| .. | ||
| images | ||
| README.md | ||
7. Другие пользовательские типы
🢀 6. Классы. Объектно-ориентированный стиль 7. Другие пользовательские типы 8. Квалификаторы типа 🢂
- 7.1. Структуры
- 7.1.1. Семантика копирования
- 7.1.2. Передача объекта-структуры в функцию
- 7.1.3. Жизненный цикл объекта-структуры
- 7.1.4. Статические конструкторы и деструкторы
- 7.1.5. Методы
- 7.1.6. Статические внутренние элементы
- 7.1.7. Спецификаторы доступа
- 7.1.8. Вложенность структур и классов
- 7.1.9. Структуры, вложенные в функции
- 7.1.10. Порождение подтипов в случае структур. Атрибут @disable
- 7.1.11. Взаимное расположение полей. Выравнивание
- 7.2. Объединение
- 7.3. Перечисляемые значения
- 7.4. alias
- 7.5. Параметризированные контексты (конструкция template)
- 7.6. Инъекции кода с помощью конструкции mixin template
- 7.7. Итоги
Применяя классы, основные типы и функции, можно написать много хороших программ. С параметризированными классами и функциями дело идет еще лучше. Но нередко мы с сожалением отмечаем, что по нескольким причинам классы не представляют собой инструмент с максимальной абстракцией типа.
Во-первых, классы подчиняются ссылочной семантике и из-за этого могут воплощать многие проектные решения не полностью или с ощутимыми накладными расходами. На практике трудно моделировать с помощью класса такую простую сущность, как точка с двумя или тремя координатами, если таких точек больше нескольких миллионов: разработчик оказывается перед непростым выбором – хорошая абстракция или приемлемое быстродействие. Кроме того, для линейной алгебры ссылочная семантика – большая морока. Попробуйте убедить математика или программиста-теоретика, что присваивание a = b должно делать из матрицы a лишь псевдоним матрицы b, а не отдельную копию! Даже такой простой тип, как массив, довольно накладно моделировать в виде класса в сравнении с мощной и лаконичной абстракцией массива, имеющейся в языке D (см. главу 4). Можно, конечно, сделать массивы «волшебными», но опыт то и дело показывает, что предоставлять множество «волшебных» типов, не воспроизводимых в пользовательском коде, – дурной тон и признак плохо спроектированного языка. Затраты на массив – всего два слова, а выделение памяти под экземпляр класса и использование дополнительного косвенного обращения означают большие накладные расходы по памяти и времени для всех примитивов массива. Даже такой простой тип, как int, нельзя выразить в виде класса дешево и элегантно (причем речь не об удобстве оператора). У такого класса, как BigInt, та же проблема: a = b делает нечто совершенно иное,
чем соответствующая операция присваивания для типа int.
Во-вторых, классы живут вечно, а значит, с их помощью трудно моделировать ресурсы с выраженным конечным временем жизни (такие как дескрипторы файлов, дескрипторы графического контекста, мьютексы, сокеты и т. д.). Работая с такими ресурсами как с классами, нужно постоянно быть начеку, чтобы не забыть своевременно освободить инкапсулированные ресурсы с помощью метода, вроде close или dispose. В таких случаях обычно помогает инструкция scope (см. раздел 3.13), но лучше, когда подобная контекстная семантика инкапсулирована в типе – раз и навсегда.
В-третьих, классы – это механизм для довольно «тяжелых» и высокоуровневых абстракций, то есть они не позволяют легко выражать «легковесные» абстракции вроде перечисляемых типов или псевдонимов для заданного типа.
D не был бы настоящим языком для системного программирования, если бы предоставлял для выражения абстракций только классы. Кроме классов в запасе у D есть структуры (типы-значения, сравнимые с классами по мощности, но с семантикой значения и без полиморфизма), типы enum (легковесные перечисляемые типы и простые константы), объединения (низкоуровневое хранилище с перекрыванием для разных типов) и вспомогательные механизмы определения типов, такие как alias. Все эти средства последовательно рассматриваются в этой главе.
7.1. Структуры
Структуры позволяют определять простые, инкапсулированные типы-значения. Удобная аналогия – тип int: значение типа int – это 4 байта, допускающие определенные операции. В int нет никакого скрытого состояния и никаких косвенных обращений, и две переменные типа int всегда ссылаются на разные значения1. Соглашение о структурах исключает динамический полиморфизм, переопределение методов, наследование и бесконечное время жизни. Структура – это преувеличенный тип int.
Как вы помните, класс ведет себя как ссылка (см. раздел 6.2), то есть вы всегда манипулируете объектом посредством ссылки на него, причем копирование ссылок лишь увеличивает количество ссылок на тот же объект без дублирования самого объекта. А структура – это тип-значение, то есть, по сути, ведет себя «как int»: имя жестко привязано к представленному им значению, а при копировании значения структуры на самом деле копируется целый объект, а не только ссылка.
Определяют структуру так же, как класс, за исключением следующих моментов:
- вместо ключевого слова
classиспользуется ключевое словоstruct; - свойственное классам наследование и реализация интерфейсов запрещены, то есть в определении структуры нельзя указать
:BaseTypeили:Interface, и очевидно, что внутри структуры не определена ссылкаsuper; - методы структуры нельзя переопределять – все методы являются финальными (вы можете указать в определении метода структуры ключевое слово
final, но это было бы совершенно излишне); - нельзя применять к структуре инструкцию
synchronized(см. главу 13); - структуре запрещается определять конструктор по умолчанию
this()(см. раздел 7.1.3.1); - структуре разрешается определять конструктор копирования (postblit constructor)
this(this)(см. раздел 7.1.3.4); - запрещен спецификатор доступа
protected(иначе предполагалось бы наличие структур-потомков).
Определим простую структуру:
struct Widget
{
// Константа
enum fudgeFactor = 0.2;
// Разделяемое неизменяемое значение
static immutable defaultName = "Виджет";
// Некоторое состояние, память под которое выделяется для каждого экземпляра класса Widget
string name = defaultName;
uint width, height;
// Статический метод
static double howFudgy()
{
return fudgeFactor;
}
// Метод
void changeName(string another)
{
name = another;
}
}
7.1.1. Семантика копирования
Несколько заметных на глаз различий между структурами и классами есть следствие менее очевидных семантических различий. Повторим эксперимент, который мы уже проводили, обсуждая классы в разделе 6.2. На этот раз создадим структуру и объект с одинаковыми полями, а затем сравним поведение этих типов при копировании:
class C
{
int x = 42;
double y = 3.14;
}
struct S
{
int x = 42;
double y = 3.14;
}
unittest
{
C c1 = new C;
S s1; // Никакого оператора new для S: память выделяется в стеке
auto c2 = c1;
auto s2 = s1;
c2.x = 100;
s2.x = 100;
assert(c1.x == 100); // c1 и c2 ссылаются на один и тот же объект...
assert(s1.x == 42); // ...а s2 – это настоящая копия s1
}
При работе со структурами нет никаких ссылок, которые можно привязывать и перепривязывать с помощью операций инициализации и присваивания. Каждое имя экземпляра структуры связано с отдельным значением. Как уже говорилось, объект-структура ведет себя как значение, а объект-класс – как ссылка. На рис. 7.1 показано положение дел сразу после определения c2 и s2.
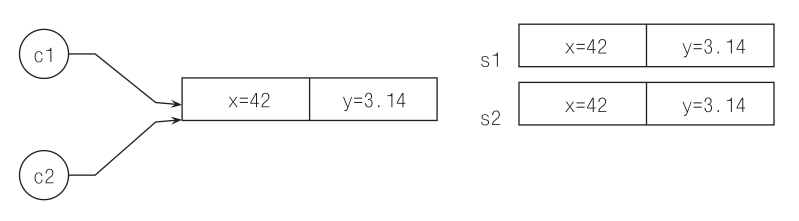
Рис. 7.1. Инструкции auto c2 = c1; для объекта-класса c1 и auto s2 = s1; для объекта-структуры s1 действуют совершенно по-разному, поскольку класс по своей природе – ссылка, а структура – значение
В отличие от имен c1 и с2, допускающих привязку к любому объекту, имена s1 и s2 прочно привязаны к реальным объектам. Нет способа заставить два имени ссылаться на один и тот же объект-структуру (кроме ключевого слова alias, задающего простую эквивалентность имен; см. раздел 7.4), и не бывает имени структуры без закрепленного за ним значения, так что сравнение s1 is null бессмысленно и порождает ошибку во время компиляции.
