in массив), но есть и более сжатая форма – ключ !in массив – с тем же приоритетом, что и у ключ in массив.
Зачем нужны все эти сложности с указателями, когда выражение a in b может просто возвращать значение логического типа? Ответ: для эффективности. Довольно часто требуется узнать, есть ли в массиве нужный индекс, и если есть, то использовать соответствующий ему элемент. Можно написать что-то вроде:
double[string] table;
...
if ("hello" in table)
{
++table["hello"];
}
else
{
table["hello"] = 0;
}
Проблема этого кода в том, что он дважды обращается к массиву в случае, если запрошенный индекс найден. Используя возвращенный указатель, можно создавать более эффективный код, например:
double[string] table;
...
auto p = "hello" in table;
if (p)
{
++*p;
}
else
{
table["hello"] = 1;
}
2.3.12. Сравнение
2.3.12.1. Проверка на равенство
Операция вида a == b, возвращающая значение типа bool, имеет следующую семантику. Во-первых, если операнды имеют разный тип, сначала они неявно преобразуются к одному типу. Затем операнды проверяются на равенство следующим образом:
- для целых чисел и указателей выполняется точное поразрядное сравнение операндов;
- для чисел с плавающей запятой приняты правила:
-0считается равным+0, а NaN – не равным NaN19; во всех остальных случаях операнды сравниваются поразрядно; - равенство объектов типа
classопределяется с помощью оператораopEquals(см. раздел 6.8.3); - равенство массивов означает поэлементное равенство;
- по умолчанию равенство объектов типа
structопределяется как равенство всех полей операндов; пользовательские типы могут переопределять это поведение (см. главу 12).
Операция вида a != b служит для проверки на неравенство.
С помощью выражения a is b проверяется равенство ссылок (alias equality): если a и b ссылаются на один и тот же объект, выражение возвращает true:
- если
aиb– массивы или ссылки на классы, результатом будетtrue, только еслиaиb– это два имени для одного реального объекта; - в остальных случаях для
aиbдолжно быть истинно выражениеa == b.
Мы пока не касались классов, но пример с массивами может быть полезным:
import std.stdio;
void main()
{
auto a = "какая-то строка";
auto b = a; // a и b ссылаются на один и тот же массив
a is b && writeln("Ага, это действительно одно и то же.");
auto c = "какая-то (другая) строка";
a is c || writeln("Действительно... не одно и то же.");
}
Этот код печатает оба сообщения, потому что a и b связаны с одним и тем же массивом, в то время как с ссылается на другой массив. В общем случае возможно, чтобы два массива обладали одинаковым содержимым (тогда выражение a == b истинно), но они указывают на разные области памяти, поэтому проверка вида a is b вернет false. Разумеется, когда выражение a is b истинно, то и a == b также истинно (если только ваши планки оперативной памяти не куплены по дешевке).
Вместо выражения проверки на неравенство !(a is b) можно использовать его краткий вариант a !is b.
2.3.12.2. Сравнение для упорядочивания
В языке D определены стандартные логические операции вида a < b, a <= b, a > b и a >= b (меньше, меньше или равно, больше, больше или равно). При сравнении чисел одно из них должно быть неявно преобразовано к типу другого. Для операндов с плавающей запятой считается, что -0 равен 0, то есть результатом сравнения -0 < 0 будет false. Если хотя бы один из операндов равен NaN, то любая операция упорядочивающего сравнения вернет false (пусть это и кажется парадоксом).
Как обычно NaN портит добропорядочным числам с плавающей запятой весь праздник. Все сравнения, в которых участвует хотя бы одно значение NaN, порождают «исключение в операции с плавающей запятой» (floating-point exception). С точки зрения терминологии языков программирования это не совсем обычное исключение: возникает лишь особая ситуация на уровне аппаратного обеспечения, которую можно отдельно обработать. D предоставляет интерфейс для математического сопроцессора через модуль std.c.fenv.
2.3.12.3. Неассоциативность
Одно из важных свойств операторов сравнения в языке D – их неассоциативность. Любая цепочка операторов сравнения вида a <= b < c некорректна.
