| .. | ||
| images | ||
| README.md | ||
9. Обработка ошибок
🢀 8. Квалификаторы типа 9. Обработка ошибок 10. Контрактное программирование 🢂
- 9.1. Порождение и обработка исключительных ситуаций
- 9.2. Типы
- 9.3. Блоки finally
- 9.4. Функции, не порождающие исключения (nothrow), и особая природа класса Throwable
- 9.5. Вторичные исключения
- 9.6. Раскрутка стека и код, защищенный от исключений
- 9.7. Неперехваченные исключения
Обработка ошибок – это слабо формализованная область программного инжиниринга, связанная с обработкой ожидаемых и возникших ошибочных ситуаций, способных помешать нормальному функционированию системы. Обработка исключительных ситуаций (исключений) – подход к обработке ошибок, принятый во многих современных языках (включая D) и уже успевший породить великое множество руководств, методик и, конечно, споров.
Исключения – это средство языка, реализующее обработку ошибок благодаря специальным обходным путям передачи управления. Если функции не удается вернуть вызвавшему ее коду осмысленный результат, она может породить объект исключения, в котором закодирована причина ошибки. Порождение исключений (throwing) – это карточка «Бесплатно освободитесь из тюрьмы»1, освобождающая функцию от ее обычных обязанностей. Исключение пропускает всех инициаторов вызовов, не предусматривающих его обработку, и попадает в место обработки, где и принимаются чрезвычайные меры. В хорошо спроектированной программе гораздо меньше мест обработки, чем мест порождения исключений, что способствует централизованной обработке ошибок с многократным использованием кода. Все это было бы проблематично организовать на основе традиционных методик с вездесущими кодами ошибки.
9.1. Порождение и обработка исключительных ситуаций
D использует популярную модель исключений. Функция может инициировать исключения с помощью инструкции throw (см. раздел 3.11), порождающей объект особого типа. Чтобы завладеть этим объектом, код должен использовать инструкцию try (см. раздел 3.11), где этот объект указан в блоке catch. Перефразируя пословицу, лучше один пример кода, чем 1024 слова. Так что рассмотрим пример:
import std.stdio;
void main()
{
try
{
auto x = fun();
}
catch (Exception e)
{
writeln(e);
}
}
int fun()
{
return gun() * 2;
}
int gun()
{
throw new Exception("Вернемся прямо в main");
}
Вместо того чтобы вернуть значение типа int, функция gun решает породить исключение, в данном случае это экземпляр класса Exception. В порожденном объекте можно передать любую информацию о том, что произошло. Управление передается исключительным путем (что освобождает от возвращения результата не только функцию, породившую исключение, но и всех инициаторов ее вызова) тому из инициаторов вызова, который готов обработать ошибку с помощью блока catch.
После выполнения инструкции throw функция fun полностью пропускается, поскольку она не готова обработать исключение. Вот в чем принципиальная разница между обработкой ошибок старой школы, когда ошибки вручную проводились через все уровни вызовов, и относительно новым подходом – обработкой исключений, когда управление искусно передается из места возникновения ошибки (gun) непосредственно туда, где есть все необходимое для ее обработки (блок catch в функции main). Такой подход обещает более простую, централизованную обработку ошибок, освобождая множество функций от обязанности проталкивать ошибки дальше по стеку; fun может оставаться в блаженном неведении о прямом сообщении между gun и main.
К сожалению, непосредственная передача потока управления из места порождения в место обработки – это также и слабое звено обработки исключений: на самом деле, то блаженное неведение – лишь несбыточная мечта. В действительности, функции, пересекаемые исключением, должны помнить о дополнительных неявных точках выхода и гарантировать поддержку инвариантов программы независимо от того, каким путем будет передано управление. D предоставляет надежные механизмы, обеспечивающие сохранение инвариантности при возникновении исключений. В свое время мы обсудим их в этой главе.
9.2. Типы
Базовая иерархия исключений в D проста (рис. 9.1). Инструкция throw порождает не просто какие-то значения, а только объекты-потомки класса Throwable. В подавляющем большинстве случаев код действительно порождает исключение как экземпляр потомка класса Exception, подкласса Throwable. Это обычные исключения, после которых возможно восстановление, и они распознаются языком именно так. Исключения-наследники Throwable, но не Exception (такие как AssertError; см. главу 10) относятся к фатальным ошибкам, после которых восстановление невозможно, и должны использоваться в коде крайне редко, практически никогда. (О том, что язык гарантирует в случае фатальных ошибок, а что нет, см. подробнее в разделе 9.4.)