7.1.2. Передача объекта-структуры в функцию
Поскольку объект типа struct ведет себя как значение, он и передается в функцию по значению.
struct S
{
int a, b, c;
double x, y, z;
}
void fun(S s)
{
// fun получает копию
...
}
Передать объект-структуру по ссылке можно с помощью аргумента с ключевым словом ref (см. раздел 5.2.1):
void fun(ref S s) // fun получает ссылку
{
...
}
Раз уж мы заговорили о ref, отметим, что this передается по ссылке внутрь методов структуры S в виде скрытого параметра ref S.
7.1.3. Жизненный цикл объекта-структуры
В отличие от объектов-классов, объектам-структурам не свойственно бесконечное время жизни (lifetime). Время жизни для них четко ограничено – так же как для временных (стековых) объектов функций. Чтобы создать объект-структуру, задайте имя нужного типа, как если бы вы вызывали функцию:
import std.math;
struct Test
{
double a = 0.4;
double b;
}
unittest
{
// Чтобы создать объект, используйте имя структуры так, как используете функцию
auto t = Test();
assert(t.a == 0.4 && IsNaN(t.b));
}
Вызов Test() создает объект-структуру, все поля которого инициализированы по умолчанию. В нашем случае это означает, что поле t.a принимает значение 0.4, а t.b остается инициализированным значением double.init.
Вызовы Test(1) и Test(1.5, 2.5) также разрешены и инициализируют поля объекта в порядке их объявления. Продолжим предыдущий пример:
unittest
{
auto t1 = Test(1);
assert(t1.a == 1 && IsNaN(t1.b));
auto t2 = Test(1.5, 2.5);
assert(t2.a == 1.5 && t2.b == 2.5);
}
Поначалу может раздражать разница в синтаксисе выражения, создающего объект-структуру Test(‹аргументы›), и выражения, создающего объект-класс new Test(‹аргументы›). D мог бы отказаться от использования ключевого слова new при создании объектов-классов, но это new напоминает программисту, что выполняется операция выделения памяти (то есть необычное действие).
7.1.3.1. Конструкторы
Конструктор структуры определяется так же, как конструктор класса (см. раздел 6.3.1):
struct Test
{
double a = 0.4;
double b;
this(double b)
{
this.b = b;
}
}
unittest
{
auto t = Test(5);
}
Присутствие хотя бы одного пользовательского конструктора блокирует все упомянутые выше конструкторы, инициализирующие поля структуры:
auto t1 = Test(1.1, 1.2); // Ошибка! Нет конструктора, соответствующего вызову Test(double, double)
Есть важное исключение: компилятор всегда определяет конструктор без аргументов:
auto t2 = Test(); // Все в порядке, создается объект с "начинкой" по умолчанию
Кроме того, пользовательский код не может определить собственный конструктор без аргументов:
struct Test
{
double a = 0.4;
double b;
this() { b = 0; } // Ошибка! Структура не может определить конструктор по умолчанию!
}
Зачем нужно такое ограничение? Все из-за T.init – значения по умолчанию, определяемого каждым типом. Оно должно быть статически известно, что противоречит существованию конструктора по умолчанию, выполняющего произвольный код. (Для классов T.init – это пустая ссылка null, а не объект, построенный по умолчанию.) Правило для всех структур: конструктор по умолчанию инициализирует все поля объекта-структуры значениями по умолчанию.
7.1.3.2. Делегирование конструкторов
Скопируем пример из раздела 6.3.2 с заменой ключевого слова class на struct:
struct Widget
{
this(uint height)
{
this(1, height); // Положиться на другой конструктор
}
this(uint width, uint height)
{
this.width = width;
this.height = height;
}
uint width, height;
...
}
Код запускается, не требуя внесения каких-либо других изменений. Так же как и классы, структуры позволяют одному конструктору делегировать построение объекта другому конструктору с теми же ограничениями.
7.1.3.3. Алгоритм построения
Классу приходится заботиться о выделении динамической памяти и инициализации своего базового подобъекта (см. раздел 6.3.3). Со структурами все гораздо проще, поскольку выделение памяти – явный шаг алгоритма построения. Алгоритм построения объекта-структуры типа T по шагам:
- Скопировать значение
T.initв память, где будет размещен объект, путем копирования «сырой» памяти (а-ляmemcpy). - Вызвать конструктор, если нужно.
Если инициализация некоторых или всех полей структуры выглядит как = void, объем работ на первом шаге можно сократить, хотя и редко намного, зато такой маневр часто порождает трудноуловимые ошибки в вашем коде (тем не менее случай оправданного применения сокращенной инициализации иллюстрирует пример с классом Transmogrifier в разделе 6.3.3).
7.1.3.4. Конструктор копирования this(this)
Предположим, требуется определить объект, который содержит локальный (private) массив и предоставляет ограниченный API для манипуляции этим массивом:
struct Widget
{
private int[] array;
this(uint length)
{
array = new int[length];
}
int get(size_t offset)
{
return array[offset];
}
void set(size_t offset, int value)
{
array[offset] = value;
}
}
У класса Widget, определенного таким образом, есть проблема: при копировании объектов типа Widget между копиями создается отдаленная зависимость. Судите сами:
unittest
{
auto w1 = Widget(10);
auto w2 = w1;
w1.set(5, 100);
w2.set(5, 42); // Также изменяет элемент w1.array[5]!
assert(w1.get(5) == 100); // Не проходит!?!
}
В чем проблема? Копирование содержимого w1 в w2 «поверхностно», то есть оно выполняется поле за полем, без транзитивного копирования, на какую бы память косвенно ни ссылалось каждое из полей. При копировании массива память под новый массив не выделяется; копируются лишь границы массива (см. раздел 4.1.4). После копирования w1 и w2 действительно обладают различными полями с массивами, но ссылаются эти поля на одну и ту же область памяти. Такой объект, являющийся значением, но содержащий неявные разделяемые ссылки, можно в шутку назвать «клуктурой», то есть гибридом структуры (семантика значения) и класса (семантика ссылки)2.
Обычно требуется, чтобы структура действительно вела себя как значение, то есть чтобы копия становилась полностью независимой от своего источника. Для этого определите конструктор копирования так:
struct Widget
{
private int[] array;
this(uint length)
{
array = new int[length];
}
// Конструктор копирования
this(this)
{
array = array.dup;
}
// Как раньше
int get(size_t offset) { return array[offset]; }
void set(size_t offset, int value) { array[offset] = value; }
}
Конструктор копирования вступает в силу во время копирования объекта. Чтобы инициализировать объект приемник с помощью объекта источник того же типа, компилятор должен выполнить следующие шаги:
- Скопировать участок «сырой» памяти объекта
источникв участок «сырой» памяти объектаприемник. - Транзитивно для каждого поля, содержащего другие поля (то есть поля, содержащего другое поле, содержащее третье поле, ...), для которого определен метод
this(this), вызвать эти конструкторы снизу вверх (начиная от наиболее глубоко вложенного поля). - Вызвать метод
this(this)с объектом приемник.