Простой способ определить операторы сравнения – сделать так, чтобы они возвращали значение типа bool. Возможность сравнивать логические значения друг с другом имеет не очень приятное следствие: смысл выражения a <= b < c не совпадает с привычным для маленького математика внутри нас, который то и дело пытается напомнить о себе. Вместо «b больше или равно a и меньше c» выражение будет распознано как (a <= b) < c, то есть «логический результат сравнения a <= b сравнить с c». Например, выражение 3 <= 4 < 2 было бы истинно! Такая семантика вряд ли желательна.
Можно было бы решить эту проблему, разрешив выражение a <= b < c и наделив его истинным математическим значением: a <= b && b < c, с тем чтобы b вычислялось только один раз. В языках Python и Perl 6 принята именно такая семантика, позволяющая использовать произвольные цепочки сравнений, такие как a < b == c > d < e. Но D – наследник не этих языков. Разрешение использовать выражения на C, но со слегка измененной семантикой (хотя Python и Perl 6, скорее всего, выбрали верное направление), добавило бы больше неразберихи, чем удобства, поэтому разработчики D решили просто-напросто запретить такую конструкцию.
2.3.13. Поразрядные ИЛИ, ИСКЛЮЧАЮЩЕЕ ИЛИ и И
Выражения a | b, a ^ b и a & b представляют собой поразрядные операции ИЛИ, ИСКЛЮЧАЮЩЕЕ ИЛИ и И соответственно. Перед выполнением операции вычисляются оба операнда (неполное вычисление логических выражений не допускается), даже если результат определяется уже по одному из них.
И a, и b должны быть целыми числами. Тип результата определяется в соответствии с правилами из раздела 2.3.3.
2.3.14. Логическое И
В свете вышесказанного неудивительно, что значение выражения a && b зависит от типа b.
- Если тип
bнеvoid, то результатом выражения будет логическое значение. Если операндaненулевой, вычисляетсяb, и только в том случае, если он также ненулевой, возвращаетсяtrue, иначе возвращаетсяfalse. - Если
bимеет типvoid, то и все выражение имеет типvoid. Если операндaненулевой, то вычисляется операндb. Иначеbне вычисляется.
Оператор && с выражением типа void в качестве правого операнда можно использовать в роли краткой инструкции if:
string line;
...
line == "#\n" && writeln("Успешно принята строка #. ");
2.3.15. Логическое ИЛИ
Семантика выражения a || b зависит от типа b.
- Если тип
bнеvoid, выражение имеет типbool. Если операндaненулевой, выражение возвращаетtrue. Иначе вычисляетсяb, и только в том случае, если он также ненулевой, возвращаетсяtrue. - Если
bимеет типvoid, то и все выражение имеет типvoid. Если операндaненулевой, то операндbне вычисляется. Иначеbвычисляется.
Второе правило можно применять для обработки непредсказуемых обстоятельств:
string line;
...
line.length > 0 || line = "\n";
2.3.16. Тернарная условная операция
Тернарная условная операция – это конструкция типа if-then-else с синтаксисом a ? b : c, с которой вы, возможно, знакомы. Если операнд a ненулевой, условное выражение вычисляется и возвращается b; иначе выражение вычисляется и возвращается c. Ценой героических усилий компилятор определяет наиболее «узкий» тип для b и c, который становится типом всего выражения. Этот тип (назовем его T) вычисляется с помощью простого алгоритма (показанного на примерах):
- Если
bиcодного типа, он выступает и в ролиT. - Иначе если
bиc– целые числа, сначала типы меньше 32 разрядов расширяются доint, затемTприсваивается больший тип; при одинаковых размерах приоритет имеет тип без знака. - Иначе если один операнд – целого типа, а другой – с плавающей запятой, в качестве
Tвыбирается тип с плавающей запятой. - Если оба операнда относятся к типу с плавающей запятой, то
T– наибольший из этих типов. - Иначе если типы имеют один и тот же супертип (то есть базовый тип),
Tпринимает вид этого супертипа (к этой теме мы вернемся в главе 6). - Иначе делается попытка неявно привести
cк типуbиbк типуc; если удается только что-то одно, в ролиTвыступает тип, полученный в результате удачного приведения. - Иначе выражение содержит ошибку.