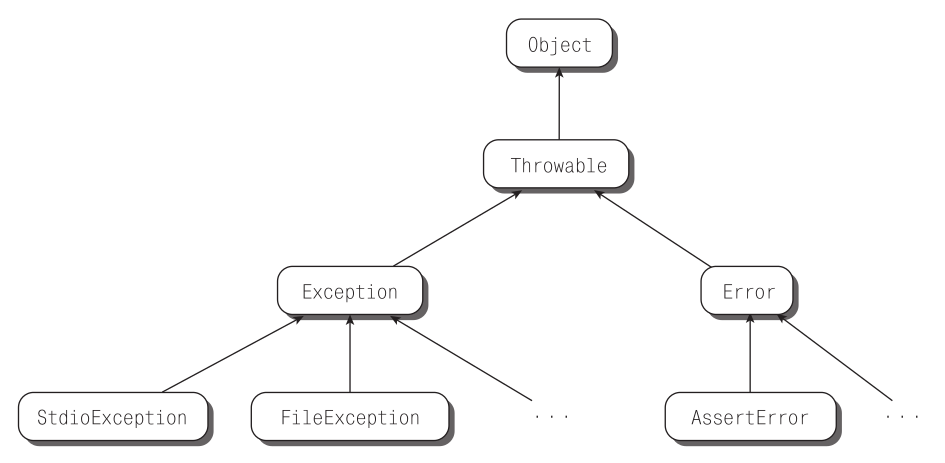
Рис. 9.1. Обычные исключения – потомки класса Exception, поэтому их можно обработать с помощью блока catch(Exception). Класс Error – прямой наследник класса Throwable. Обычный код должен перехватывать только исключения типа Exception и потомков Exception. Остальные исключения лишь позволяют аккуратно завершить работу программы в случае нахождения ошибки в ее логике
Инструкция try может определять больше одного блока catch, например:
try
{
...
}
catch (SomeException e)
{
...
}
catch (SomeOtherException e)
{
...
}
Исключения распространяются от места порождения до самого раннего места обработки, следуя правилу первого совпадения: сразу же после обнаружения блока catch, обрабатывающего исключение порожденного класса или его предка, этот блок catch активируется и порожденное исключение передается в него. Вот пример, порождающий и обрабатывающий исключения двух различных типов:
import std.stdio;
class MyException : Exception
{
this(string s) { super(s); }
}
void fun(int x)
{
if (x == 1)
{
throw new MyException("");
}
else
{
throw new StdioException("");
}
}
void main()
{
foreach (i; 1 .. 3)
{
try
{
fun(i);
}
catch (StdioException e)
{
writeln("StdioException");
}
catch (Exception e)
{
writeln("Exception");
}
}
}
Эта программа выводит на экран:
Exception
StdioException
Первый вызов fun порождает объект исключения типа MyException. При его сопоставлении с первым catch-обработчиком совпадения нет, но зато оно обнаруживается при сопоставлении со вторым блоком catch, поскольку MyException является потомком Exception. А в случае исключения, порожденного второй инструкцией throw, совпадение обнаруживается при сопоставлении с первым же catch-обработчиком. До первого совпадения этот процесс может затронуть и несколько уровней функций, как показывает следующий более замысловатый пример:
import std.stdio;
class MyException : Exception
{
this(string s) { super(s); }
}
void fun(int x)
{
if (x == 1)
{
throw new MyException("");
}
else if (x == 2)
{
throw new StdioException("");
}
else
{
throw new Exception("");
}
}
void funDriver(int x)
{
try
{
fun(x);
}
catch (MyException e)
{
writeln("MyException");
}
}
unittest
{
foreach (i; 1 .. 4)
{
try
{
funDriver(i);
}
catch (StdioException e)
{
writeln("StdioException");
}
catch (Exception e)
{
writeln("Просто Exception");
}
}
}
Эта программа выводит на экран:
MyException
StdioException
Просто Exception
поскольку обработчики в соответствии с концепцией пробуются по мере того, как поток управления всплывает вверх по стеку вызовов.
У правила первого совпадения есть очевидный недостаток. Если блок catch для исключения типа E1 расположен до блока catch для исключения типа E2 и при этом E2 является подтипом E1, то обработчик для E2 оказывается недоступным. В такой ситуации компилятор диагностирует ошибку. Например:
import std.stdio;
void fun()
{
try
{
...
}
catch (Exception e)
{
...
}
catch (StdioException e)
{
... // Ошибка!
// Недоступный обработчик catch!