Оригинальное название конструктора копирования «postblit constructor» происходит от «blit» – популярной аббревиатуры понятия «block transfer», означавшего копирование «сырой» памяти. Язык применяет «сырое» копирование при инициализации и разрешает сразу после этого воспользоваться ловушкой. В предыдущем примере конструктор копирования превращает только что полученный псевдоним массива в настоящую, полномасштабную копию, гарантируя, что с этого момента между объектом-оригиналом и объектом-копией не будет ничего общего. Теперь, после добавления конструктора копирования, модуль легко проходит этот тест:
unittest
{
auto w1 = Widget(10);
auto w2 = w1; // this(this) здесь вызывается с w2
w1.set(5, 100);
w2.set(5, 42);
assert(w1.get(5) == 100); // Пройдено
}
Вызов конструктора копирования вставляется в каждом случае копирования какого-либо объекта при явном или неявном создании новой переменной. Например, при передаче объекта типа Widget по значению в функцию также создается копия:
void fun(Widget w) // Передать по значению
{
w.set(2, 42);
}
void gun(ref Widget w) // Передать по ссылке
{
w.set(2, 42);
}
unittest
{
auto w1 = Widget(10);
w1.set(2, 100);
fun(w1); // Здесь создается копия
assert(w1.get(2) == 100); // Тест пройден
gun(w1); // А здесь копирования нет
assert(w1.get(2) == 42); // Тест пройден
}
Второй шаг (часть с «транзитивным полем») процесса конструирования при копировании заслуживает особого внимания. Основанием для такого поведения является инкапсуляция: конструктор копирования объекта-структуры должен быть вызван даже тогда, когда эта структура встроена в другую. Предположим, например, что мы решили сделать Widget членом другой структуры, которая в свою очередь является членом третьей структуры:
struct Widget2
{
Widget w1;
int x;
}
struct Widget3
{
Widget2 w2;
string name;
this(this)
{
name = name ~ " (copy)";
}
}
Теперь, если потребуется копировать объекты, содержащие другие объекты типа Widget, будет очень некстати, если компилятор забудет, как нужно копировать подобъекты типа Widget. Вот почему при копировании объектов типа Widget2 инициируется вызов конструктора this(this) для подобъекта w1, невзирая на то, что Widget2 вообще об этом ничего не знает. Кроме того, при копировании объектов типа Widget3 конструктор this(this) по-прежнему вызывается применительно к полю w1 поля w2. Внесем ясность:
unittest
{
Widget2 a;
a.w1 = Widget(10); // Выделить память под данные
auto b = a; // this(this) вызывается для b.w1
assert(a.w1.array !is b.w1.array); // Тест пройден
Widget3 c;
c.w2.w1 = Widget(20);
auto d = c; // this(this) вызывается для d.w2.w1
assert(c.w2.w1.array !is d.w2.w1.array); // Тест пройден
}
Вкратце, если вы определите для некоторой структуры конструктор копирования this(this), компилятор позаботится о том, чтобы конструктор копирования вызывался в каждом случае копирования этого объекта-структуры независимо от того, является ли он самостоятельным объектом или частью более крупного объекта-структуры.
7.1.3.5. Аргументы в пользу this(this)
Зачем был введен конструктор копирования? Ведь ничего подобного в других языках пока нет. Почему бы просто не передавать исходный объект в будущую копию (как это делает C++)?
// Это не D
struct S
{
this(S another) { ... }
// Или
this(ref S another) { ... }
}
Опыт с C++ показал, что основная причина неэффективности программ на C++ – злоупотребление копированием объектов. Чтобы сократить потери эффективности по этой причине, C++ устанавливает ряд случаев, в которых компилятор может пропускать вызов конструктора копирования (copy elision). Правила для этих случаев очень быстро усложнились, но все равно не охватывали все моменты, когда можно обойтись без конструирования, то есть проблема осталась не решенной. Развивающийся стандарт C++ затрагивает эти вопросы, определяя новый тип «ссылка на r-значение», позволяющий пользователю управлять пропусками вызова конструктора копирования, но плата за это – еще большее усложнение языка.
Благодаря конструктору копирования подход D становится простым и во многом автоматизируемым. Начнем с того, что объекты в D должны быть перемещаемыми, то есть не должны зависеть от своего расположения: копирование «сырой» памяти позволяет переместить объект в другую область памяти, не нарушая его целостность. Тем не менее это ограничение означает, что объект не может содержать так называемые внутренние указатели – адреса подобъектов, являющихся его частями. Без этой техники можно обойтись, так что D попросту ее исключает. Создавать объекты с внутренними указателями в D запрещается, и компилятор, как и подсистема времени исполнения, вправе предполагать, что это правило соблюдается. Перемещаемые объекты открывают для компилятора и подсистемы времени исполнения (например, для сборщика мусора) большие возможности, позволяющие программам стать более быстрыми и компактными.
Благодаря перемещаемости объектов копирование объектов становится логическим продолжением перемещения объектов: конструктор копирования this(this) делает копирование объектов эквивалентом перемещения с возможной последующей пользовательской обработкой. Таким образом, пользовательский код не может изменить поля исходного объекта (что очень хорошо, поскольку копирование не должно затрагивать объект-источник), но зато может корректировать поля, которые не должны неявно разделять состояние с объектом-источником. Чтобы избежать лишнего копирования, компилятор вправе по собственному усмотрению не вставлять вызов this(this), если может доказать, что источник копии не будет использован после завершения процесса копирования. Рассмотрим, например, функцию, возвращающую объект типа Widget (определенный выше) по значению:
Widget hun(uint x)
{
return Widget(x * 2);
}
unittest
{
auto w = hun(1000);
...
}
Наивный подход: просто создать объект типа Widget внутри функции hun, а затем скопировать его в переменную w, применив побитовое копирование с последующим вызовом this(this). Но это было бы слишком расточительно: D полагается на перемещаемость объектов, так почему бы попросту не переместить в переменную w уже отживший свое временный объект, созданный функцией hun? Разницу никто не заметит, поскольку после того, как функция hun вернет результат, временный объект уже не нужен. Если в лесу упало дерево и никто этого не слышит, то легче переместить его, чем копировать. Похожий (но не идентичный) случай:
Widget iun(uint x)
{
auto result = Widget(x * 2);
...
return result;
}
unittest
{
auto w = iun(1000);
...
}
В этом случае переменная result тоже уходит в небытие сразу же после того, как iun вернет управление, поэтому в вызове this(this) необходимости нет. Наконец, еще более тонкий случай:
void jun(Widget w)
{
...
}
unittest
{
auto w = Widget(1000);
... // ‹код1›
jun(w);
... // ‹код2›
}
В этом случае сложнее выяснить, можно ли избавиться от вызова this(this). Вполне вероятно, что ‹код2› продолжает использовать w, и тогда перемещение этого значения из unittest в jun было бы некорректным3.
Ввиду всех перечисленных соображений в D приняты следующие правила пропуска вызова конструктора копирования:
- Все анонимные r-значения перемещаются, а не копируются. Вызов конструктора копирования
this(this)всегда пропускается, если оригиналом является анонимное r-значение (то есть временный объект, как в функцииhunвыше). - В случае именованных временных объектов, которые создаются внутри функции и располагаются в стеке, а затем возвращаются этой функцией в качестве результата, вызов конструктора копирования
this(this)пропускается. - Нет никаких гарантий, что компилятор воспользуется другими возможностями пропустить вызов конструктора копирования.
Но иногда требуется предписать компилятору выполнить перемещение. Фактически это выполняет функция move из модуля std.algorithm стандартной библиотеки:
import std.algorithm;
void kun(Widget w)
{
...
}
unittest
{
auto w = Widget(1000);
... // ‹код1›
// Вставлен вызов move
kun(move(w));
assert(w == Widget.init); // Пройдено
... // ‹код2›
}
Вызов функции move гарантирует, что w будет перемещена, а ее содержимое будет заменено пустым, сконструированным по умолчанию объектом типа Widget. Кстати, это один из тех случаев, где пригодится неизменяемый и не порождающий исключения конструктор по умолчанию Widget.init (см. раздел 7.1.3.1). Без него сложно было бы найти способ оставить источник перемещения в строго определенном пустом состоянии.