Более того, если b и с одного типа и являются l-значениями, результатом также будет l-значение, что позволяет написать:
int x = 5, y = 5;
bool which = true;
(which ? x : y) += 5;
assert(x == 10);
Многие концептуальные примеры обобщенного программирования используют тернарную операцию сравнения для нахождения общего типа двух значений.
2.3.17. Присваивание
Операции присваивания имеют вид a = b или a ω= b, где буква ω выступает в качестве одного из операторов ^^, *, /, %, +, -, ~, <<, >>, >>>, |, ^ или &, а также «за обязательное использование греческих букв в книгах по программированию». С применением самостоятельных вариантов этих операторов вы уже познакомились в предыдущих разделах.
Выражение a ω= b семантически идентично выражению вида a = a ω b, однако между этими формами записи все же есть серьезное различие: в первом случае a вычисляется всего один раз (представьте, что a и b – достаточно сложные выражения, например: array[i * 5 + j] *= sqrt(x)).
Независимо от приоритета ω оператор ω= имеет тот же приоритет, что и сам оператор =, то есть ниже, чем у оператора сравнения (о котором речь шла выше), и чуть выше, чем у запятой (о которой речь пойдет ниже). Также независимо от ассоциативности ω все операторы вида ω= (в том числе =) ассоциативны слева, например a /= b = c -= d – это то же самое, что и a /= (b = (c -= d)).
2.3.18. Выражения с запятой
Выражения, разделенные запятыми, вычисляются последовательно друг за другом. Результат выражения в целом – это результат самого правого подвыражения. Например:
int a = 5;
int b = 10;
int c = (a = b, b = 7, 8);
После выполнения этого фрагмента кода переменные a, b и c примут значения 10, 7 и 8 соответственно.
2.4. Итоги и справочник
На этом мы завершаем описание богатых возможностей языка D по построению выражений. В табл. 2.5. собраны все операторы языка D. Вы можете использовать ее в качестве краткого справочника.
Таблица 2.5. Выражения D порядке убывания приоритета
| Выражение | Описание |
|---|---|
<идентификатор> |
Идентификатор (см. раздел 2.1) |
.<идентификатор> |
Идентификатор, доступный в пространстве имен модуля (в обход всех друг пространств имен) (см. раздел 2.1) |
this |
Текущий объект внутри метода (см. раздел 2.1.1) |
super |
Направляет поиск идентификаторов и динамический поиск методов в пространство имен объекта-родителя (см. раздел 2.1.1) |
$ |
Текущий размер массива (допустимо использовать $ внутри индексирующего выражения или выражения получения среза) (см. раздел 2.1.1) |
null |
«Нулевая» ссылка, массив или указатель (см. раздел 2.1.1) |
typedi(T) |
Получить объект TypeInfo, ассоциированный с T (см. раздел 2.1.1) |
true |
Логическое значение «истина» (см. раздел 2.2.1) |
false |
Логическое значение «ложь» (см. раздел 2.2.1) |
<число> |
Числовой литерал (см. раздел 2.2.2, см. раздел 2.2.3) |
<знак> |
Знаковый литерал (см. раздел 2.2.4) |
<строка> |
Строковый литерал (см. раздел 2.2.5) |
<массив> |
Литерал массива (см. раздел 2.2.6) |
<функция> |
Функциональный литерал (см. раздел 2.2.7) |
assert(a) |
В режиме отладки, если a не является ненулевым значением, выполнение программы прерывается; в режиме итоговой сборки (release) ничего не происходит (см. раздел 2.3.4.1) |
assert(a, b) |
То же, но к сообщению об ошибке добавляется b (см. раздел 2.3.4.1) |
mixin(a) |
Выражение mixin (см. раздел 2.3.4.2) |
<IsExpr> |
Выражение is (см. раздел 2.3.4.3) |
( a ) |
Выражение в круглых скобках (см. раздел 2.3.4.4) |
a.b |
Доступ к вложенным элементам (см. раздел 2.3.5.1) |
a++ |