}
}
Ошибочность подобного кода очевидна, но всегда есть угроза динамического маскирования между разными функциями. Любая функция легко может сделать недееспособными catch-обработчики вызвавшей ее функции. Тем не менее в большинстве случаев это не ошибка, а лишь нормальное следствие динамики стека вызовов.
9.3. Блоки finally
Инструкция try может завершаться блоком finally, что фактически означает: «Непременно выполните этот код, даже если наступит конец света или начнется потоп». Было или нет порождено исключение, блок finally будет выполнен просто как часть инструкции try, и вам решать, закончится ли это сбоем программы, порождением исключения, возвратом с помощью инструкции return или досрочным выходом из включающего цикла с помощью инструкции break. Например:
import std.stdio;
string fun(int x)
{
string result;
try
{
if (x == 1)
{
throw new Exception("некоторое исключение");
}
result = "исключение не было порождено";
return result;
}
catch (Exception e)
{
if (x == 2) throw e;
result = "исключение было порождено и обработано: " ~ e.toString;
return result;
}
finally
{
writeln("Выход из fun");
}
}
При нормальном ходе выполнения функция fun вернет некоторое значение, при исключительном – породит исключение, но в любом случае она всегда напечатает в стандартный поток вывода: Выход из fun.
9.4. Функции, не порождающие исключения (nothrow), и особая природа класса Throwable
С помощью ключевого слова nothrow можно объявить функцию, не порождающую исключения:
nothrow int iDontThrow(int a, int b)
{
return a / b;
}
Функции, не порождающие исключения, уже упоминались в разделе 5.11.2. А вот и новый поворот сюжета: атрибут nothrow обещает, что функция не породит объект типа Exception. Но у функции по-прежнему остается право порождать объекты более грозного класса Throwable. Собственно, восстановление после исключений типа Throwable считается невозможным, поэтому компилятору разрешается не «продумывать» ход событий при возникновении такого исключения, соответственно он оптимизирует код исходя из предположения, что никакого исключения нет. Для функций с атрибутом nothrow компилятор упрощает последовательности входа и выхода, не планируя экстренные мероприятия на случай, если будет порождено исключение.
Проясним и подчеркнем особый статус класса Throwable. Первое правило для исключений Throwable: исключения Throwable не обрабатывают. Решив обработать такие исключения с помощью блока catch, вы не можете рассчитывать на то, что деструкторы структур будут вызваны, а блоки finally – выполнены. Это означает, что состояние вашей системы неопределенно и может быть нарушен целый ряд высокоуровневых инвариантов, на которые вы полагаетесь при нормальном исполнении. Тем не менее D гарантирует безопасность базовых типов и целостность стандартной библиотеки. Вы не можете рассчитывать на высокоуровневую целостность состояния своего приложения, поскольку не сработало неизвестное количество кода, обеспечивающего эту целостность. Так что при обработке Throwable вам доступны только несколько простых операций. Все, что вы сможете сделать в большинстве случаев, – это вывести сообщение об ошибке в стандартный поток или в файл журнала, попытаться сохранить в отдельном файле то, что еще можно сохранить, и, стиснув зубы, достойно завершить выполнение программы насколько это возможно.
9.5. Вторичные исключения
Иногда во время обработки исключения порождается еще одно. Например:
import std.conv;
class MyException : Exception
{
this(string s) { super(s); }
}
void fun()
{
try
{
throw new Exception("порождено в fun");
}
finally
{
gun(100);
}
}
void gun(int x)
{
try
{
throw new MyException(text("порождено в gun #", x));
}
finally
{
if (x > 1)
{
gun(x - 1);
}
}
}
Что происходит, когда вызвана функция fun? Ситуация на грани непредсказуемости. Во-первых, fun пытается породить исключение, но благодаря упомянутой привилегии блока finally всегда выполняться «даже если наступит конец света или начнется потоп», gun(100) вызывается тогда же, когда из fun вылетает Exception. В свою очередь, вызов gun(100) создает исключение типа MyException с сообщением "порождено в gun #100". Назовем второе исключение вторичным, чтобы отличать его от порожденного первым, которое мы назовем первичным. Затем уже функция gun с помощью блока finally порождает добавочные вторичные исключения – ровно 100 исключений. Такой код испугал бы и самого Макиавелли.
Ввиду необходимости обрабатывать вторичные исключения язык может выбрать один из следующих вариантов поведения:
- немедленно прервать выполнение;
- продолжить распространять первичное исключение, игнорируя все вторичные;
- заменить первичное исключение вторичным и продолжить распространять его;
- продолжить в той или иной форме распространять и первичное, и все вторичные исключения.