7.1.3.6. Уничтожение объекта и освобождение памяти
Структура может определять деструктор с именем ~this():
import std.stdio;
struct S
{
int x = 42;
~this()
{
writeln("Структура S с содержимым ", x, " исчезает. Пока!");
}
}
void main()
{
writeln("Создание объекта типа S.");
{
S object;
writeln("Внутри области видимости объекта ");
}
writeln("Вне области видимости объекта");
}
Эта программа гарантированно выведет на экран:
Создание объекта типа S.
Внутри области видимости объекта
Структура S с содержимым 42 исчезает. Пока!
Вне области видимости объекта.
Каждая структура обладает временем жизни в пределах области видимости (scoped lifetime), то есть ее жизнь действительно заканчивается с окончанием области видимости объекта. Подробнее:
- время жизни нестатического объекта, определенного внутри функции, заканчивается в конце текущей области видимости (то есть контекста) до уничтожения всех объектов-структур, определенных перед ним;
- время жизни объекта, определенного в качестве члена другой структуры, заканчивается непосредственно после окончания времени жизни включающего объекта;
- время жизни объекта, определенного в контексте модуля, бесконечно; если вам нужно вызвать деструктор этого объекта, сделайте это в деструкторе модуля (см. раздел 11.3);
- время жизни объекта, определенного в качестве члена класса, заканчивается в тот момент, когда сборщик мусора забирает память включающего объекта.
Язык гарантирует автоматический вызов деструктора ~this по окончании времени жизни объекта-структуры, что очень удобно, если вы хотите автоматически выполнять такие операции, как закрытие файлов и освобождение всех важных ресурсов.
Оригинал копии, использующей конструктор копирования, подчиняется обычным правилам для времени жизни, но деструктор оригинала копии, полученной перемещением «сырой» памяти без вызова this(this), не вызывается.
Освобождение памяти объекта-структуры по идее выполняется сразу же после деструкции.
7.1.3.7. Алгоритм уничтожения структуры
По умолчанию объекты-структуры уничтожаются в порядке, строго обратном порядку их создания. То есть первым уничтожается объект-структура, определенный в заданной области видимости последним:
import std.conv, std.stdio;
struct S
{
private string name;
this(string name)
{
writeln(name, " создан.");
this.name = name;
}
~this()
{
writeln(name, " уничтожен.");
}
}
void main()
{
auto obj1 = S("первый объект");
foreach (i; 0 .. 3)
{
auto obj = S(text("объект ", i));
}
auto obj2 = S("последний объект");
}
Эта программа выведет на экран:
первый объект создан.
объект 0 создан.
объект 0 уничтожен.
объект 1 создан.
объект 1 уничтожен.
объект 2 создан.
объект 2 уничтожен.
последний объект создан.
последний объект уничтожен.
первый объект уничтожен.
Как и ожидалось, объект, созданный первым, был уничтожен последним. На каждой итерации цикл входит в контекст и выходит из контекста управляемой инструкции.
Можно явно инициировать вызов деструктора объекта-структуры с помощью инструкции clear(объект);. С функцией clear мы уже познакомились в разделе 6.3.5. Тогда она оказалась полезной для уничтожения состояния объекта-класса. Для объектов-структур функция clear делает то же самое: вызывает деструктор, а затем копирует биты значения .init в область памяти объекта. В результате получается правильно сконструированный объект, правда, без какого-либо интересного содержания.
7.1.4. Статические конструкторы и деструкторы
Структура может определять любое число статических конструкторов и деструкторов. Это средство полностью идентично одноименному средству для классов, с которым мы уже встречались в разделе 6.3.6.
import std.stdio;
struct A
{
static ~this()
{
writeln("Первый статический деструктор");
}
...
static this()
{
writeln("Первый статический конструктор ");
}
...
static this()
{
writeln("Второй статический конструктор");
}
...
static ~this()
{
writeln("Второй статический деструктор");
}
}
void main()
{
writeln("Внимание, говорит main");
}
Парность статических конструкторов и деструкторов не требуется. Подсистема поддержки времени исполнения не делает ничего интересного – просто выполняет все статические конструкторы перед вычислением функции main в порядке их определения. По завершении выполнения main подсистема поддержки времени исполнения так же скучно вызывает все статические деструкторы в порядке, обратном порядку их определения. Предыдущая программа выведет на экран:
Первый статический конструктор
Второй статический конструктор
Внимание, говорит main
Второй статический деструктор
Первый статический деструктор
Порядок выполнения очевиден для статических конструкторов и деструкторов, расположенных внутри одного модуля, но в случае нескольких модулей не всегда все так же ясно. Порядок выполнения статических конструкторов и деструкторов из разных модулей определен в разделе 6.3.6.
7.1.5. Методы
Структуры могут определять функции-члены, также называемые методами. Поскольку в случае структур о наследовании и переопределении речи нет, методы структур лишь немногим больше, чем функции.
Нестатические методы структуры S принимают скрытый параметр this по ссылке (эквивалент параметра ref S). Поиск имен внутри методов структуры производится так же, как и внутри методов класса: параметры перекрывают одноименные внутренние элементы структуры, а имена внутренних элементов структуры перекрывают те же имена, объявленные на уровне модуля.
void fun(int x)
{
assert(x != 0);
}
// Проиллюстрируем правила поиска имен
struct S
{
int x = 1;
static int y = 324;
void fun(int x)
{
assert(x == 0); // Обратиться к параметру x
assert(this.x == 1); // Обратиться к внутреннему элементу x
}
void gun()
{
fun(0); // Вызвать метод fun
.fun(1); // Вызвать функцию fun, определенную на уровне модуля
}
// Тесты модуля могут быть внутренними элементами структуры
unittest
{
S obj;
obj.gun();
assert(y == 324); // Тесты модуля, являющиеся "внутренними элементами", видят статические данные
}
}
Кроме того, в этом примере есть тест модуля, определенный внутри структуры. Такие тесты модуля, являющиеся «внутренними элементами», не наделены никаким особым статусом, но их очень удобно вставлять после каждого определения метода. Коду тела внутреннего теста модуля доступна та же область видимости, что и обычным статическим методам: например, тесту модуля в предыдущем примере не требуется снабжать статическое поле y префиксом S, как это не потребовалось бы любому методу структуры.
Некоторые особые методы заслуживают более тщательного рассмотрения. К ним относятся оператор присваивания opAssign, используемый оператором =, оператор равенства opEquals, используемый операторами == и !=, а также упорядочивающий оператор opCmp, используемый операторами <, <=, >= и >. На самом деле, эта тема относится к главе 12, так как затрагивает вопрос перегрузки операторов, но эти операторы особенные: компилятор может сгенерировать их автоматически, со всем их особым поведением.
7.1.5.1. Оператор присваивания
По умолчанию, если задать:
struct Widget { ... } // Определен так же, как в разделе 7.1.3.4
Widget w1, w2;
...
w1 = w2;
то присваивание делается через копирование всех внутренних элементов по очереди. В случае типа Widget такой подход может вызвать проблемы, о которых говорилось в разделе 7.1.3.4. Если помните, структура Widget обладает внутренним локальным массивом типа int[], и планировалось, что он будет индивидуальным для каждого объекта типа Widget. В ходе последовательного присваивания полей объекта w2 объекту w1 поле w2.array будет присвоено полю w1.array, но это будет только простое присваивание границ массива – в действительности, содержимое массива скопировано не будет. Этот момент необходимо подкорректировать, поскольку на самом деле мы хотим создать дубликат массива оригинальной структуры и присвоить его целевой структуре.
Пользовательский код может перехватить присваивание, определив метод opAssign. По сути, если lhs определяет opAssign с совместимой сигнатурой, присваивание lhs = rhs транслируется в lhs.opAssign(rhs), иначе если lhs и rhs имеют один и тот же тип, выполняется обычное присваивание поле за полем. Давайте определим метод Widget.opAssign:
struct Widget
{
private int[] array;
... // this(uint), this(this), и т. д.
ref Widget opAssign(ref Widget rhs)
{
array = rhs.array.dup;
return this;
}
}
Оператор присваивания возвращает ссылку на this, тем самым позволяя создавать цепочки присваиваний а-ля w1 = w2 = w3, которые компилятор заменяет на w1.opAssign(w2.opAssign(w3)).