Постфиксный вариа нт операции увеличения на единицу (см. раздел 2.3.5.2) |
a-- |
Постфиксный вариант операции уменьшения на единицу (см. раздел 2.3.5.2) |
a(<арг>опционально) |
Оператор вызова функции (<арг>опционально = необязательный список аргументов, разделенных запятыми) (см. раздел 2.3.5.3) |
a[<арг>] |
Оператор индексации (<арг> = список аргументов, разделенных запятыми) (см. раздел 2.3.5.4) |
a[] |
Срез в размере всего массива (см. раздел 2.3.5.5) |
a[b .. c] |
Срез (см. раздел 2.3.5.5) |
a.<выражение new> |
Создание экземпляра вложенного класса (см. раздел 2.3.5.6) |
&a |
Получение адреса (см. раздел 2.3.6.2) |
++a |
Префиксный вариант операции увеличения на единицу (см. раздел 2.3.6.3) |
--a |
Префиксный вариант операции уменьшения на единицу (см. раздел 2.3.6.3) |
*a |
Разыменование (см. раздел 2.3.6.2) |
-a |
Унарный минус (см. раздел 2.3.6.5) |
+a |
Унарный плюс (см. раздел 2.3.6.5) |
!a |
Отрицание (см. раздел 2.3.6.6) |
~a |
Поразрядное отрицание (см. раздел 2.3.6.4) |
(T).a |
Доступ к статическим внутренним элементам |
cast(T) a |
Приведение выражения a к типу T |
<выражение new> |
Создание объекта (см. раздел 2.3.6.1) |
a ^^ b |
Возведение в степень (см. раздел 2.3.7) |
a * b |
Умножение (см. раздел 2.3.8) |
a / b |
Деление (см. раздел 2.3.8) |
a % b |
Получение остатка от деления (см. раздел 2.3.8) |
a + b |
Сложение (см. раздел 2.3.9) |
a - b |
Вычитание (см. раздел 2.3.9) |
a ~ b |
Конкатенация(см. раздел 2.3.9) |
a << b |
Сдвиг влево (см. раздел 2.3.10) |
a >> b |
Сдвиг вправо (см. раздел 2.3.10) |
a >>> b |
Беззнаковый сдвиг вправо (старший разряд сбрасывается независимо от типа и значения a) (см. раздел 2.3.10) |
a in b |
Проверка на принадлежность для ассоциативных массивов (см. раздел 2.3.11) |
a == b |
Проверка на равенство; все операторы этой группы неассоциативны; например, выражение a == b == c некорректно (см. раздел 2.3.12.1) |
a != b |
Проверка на неравенство (см. раздел 2.3.12.1) |
a is b |
Проверка на идентичность (true, если и только если a и b ссылаются на один и тот же объект) (см. раздел 2.3.12.1) |
a !is b |
То же, что !(a is b) |
a < b |
Меньше (см. раздел 2.3.12.2) |
a <= b |
Меньше или равно (см. раздел 2.3.12.2) |
a > b |
Больше (см. раздел 2.3.12.2) |
a >= b |
Больше или равно (см. раздел 2.3.12.2) |
a | b |
Поразрядное ИЛИ (см. раздел 2.3.13) |
a ^ b |
Поразрядное ИСКЛЮЧАЮЩЕЕ ИЛИ (см. раздел 2.3.13) |
a & b |
Поразрядное И (см. раздел 2.3.13) |
a && b |
Логическое И (b может иметь тип void) (см. раздел 2.3.14) |
a || b |
Логическое ИЛИ (b может иметь тип void) (см. раздел 2.3.15) |
a ? b : c |
Тернарная условная операция; если операнд a имеет ненулевое значение, то b, иначе с (см. раздел 2.3.16) |
a = b |
Присваивание; все операторы присваивания этой группы ассоциативны справа; например a *= b += c – то же, что и a *= (b += c) (см. раздел 2.3.17) |
a += b |
Сложение «на месте»; выражения со всеми операторами вида a ω= b, работающими по принципу «вычислить и присвоить», вычисляются в следующем порядке: 1) a (должно быть l-значением), 2) b и 3) al = al ω b, где al – l-значение, получившееся в результате вычисления a |
a -= b |
Вычитание «на месте» |
a *= b |
Умножение «на месте» |
a /= b |
Деление «на месте» |
a %= b |
Получение остатка от деления «на месте» |
a &= b |
Поразрядное И «на месте» |
a |= b |
Поразрядное ИЛИ «на месте» |
a ^= b |
Поразрядное ИСКЛЮЧАЮЩЕЕ ИЛИ «на месте» |
a ~= b |
Конкатенация «на месте» (присоединение b к a) |
a <<= b |
Сдвиг влево «на месте» |
a >>= b |
Сдвиг вправо «на месте» |
a >>>= b |
Беззнаковый сдвиг вправо «на месте» |