С точки зрения сохранения информации о происходящем последний подход видится наиболее обоснованным, но и самым сложным в реализации. Например, осмысленно обработать залп исключений гораздо труднее, чем одно исключение.
D выбрал подход простой и эффективный. Всякий объект типа Throwable содержит ссылку на следующий вторичный объект типа Throwable. Этот вторичный объект доступен через свойство Throwable.next. Если вторичных исключений (больше) нет, значением свойства Throwable.next будет null. По сути, создается односвязный список с полной информацией обо всех вторичных ошибках в порядке их возникновения. В голове списка находится первичное исключение. Вот ключевые моменты определения Throwable:
class Throwable
{
this(string s);
override string toString();
@property Throwable next();
}
Разделение исключений на первичное и вторичные позволяет реализовать очень простую модель поведения. В любой момент, когда бы ни порождалось исключение, первичное исключение или уже порождено, или нет. Если нет, то порождаемое исключение становится первичным. Иначе порождаемое исключение добавляется в конец односвязного списка, головой которого является первичное исключение. Продолжив начатый выше пример, напечатаем всю цепочку исключений:
unittest
{
try
{
fun();
}
catch (Exception e)
{
writeln("Первичное исключение: исключение типа ", typeid(e), " ", e);
Throwable secondary;
while ((secondary = secondary.next) !is null)
{
writeln("Вторичное исключение: исключение типа ", typeid(e), " ", e);
}
}
}
Этот код напечатает:
Первичное исключение: исключение типа Exception порожденов fun
Вторичное исключение: исключение типа MyException порожденов gun #100
Вторичное исключение: исключение типа MyException порожденов gun #99
...
Вторичное исключение: исключение типа MyException порожденов gun #1
Вторичные исключения появляются в этой последовательности, поскольку присоединение к списку исключений выполняется в момент порождения исключения. Каждый раз инструкция throw извлекает первичное исключение (если есть), регистрирует новое исключение и инициирует или продолжает процесс порождения исключений.
Благодаря вторичным исключениям код на D может порождать исключения внутри деструкторов и блоков инструкций scope. В месте обработки исключения доступна полная информация о том, что произошло.
9.6. Раскрутка стека и код, защищенный от исключений
Пока исключение в полете, управление переносится из изначального места возникновения исключения через всю иерархию вверх до обработчика, при сопоставлении с которым происходит совпадение. Все участвующие в цепочке вызовов функции пропускаются. Ну, или почти все. Должную очистку после вызова пропускаемых функций обеспечивает так называемая раскрутка стека (stack unwinding) – часть процесса распространения исключения. Язык гарантирует, что пока исключение в полете, выполняются следующие фрагменты кода:
- деструкторы расположенных в стеке объектов-структур всех пропущенных функций;
- блоки
finallyвсех пропускаемых функций; - инструкции
scope(exit)иscope(failure), действующие на момент порождения исключения.
Раскрутка стека – бесценная помощь в обеспечении корректности программы при возникновении исключений. Программы, использующие исключения, обычно предрасположены к утечке ресурсов. Многие ресурсы рассчитаны только на использование в режиме «получить/освободить», а при порождении исключений то и дело возникают малозаметные потоки управления, «забывающие» освободить ресурсы. Такие ресурсы лучше всего инкапсулировать в структуры, которые надлежащим образом освобождают управляемые ресурсы в своих деструкторах. Эта тема уже обсуждалась в разделе 7.1.3.6, пример такой инкапсуляции – стандартный тип File из модуля std.stdio. Структура File управляет системным дескриптором файла и гарантирует, что при уничтожении объекта типа File внутренний дескриптор будет корректно закрыт. Объект типа File можно копировать; счетчик ссылок отслеживает все активные копии; копия, уничтожаемая последней, закрывает файл в его низкоуровневом представлении. Этот популярный идиоматический подход к использованию деструкторов высоко ценят программисты на C++. (Данная идиома известна как RAII, см. раздел 6.16.) Другие языки и фреймворки также используют подсчет ссылок, вручную или автоматически.