Осталась одна проблема. Рассмотрим присваивание:
Widget w;
...
w = Widget(50); // Ошибка! Невозможно привязать r-значение типа Widget к ссылке ref Widget!
Проблема в том, что метод opAssign в таком виде, в каком он определен сейчас, ожидает аргумент типа ref Widget, то есть l-значение типа Widget. Чтобы помимо l-значений можно было бы присваивать еще и r-значения, структура Widget должна определять два оператора присваивания:
import std.algorithm;
struct Widget
{
private int[] array;
... // this(uint), this(this), и т. д.
ref Widget opAssign(ref Widget rhs)
{
array = rhs.array.dup;
return this;
}
ref Widget opAssign(Widget rhs)
{
swap(array, rhs.array);
return this;
}
}
В версии метода, принимающей r-значения, уже отсутствует обращение к свойству .dup. Почему? Ну, r-значение (а с ним и его массив) – это практически собственность второго метода opAssign: оно было скопировано перед входом в функцию и будет уничтожено сразу же после того, как функция вернет управление. Это означает, что больше нет нужды дублировать rhs.array, потому что его потерю никто не ощутит. Достаточно лишь поменять местами rhs.array и this.array. Функция opAssign возвращает результат, и rhs и старый массив объекта this уходят в никуда, а this остается с массивом, ранее принадлежавшим rhs, – совершенное сохранение состояния.
Теперь можно совсем убрать первую перегруженную версию оператора opAssign: та версия, что принимает rhs по значению, заботится обо всем сама (l-значения автоматически конвертируются в r-значения). Но оставив версию с l-значением, мы сохраняем точку, через которую можно оптимизировать работу оператора присваивания. Вместо того чтобы дублировать структуру-оригинал с помощью свойства .dup, метод opAssign может проверять, достаточно ли в текущем массиве места для размещения нового содержимого, и если да, то достаточно и записи поверх старого массива на том же месте.
// Внутри Widget ...
ref Widget opAssign(ref Widget rhs)
{
if (array.length < rhs.array.length)
{
array = rhs.array.dup;
}
else
{
// Отрегулировать длину
array.length = rhs.array.length;
// Скопировать содержимое массива array (см. раздел 4.1.7)
array[] = rhs.array[];
}
return this;
}
7.1.5.2. Сравнение структур на равенство
Средство для сравнения объектов-структур предоставляется «в комплекте» – это операторы == и !=. Сравнение представляет собой поочередное сравнение внутренних элементов объектов и возвращает false, если хотя бы два соответствующих друг другу элемента сравниваемых объектов не равны, иначе результатом сравнения является true.
struct Point
{
int x, y;
}
unittest
{
Point a, b;
assert(a == b);
a.x = 1;
assert(a != b);
}
Чтобы определить собственный порядок сравнения, определите метод
opEquals:
import std.math, std.stdio;
struct Point
{
float x = 0, y = 0;
// Добавлено
bool opEquals(ref const Point rhs) const
{
// Выполнить приблизительное сравнение
return approxEqual(x, rhs.x) && approxEqual(y, rhs.y);
}
}
unittest
{
Point a, b;
assert(a == b);
a.x = 1e-8;
assert(a == b);
a.y = 1e-1;
assert(a != b);
}
По сравнению с методом opEquals для классов (см. раздел 6.8.3) метод opEquals для структур гораздо проще: ему не нужно беспокоиться о корректности своих действий из-за наследования. Компилятор попросту заменяет сравнение объектов-структур на вызов метода opEquals. Конечно, применительно к структурам остается требование определять осмысленный метод opEquals: рефлексивный, симметричный и транзитивный. Заметим, что хотя метод Point.opEquals выглядит довольно осмысленно, он не проходит тест на транзитивность. Лучшим вариантом оператора сравнения на равенство было бы сравнение двух объектов типа Point, значения координат которых предварительно усечены до своих старших разрядов. Такую проверку было бы гораздо проще сделать транзитивной.
Если структура содержит внутренние элементы, определяющие методы opEquals, а сама такой метод не определяет, при сравнении все равно будут вызваны существующие методы opEquals внутренних элементов. Продолжим работать с примером, содержащим структуру Point:
struct Rectangle
{
Point leftBottom, rightTop;
}
unittest
{
Rectangle a, b;
assert(a == b);
a.leftBottom.x = 1e-8;
assert(a == b);
a.rightTop.y = 5;
assert(a != b);
}
Для любых двух объектов a и b типа Rectangle вычисление a == b эквивалентно вычислению выражения
a.leftBottom == b.leftBottom && a.rightTop == b.rightTop
что в свою очередь можно переписать так:
a.leftBottom.opEquals(b.leftBottom) && a.rightTop.opEquals(b.rightTop)
Этот пример также показывает, что сравнение выполняется в порядке объявления полей (т. е. поле leftBottom проверяется до проверки rightTop), и если встретились два неравных поля, сравнение завершается до того, как будут проверены все поля, благодаря сокращенному вычислению логических связок, построенных с помощью оператора && (short circuit evaluation).
7.1.6. Статические внутренние элементы
Структура может определять статические данные и статические внутренние функции. Помимо ограниченной видимости и подчинения правилам доступа (см. раздел 7.1.7) режим работы статических внутренних функций ничем не отличается от режима работы обычных функций. Нет скрытого параметра this, не вовлечены никакие другие особые механизмы.
Точно так же статические данные схожи с глобальными данными, определенными на уровне модуля (см. раздел 5.2.4), во всем, кроме видимости и ограничений доступа, наложенных на эти статические данные родительской структурой.
import std.stdio;
struct Point
{
private int x, y;
private static string formatSpec = "(%s %s)\n";
static void setFormatSpec(string newSpec)
{
... // Проверить корректность спецификации формата
formatSpec = newSpec;
}
void print()
{
writef(formatSpec, x, y);
}
}
void main()
{
auto pt1 = Point(1, 2);
pt1.print();
// Вызвать статическую внутреннюю функцию, указывая ее принадлежность префиксом Point или pt1
Point.setFormatSpec("[%s, %s]\n");
auto pt2 = Point(5, 3);
// Новая спецификация действует на все объекты типа Point
pt1.print();
pt2.print();
}
Эта программа выведет на экран:
(1 2)
[1, 2]
[5, 3]
7.1.7. Спецификаторы доступа
Структуры подчиняются спецификаторам доступа private (см. раздел 6.7.1), package (см. раздел 6.7.2), public (см. раздел 6.7.4) и export (см. раздел 6.7.5) тем же образом, что и классы. Спецификатор protected применительно к структурам не имеет смысла, поскольку структуры не поддерживают наследование.
За подробной информацией обратитесь к соответствующим разделам. А здесь мы лишь вкратце напомним смысл спецификаторов:
struct S
{
private int a; // Доступен в пределах текущего файла и в методах S
package int b; // Доступен в пределах каталога текущего файла
public int c; // Доступен в пределах текущего приложения
export int d; // Доступен вне текущего приложения (там, где оно используется)
}
Заметим, что хотя ключевое слово export разрешено везде, где синтаксис допускает применение спецификатора доступа, семантика этого ключевого слова зависит от реализации.
7.1.8. Вложенность структур и классов
Часто бывает удобно вложить в структуру другую структуру или класс. Например, контейнер дерева можно представить как оболочку-структуру с простым интерфейсом поиска, а внутри нее для определения узлов дерева использовать полиморфизм.
struct Tree
{
private:
class Node
{
int value;
abstract Node left();
abstract Node right();
}
class NonLeaf : Node
{
Node _left, _right;
override Node left() { return _left; }
override Node right() { return _right; }
}
class Leaf : Node
{
override Node left() { return null; }
override Node right() { return null; }
}
// Данные
Node root;
public:
void add(int value) { ... }
bool search(int value) { ... }
}
Аналогично структура может быть вложена в другую структуру...
struct Widget
{
private:
struct Field
{
string name;
uint x, y;
}
Field[] fields;
public:
...