a, b |
Последовательность выражений; выражения вычисляются слева направо, результатом операции становится самое правое выражение (см. раздел 2.3.18) |
-
Впрочем, использование нелатинских букв является дурным тоном. – Прим. науч. ред. ↩︎
-
С99 – обновленная спецификация C, в том числе добавляющая поддержку знаков Юникода. – Прим. пер. ↩︎
-
Сам язык не поддерживает восьмеричные литералы, но поскольку они присутствуют в некоторых C-подобных языках, в стандартную библиотеку был добавлен соответствующий шаблон. Теперь запись
std.conv.octal!777аналогична записи0777в C. – Прим. науч. ред. ↩︎ -
Для тех, кто готов воспринимать теорию: автоматы на рис. 2.1 и 2.2 – это детерминированные конечные автоматы (ДКА). ↩︎
-
В России в качестве разделителя целой и дробной части чисел с плавающей запятой принята запятая (поэтому и говорят: «числа с плавающей запятой»), однако в англоговорящих странах для этого служит точка, поэтому в языках программирования (обычно основанных на английском – международном языке информатики) разделителем является точка. – Прим. пер. ↩︎
-
Показатель степени 10 по-английски – exponent, поэтому для его обозначения и используется буква
e. – Прим. пер. ↩︎ -
Запись
Epозначает «умножить на 10 в степениp», то естьp– это порядок. – Прим. пер. ↩︎ -
Степень по-английски – power, поэтому показатель степени 2 обозначается буквой
p. – Прим. пер. ↩︎ -
Да, синтаксис странноватый, но D скопировал его из стандарта C99, чтобы не изобретать свою нотацию с собственными выкрутасами, которых все равно не избежать. ↩︎
-
Escape-последовательность (от англ. escape – избежать), экранирующая/управляющая последовательность – специальная комбинация знаков, отменяющая стандартную обработку компилятором следующих за ней знаков (они как бы «исключаются из рассмотрения»). – Прим. пер. ↩︎
-
WYSIWIG – акроним «What You See Is What You Get» (что видишь, то и получишь) – способ представления, при котором данные в процессе редактирования выглядят так же, как и в результате обработки каким-либо инструментом (компилятором, после отображения браузером и т. п.). – Прим. пер. ↩︎
-
Он же обратный апостроф. – Прим. науч. ред. ↩︎
-
Префиксы
wиd– от англ. wide (широкий) и double (двойной) – Прим. науч. ред. ↩︎ -
В литерале массива допустима запятая, после которой нет элемента, например [1, 2,] – длина этого массива равна 2, а последняя запятая попросту игнорируется. Это сделано для удобства автоматических генераторов кода: при генерации текста литерала массива они конкатенируют строки вида
"очередной_элемент", не обрабатывая отдельно последний элемент, запятая после которого была бы не нужна. – Прим. науч. ред. ↩︎ -
Заключенное в 1989 году соглашение между коммунистами и демократами, ознаменовавшее собой достижение компромисса между двумя партиями. В данном случае также ищется «компромиссный» тип. – Прим. пер. ↩︎
-
In situ (лат.) – на месте. – Прим. пер. ↩︎
-
От англ. left-value и right-value. – Прим. науч. ред. ↩︎
-
Domain-specific embedded language (DSEL) – предметно-ориентированный встроенный язык. – Прим. пер. ↩︎
-
Стандарт IEEE 754 определяет для чисел с плавающей запятой два разных двоичных представления для нуля: -0 и +0. Это порождает ряд неудобств, таких как исключение при сравнении чисел, рассмотренное здесь. С другой стороны, скорость многих вычислений увеличивается. Вы, скорее всего, будете редко использовать литерал
-0.0в коде на D, но это значение может получиться неявно как результат вычислений, асимптотически приближающих отрицательные значения к нулю. ↩︎