Утечка ресурсов – лишь одно из проявлений более масштабной проблемы. Иногда шаблон «выполнить/отменить» связан с ресурсом, который невозможно «пощупать». Например, при записи текста HTML-файла многие теги (например, <b>) полагается закрывать парным тегом (</b>). Нелинейный поток управления, включающий порождение исключений, может привести к генерации некорректно сформированных HTML-документов. Например:
void sendHTML(Connection conn)
{
conn.send("<html>");
... // Отправить полезную информацию в файл
conn.send("</html>");
}
Если код между двумя вызовами conn.send преждевременно прервет выполнение функции sendHTML, то закрывающий тег не будет отправлен и результатом станет некорректный поток HTML-данных. Такую же проблему могла бы вызвать инструкция return, расположенная в середине sendHTML, но return можно хотя бы увидеть невооруженным глазом, просто внимательно просмотрев тело функции. Исключение же, напротив, может быть порождено любой из функций, вызывающих sendHTML (напрямую или косвенно). Из-за этого оценка корректности sendHTML становится гораздо более сложным и трудоемким процессом. Более того, у рассматриваемого кода есть серьезные проблемы со связанностью, поскольку корректность sendHTML зависит от того, как поведет себя при порождении исключений потенциально огромное число других функций.
Одно из возможных решений – имитировать RAII (даже если никакие ресурсы не задействованы): определить структуру, которая отсылает закрывающий тег в своем деструкторе. В лучшем случае это паллиатив. На самом деле, нужно гарантировать выполнение определенного кода, а не захламлять программу типами и объектами.
Другое возможное решение – воспользоваться блоком finally:
void sendHTML(Connection conn)
{
try
{
conn.send("<html>");
...
}
finally
{
conn.send("</html>");
}
}
У этого подхода другой недостаток – масштабируемость, вернее ее отсутствие. Слабая масштабируемость finally становится очевидной, как только появляются несколько вложенных пар try/finally. Например, добавим в пример еще и отправку корректно закрытого тега <body>. Для этого потребуются два вложенных блока try/finally:
void sendHTML(Connection conn)
{
try
{
conn.send("<html>");
... // Отправить заголовок
try
{
conn.send("<body>");
... // Отправить содержимое
}
finally
{
conn.send("</body>");
}
}
finally
{
conn.send("</html>");
}
}
Тот же результат можно получить альтернативным способом – с единственным блоком finally и дополнительной переменной состояния, отслеживающей, насколько продвинулось выполнение функции:
void sendHTML(Connection conn)
{
int step = 0;
try
{
conn.send("<html>");
... // Отправить заголовок
step = 1;
conn.send("<body>");
... // Отправить содержимое
step = 2;
}
finally
{
if (step > 1) conn.send("</body>");
if (step > 0) conn.send("</html>");
}
}
При таком подходе дела обстоят куда лучше, но теперь целый кусок кода посвящен только управлению состоянием, что затуманивает истинное предназначение функции.
Такие ситуации удобнее всего обрабатывать с помощью инструкций scope. Работающая функция в какой-то момент исполнения может включать инструкцию scope. Таким образом, любые фрагменты кода, представляющие собой логические пары, окажутся еще и объединенными физически.
void sendHTML(Connection conn)
{
conn.send("<html>");
scope(exit) conn.send("</html>");
... // Отправить заголовок
conn.send("<body>");
scope(exit) conn.send("</body>");
... // Отправить содержимое
}
Новая организация кода обладает целым рядом привлекательных качеств. Во-первых, код теперь расположен линейно, без излишних вложенностей. Это позволяет легко разместить в коде сразу несколько пар типа «открыть/закрыть». Во-вторых, этот подход устраняет необходимость пристального рассмотрения кода функции sendHTML и вызываемых ею функций на предмет скрытых потоков управления, возникающих при возможном порождении исключений. В-третьих, взаимосвязанные понятия сгруппированы, что упрощает чтение и сопровождение кода. В-четвертых, код получается компактным, поскольку накладные расходы на запись инструкции scope малы.
9.7. Неперехваченные исключения
Если найти обработчик для исключения не удалось, встроенный обработчик просто выводит сообщение об исключении в стандартный поток ошибок и завершает выполнение с ненулевым кодом выхода. Эта схема работает не только для исключений, распространяемых из main, но и для исключений, порождаемых блоками static this.
Как уже говорилось, обычно исключения типа Throwable не обрабатывают. В очень редких случаях вы, возможно, все же захотите обработать Throwable и принять какие-то экстренные меры, даже если наступит конец света или начнется потоп. Но при этом не рассчитывайте на осмысленное состояние системы в целом; логика вашей программы, скорее всего, будет нарушена, так что вы уже мало что сможете сделать.
🢀 8. Квалификаторы типа 9. Обработка ошибок 10. Контрактное программирование 🢂
-
Имеется в виду карточка из игры «Монополия». – Прим. пер. ↩︎