}
...и наконец, структура может быть вложена в класс.
class Window
{
struct Info
{
string name;
Window parent;
Window[] children;
}
Info getInfo();
...
}
В отличие от классов, вложенных в другие классы, вложенные структуры и классы, вложенные в другие структуры, не обладают никаким скрытым внутренним элементом outer – никакой специальный код не генерируется. Такие вложенные типы определяются в основном со структурной целью – чтобы получить нужное управление доступом.
7.1.9. Структуры, вложенные в функции
Вспомним, что говорилось в разделе 6.11.1: вложенные классы находятся в привилегированном положении, ведь они обладают особыми, уникальными свойствами. Вложенному классу доступны параметры и локальные переменные включающей функции. Если вы возвращаете вложенный класс в качестве результата функции, компилятор даже размещает кадр функции в динамической памяти, чтобы параметры и локальные переменные функции выжили после того, как она вернет управление.
Для единообразия и согласованности D оказывает структурам, вложенным в функции, те же услуги, что и классам, вложенным в функции. Вложенная структура может обращаться к параметрам и локальным переменным включающей функции:
void fun(int a)
{
int b;
struct Local
{
int c;
int sum()
{
// Обратиться к параметру, переменной и собственному внутреннему элементу структуры Local
return a + b + c;
}
}
Local obj;
int x = obj.sum();
// (void*).sizeof – размер указателя на окружение
// int.sizeof – размер единственного поля структуры
assert(Local.sizeof == (void*).sizeof + int.sizeof);
}
unittest
{
fun(5);
}
Во вложенные структуры встраивается волшебный «указатель на кадр», с помощью которого они получают доступ к внешним значениям, таким как a и b в этом примере. Из-за этого дополнительного состояния размер объекта Local не 4 байта, как можно было ожидать, а 8 (на 32-раз рядной машине) – еще 4 байта занимает указатель на кадр. Если хотите определить вложенную структуру без этого багажа, просто добавьте в определение структуры Local ключевое слово static перед ключевым словом struct – тем самым вы превратите Local в обычную структуру, то есть закроете для нее доступ к a и b.
Вложенные структуры практически бесполезны, разве что, по сравнению со вложенными классами, позволяют избежать беспричинного ограничения. Функции не могут возвращать объекты вложенных структур, так как вызывающему их коду недоступна информация о типах таких объектов. Используя замысловатые вложенные структуры, код неявно побуждает создавать все больше сложных функций, а в идеале именно этого надо избегать в первую очередь.
7.1.10. Порождение подтипов в случае структур. Атрибут @disable
К структурам неприменимы наследование и полиморфизм, но этот тип данных по-прежнему поддерживает конструкцию alias this, впервые представленную в разделе 6.13. С помощью alias this можно сделать структуру подтипом любого другого типа. Определим, к примеру, простой тип Final, поведением очень напоминающий ссылку на класс – во всем, кроме того что переменную типа Final невозможно перепривязать! Пример использования переменной Final:
import std.stdio;
class Widget
{
void print()
{
writeln("Привет, я объект класса Widget. Вот, пожалуй, и все обо мне.");
}
}
unittest
{
auto a = Final!Widget(new Widget);
a.print(); // Все в порядке, просто печатаем a
auto b = a; // Все в порядке, a и b привязаны к одному и тому же объекту типа Widget
a = b; // Ошибка! opAssign(Final!Widget) деактивизирован!
a = new Widget; // Ошибка! Невозможно присвоить значение r-значению, возвращенному функцией get()!
}
Предназначение типа Final – быть особым видом ссылки на класс, раз и навсегда привязанной к одному объекту. Такие «преданные» ссылки полезны для реализации множества проектных идей.
Первый шаг – избавиться от присваивания. Проблема в том, что оператор присваивания генерируется автоматически, если не объявлен пользователем, поэтому структура Final должна вежливо указать компилятору не делать этого. Для этого предназначен атрибут @disable:
struct Final(T)
{
// Запретить присваивание
@disable void opAssign(Final);
...
}
С помощью атрибута @disable можно запретить и другие сгенерированные функции, например сравнение.
До сих пор все шло хорошо. Чтобы реализовать Final!T, нужно с помощью конструкции alias this сделать Final(T) подтипом T, но чтобы при этом полученный тип не являлся l-значением. Ошибочное решение выглядит так:
// Ошибочное решение
struct Final(T)
{
private T payload;
this(T bindTo)
{
payload = bindTo;
}
// Запретить присваивание
@disable void opAssign(Final);
// Сделать Final(T) подклассом T
alias payload this;
}
Структура Final хранит ссылку на себя в поле payload, которое инициализируется в конструкторе. Кроме того, объявив, но не определяя метод opAssign, структура эффективно «замораживает» присваивание. Таким образом, клиентский код, пытающийся присвоить значение объекту типа Final!T, или не сможет обратиться к payload (из-за private), или получит ошибку во время компоновки.
Ошибка Final – в использовании инструкции alias payload this;. Этот тест модуля делает что-то непредусмотренное:
class A
{
int value = 42;
this(int x) { value = x; }
}
unittest
{
auto v = Final!A(new A(42));
void sneaky(ref A ra)
{
ra = new A(4242);
}
sneaky(v); // Хм-м-м...
assert(v.value == 4242); // Проходит?!?
}
alias payload this действует довольно просто: каждый раз, когда значение объект типа Final!T используется в недопустимом для этого типа контексте, компилятор вместо объект пишет объект.payload (то есть делает объект.payload псевдонимом для объекта в соответствии с именем и синтаксисом конструкции alias). Но выражение объект.payload представляет собой непосредственное обращение к полю объект, следовательно, является l-значением. Это l-значение привязано к переданному по ссылке параметру функции sneaky и, таким образом, позволяет sneaky напрямую изменять значение поля объекта v.
Чтобы это исправить, нужно сделать объект псевдонимом r-значения. Так мы получим полную функциональность, но ссылка, сохраненная в payload, станет неприкосновенной. Очень просто осуществить привязку к r-значению с помощью свойства (объявленного с атрибутом @property), возвращающего payload по значению:
struct Final(T)
{
private T payload;
this(T bindTo)
{
payload = bindTo;
}
// Запретить присваивание, оставив метод opAssign неопределенным
private void opAssign(Final);
// Сделать Final(T) подклассом T, не разрешив при этом перепривязывать payload
@property T get() { return payload; }
alias get this;
}
Ключевой момент в новом определении структуры – то, что метод get возвращает значение типа T, а не ref T. Конечно, объект, на который ссылается payload, изменить можно (если хотите избежать этого, ознакомьтесь с квалификаторами const и immutable; см. главу 8). Но структура Final свои обязательства теперь выполняет. Во-первых, для любого типа класса T справедливо, что Final!T ведет себя как T. Во-вторых, однажды привязав переменную типа Final!T к некоторому объекту с помощью конструктора, вы не сможете ее перепривязать ни к какому другому объекту. В частности, тест модуля, из-за которого пришлось отказаться от предыдущего определения Final, больше не компилируется, поскольку вызов sneaky(v) теперь некорректен: r-значение типа A (неявно полученное из v с помощью v.get) не может быть привязано к ref A, как требуется функции sneaky для ее черных дел.
В нашей бочке меда осталась только одна ложка дегтя (на самом деле, всего лишь чайная ложечка), от которой надо избавиться. Всякий раз, когда тип, подобный Final, использует конструкцию alias get this, необходимо уделять особое внимание собственным идентификаторам Final, перекрывающим одноименные идентификаторы, определенные в типе, псевдонимом которого становится Final. Предположим, мы используем тип Final!Widget, а класс Widget и сам определяет свойство get:
class Widget
{
private int x;
@property int get() { return x; }
}
unittest
{
auto w = Final!Widget(new Widget);
auto x = w.get; // Получает Widget из Final, а не int из Widget
}
Чтобы избежать таких коллизий, воспользуемся соглашением об именовании. Для надежности будем просто добавлять к именам видимых свойств имя соответствующего типа:
struct Final(T)
{
private T Final_payload;
this(T bindTo)
{
Final_payload = bindTo;
}
// Запретить присваивание
@disable void opAssign(Final);
// Сделать Final(T) подтипом T, не разрешив при этом перепривязывать payload
@property T Final_get() { return Final_payload; }
alias Final_get this;
}
Соблюдение такого соглашения сводит к минимуму риск непредвиденных коллизий. (Конечно, иногда можно намеренно перехватывать некоторые методы, оставив вызовы к ним за перехватчиком.)
7.1.11. Взаимное расположение полей. Выравнивание
Как располагаются поля в объекте-структуре? D очень консервативен в отношении структур: он располагает элементы их содержимого в том же порядке, в каком они указаны в определении структуры, но сохраняет за собой право вставлять между полями отступы (padding). Рассмотрим пример:
struct A
{
char a;
int b;
char c;
}
Если бы компилятор располагал поля в точном соответствии с размерами, указанными в структуре A, то адресом поля b оказался бы адрес объекта A плюс 1 (поскольку поле a типа char занимает ровно 1 байт). Но такое расположение проблематично, ведь современные компьютерные системы извлекают данные только блоками по 4 или 8 байт, то есть могут извлекать только данные, расположенные по адресам, кратным 4 и 8 соответственно. Предположим, объект типа A расположен по «хорошему» адресу, например кратному 8. Тогда адрес поля b точно окажется не в лучшем районе города. Чтобы извлечь b, процессору придется повозиться, ведь нужно будет «склеивать» значение b, собирая его из кусочков размером в байт. Усугубляет ситуацию то, что в зависимости от компилятора и низкоуровневой архитектуры аппаратного обеспечения эта операция сборки может быть выполнена лишь в ответ на прерывание ядра «обращение к невыровненным данным», обработка которого требует своих (и немалых) накладных расходов. А это вам не семечки щелкать: такая дополнительная гимнастика легко снижает скорость доступа на несколько порядков.
Вот почему современные компиляторы располагают данные в памяти с отступами. Компилятор вставляет в объект дополнительные байты, чтобы обеспечить расположение всех полей с удобными смещениями. Таким образом, выделение под объекты областей памяти с адресами, кратными слову, гарантирует быстрый доступ ко всем внутренним элементам этих объектов. На рис. 7.2 показано расположение полей типа A по схеме с отступами.

Рис. 7.2. Расположение полей типа A по схеме с отступами. Заштрихованные области – это отступы, вставленные для правильного выравнивания. Компилятор вставляет в объект две лакуны, тем самым добавляя 6 байт простаивающего места или 50% общего размера объекта
Полученное расположение полей характеризуется обилием отступов (заштрихованных областей). В случае классов компилятор волен упорядочивать поля по собственному усмотрению, но при работе со структурой есть смысл позаботиться о расположении данных, если объем используемой памяти имеет значение. Лучше всего расположить поле типа int первым, а после него – два поля типа char. При таком порядке полей структура займет 64 бита, включая 2 байта отступа.
Каждое из полей объекта обладает известным во время компиляции смещением относительно начального адреса объекта. Это смещение всегда одинаково для всех объектов заданного типа в рамках одной программы (оно может меняться от компиляции к компиляции, но не от запуска к запуску). Смещение доступно пользовательскому коду как значение свойства .offsetof, неявно определенного для каждого поля класса или структуры:
import std.stdio;
struct A
{
char a;
int b;
char c;
}
void main()
{
A x;
writefln("%s %s %s", x.a.offsetof, x.b.offsetof, x.c.offsetof);
}
Эталонная реализация компилятора выведет 0 4 8, открывая схему расположения полей, которую мы уже видели на рис. 7.2. Не совсем удобно, что для доступа к некоторой статической информации о типе A приходится создавать объект этого типа, но синтаксис A.a.offsetof не компилируется. Здесь поможет такой трюк: выражение A.init.a.offsetof позволяет получить смещение для любого внутреннего элемента структуры в виде константы, известной во время компиляции.
import std.stdio;
struct A
{
char a;
int b;
char c;
}
void main()
{
// Получить доступ к смещениям полей, не создавая объект
writefln("%s %s %s", A.init.a.offsetof,
A.init.b.offsetof, A.init.c.offsetof);
}
D гарантирует, что все байты отступов последовательно заполняются нулями.
7.1.11.1. Атрибут align
Чтобы перекрыть выбор компилятора, определив собственное выравнивание, что повлияет на вставляемые отступы, объявляйте поля с атрибутом align. Такое переопределение может понадобиться для взаимодействия с определенной аппаратурой или для работы по бинарному протоколу, задающему особое выравнивание. Пример атрибута align в действии:
class A
{
char a;
align(1) int b;
char c;
}
При таком определении поля структуры A располагаются без пустот между ними. (В конце объекта при этом может оставаться зарезервированное, но не занятое место.) Аргумент атрибута align означает максимальное выравнивание поля, но реальное выравнивание не может превысить естественное выравнивание для типа этого поля. Получить естественное выравнивание типа T позволяет определенное компилятором свойство T.alignof. Если вы, например, укажете для b выравнивание align(200) вместо указанного в примере align(1), то реально выравнивание примет значение 4, равное int.alignof.
Атрибут align можно применять к целому классу или структуре:
align(1) struct A
{
char a;
int b;
char c;
}
Для структуры атрибут align устанавливает выравнивание по умолчанию заданным значением. Это умолчание можно переопределить индивидуа льными атрибутами align внутри структуры. Если для поля типа T указать только ключевое слово align без числа, компилятор прочитает это как align(T.alignof), то есть такая запись переустанавливает выравнивание поля в его естественное значение.
Атрибут align не предназначен для использования с указателями и ссылками. Сборщик мусора действует из расчета, что все ссылки и указатели выровнены по размеру типа size_t. Компилятор не настаивает на соблюдении этого ограничения, поскольку в общем случае у вас могут быть указатели и ссылки, не контролируемые сборщиком мусора. Таким образом, следующее определение крайне опасно, поскольку компилируется без предупреждений:
struct Node
{
short value;
align(2) Node* next; // Избегайте таких определений
}
Если этот код выполнит присваивание объект.next = new Node (то есть заполнит объект.next ссылкой, контролируемой сборщиком мусора), хаос обеспечен: неверно выровненная ссылка пропадает из поля зрения сборщика мусора, память может быть освобождена, и объект.next превращается в «висячий» указатель.
7.2. Объединение
Объединения в стиле C можно использовать и в D, но не забывайте, что делать это нужно редко и с особой осторожностью.
Объединение (union) – это что-то вроде структуры, все внутренние поля которой начинаются по одному и тому же адресу. Таким образом, их области памяти перекрываются, а это значит, что именно вы как пользователь объединения отвечаете за соответствие записываемой и считываемой информации: нужно всегда читать в точности тот тип, который был записан. В любой конкретный момент времени только один внутренний элемент объединения обладает корректным значением.
union IntOrFloat
{
int _int;
float _float;
}
unittest
{
IntOrFloat iof;
iof._int = 5;
// Читать только iof._int, но не iof._float
assert(iof._int == 5);
iof._float = 5.5;
// Читать только iof._float, но не iof._int
assert(iof._float == 5.5);
}
Поскольку типы int и float имеют строго один и тот же размер (4 байта), внутри объединения IntOrFloat их области памяти в точности совпадают. Но детали их расположения не регламентированы, например, представления _int и _float могут отличаться порядком хранения байтов: старший байт _int может иметь наименьший адрес, а старший байт _float (тот, что содержит знак и большую часть показателя степени) – наибольший адрес.
Объединения не помечаются, то есть сам объект типа union не содержит «метки», которая служила бы средством, позволяющим определять, какой из внутренних элементов является «хорошим». Ответственность за корректное использование объединения целиком ложится на плечи пользователя, что делает объединения довольно неприятным средством при построении более крупных абстракций.
В определенном, но неинициализированном объекте типа union уже есть одно инициализированное поле: первое поле автоматически инициализируется соответствующим значением .init, поэтому оно доступно для чтения сразу по завершении построения по умолчанию. Чтобы инициализировать первое поле значением, отличным от .init, укажите нужное инициализирующее выражение в фигурных скобках:
unittest
{
IntOrFloat iof = { 5 };
assert(iof._int == 5);
}
В статическом объекте типа union может быть инициализировано и другое поле. Для этого используйте следующий синтаксис:
unittest
{
static IntOrFloat iof = { _float : 5 };
assert(iof._float == 5);
}
Следует отметить, что нередко объединение служит именно для того, чтобы считывать тип, отличный от исходно записанного, – в соответствии с порядком управления представлением, принятым в некоторой системе. По этой причине компилятор не выявляет даже те случаи некорректного использования объединений, которые может обнаружить. Например, на 32-разрядной машине Intel следующий код компилируется и даже выполнение инструкции assert не порождает исключений:
unittest
{
IntOrFloat iof;
iof._float = 1;
assert(iof._int == 0x3F80_0000);
}
Объединение может определять функции-члены и, в общем случае, любые из тех внутренних элементов, которые может определять структура, за исключением конструкторов и деструкторов.
Чаще всего (точнее, наименее редко) объединения используются в качестве анонимных членов структур. Например:
import std.contracts;
struct TaggedUnion
{
enum Tag { _tvoid, _tint, _tdouble, _tstring, _tarray }
private Tag _tag;
private union
{
int _int;
double _double;
string _string;
TaggedUnion[] _array;
}
public:
void opAssign(int v)
{
_int = v;
_tag = Tag._tint;
}
int getInt()
{
enforce(_tag == Tag._tint);
return _int;
}
...
}
unittest
{
TaggedUnion a;
a = 4;
assert(a.getInt() == 4);
}
(Подробно тип enum описан в разделе 7.3.)
Этот пример демонстрирует чисто классический способ использования union в качестве вспомогательного средства для определения так называемого размеченного объединения (discriminated union, tagged union), также известного как алгебраический тип. Размеченное объединение инкапсулирует небезопасный объект типа union в «безопасной коробке», которая отслеживает последний присвоенный тип. Сразу после инициализации поле Tag содержит значение Tag._tvoid, по сути означающее, что объект не инициализирован. При присваивании объединению некоторого значения срабатывает оператор opAssign, устанавливающий тип объекта в соответствии с типом присваиваемого значения. Чтобы получить законченную реализацию, потребуется определить методы opAssign(double), opAssign(string) и opAssign(TaggedUnion[]) с соответствующими функциями getXxx().
Внутренний элемент типа union анонимен, то есть одновременно является и определением типа, и определением внутреннего элемента. Память под анонимное объединение выделяется как под обычный внутренний элемент структуры, и внутренние элементы этого объединения напрямую видимы внутри структуры (как показывают методы TaggedUnion). В общем случае можно определять как анонимные структуры, так и анонимные объединения, и вкладывать их как угодно.
В конце концов вы должны понять, что объединение не такое уж зло, каким может показаться. Как правило, использовать объединение вместо того, чтобы играть типами с помощью выражения cast, – хороший тон в общении между программистом и компилятором. Объединение указателя и целого числа указывает сборщику мусора, что ему следует быть осторожнее и не собирать этот указатель. Если вы сохраните указатель в целом числе и будете время от времени преобразовывать его назад к типу указателя (с помощью cast), результаты окажутся непредсказуемыми, ведь сборщик мусора может забрать память, ассоциированную с этим тайным указателем.
7.3. Перечисляемые значения
Типы, принимающие всего несколько определенных значений, оказались очень полезными – настолько полезными, что язык Java после нескольких лет героических попыток эмулировать перечисляемые типы с помощью идиомы в конце концов добавил их к основным типам. Определить хорошие перечисляемые типы непросто – в C (и особенно в C++) типу enum присущи свои странности. D попытался учесть предшествующий опыт, определив простое и полезное средство для работы с перечисляемыми типами.
Начнем с азов. Простейший способ применить enum – как сказать «давайте перечислим несколько символьных значений», не ассоциируя их с новым типом:
enum
mega = 1024 * 1024,
pi = 3.14,
euler = 2.72,
greet = "Hello";
С enum механизм автоматического определения типа работает так же, как и с auto, поэтому в нашем примере переменные pi и euler имеют тип double, a переменная greet – тип string. Чтобы определить одно или несколько перечисляемых значений определенного типа, укажите их справа от ключевого слова enum:
enum float verySmall = 0.0001, veryBig = 10000;
enum dstring wideMsg = "Wide load";
Перечисляемые значения – это константы; они практически эквивалентны литералам, которые обозначают. В частности, поддерживают те же операции – например, невозможно получить адрес pi, как невозможно получить адрес 3.14:
auto x = pi; // Все в порядке, x обладает типом double
auto y = pi * euler; // Все в порядке, y обладает типом double
euler = 2.73; // Ошибка! Невозможно изменить перечисляемое значение!
void fun(ref double x) {
...
}
fun(pi); // Ошибка! Невозможно получить адрес 3.14!
Как показано выше, типы перечисляемых значений не ограничиваются типом int – типы double и string также допустимы. Какие вообще типы можно использовать с enum? Ответ прост: c enum можно использовать любой основной тип и любую структуру. Есть лишь два требования к инициализирующему значению при определении перечисляемых значений:
- инициализирующее значение должно быть вычислимым во времякомпиляции;
- тип инициализирующего значения должен позволять копирование, то есть в его определении не должно быть
@disable this(this)(см. раздел 7.1.3.4).
Первое требование гарантирует независимость перечисляемого значения от параметров времени исполнения. Второе требование обеспечивает возможность копировать значение; копия создается при каждом обращении к перечисляемому значению.
Невозможно определить перечисляемое значение типа class, поскольку объекты классов должны всегда создаваться с помощью оператора new (за исключением не представляющего интерес значения null), а выражение с new во время компиляции вычислить невозможно. Не будет неожиданностью, если в будущем это ограничение снимут или ослабят.
Создадим перечисление значений типа struct:
struct Color
{
ubyte r, g, b;
}
enum
red = Color(255, 0, 0),
green = Color(0, 255, 0),
blue = Color(0, 0, 255);
Когда бы вы ни использовали, например, идентификатор green, код будет вести себя так, будто вместо этого идентификатора вы написали Color(0, 255, 0).
7.3.1. Перечисляемые типы
Можно дать имя группе перечисляемых значений, создав таким образом новый тип на ее основе:
enum OddWord { acini, alembicated, prolegomena, aprosexia }
Члены именованной группы перечисляемых значений не могут иметь разные типы; все перечисляемые значения должны иметь один и тот же тип, поскольку пользователи могут впоследствии определять и использовать значения этого типа. Например:
OddWord w;
assert(w == OddWord.acini); // Инициализирующим значением по умолчанию является первое значение в множестве - acini.
w = OddWord.aprosexia; // Всегда уточняйте имя значения (кстати, это не то, что вы могли подумать) с помощью имени типа.
int x = w; // OddWord конвертируем в int, но не наоборот.
assert(x == 3); // Значения нумеруются по порядку: 0, 1, 2, ...
Тип, автоматически определяемый для поименованного перечисления, – int. Присвоить другой тип можно так:
enum OddWord : byte { acini, alembicated, prolegomena, aprosexia }
С новым определением (byte называют базовым типом OddWord) значения идентификаторов перечисления не меняются, изменяется лишь способ их хранения. Вы можете с таким же успехом назначить членам перечисления тип double или real, но связанные с идентификаторами значения останутся прежними: 0, 1 и т. д. Но если сделать базовым типом OddWord нечисловой тип, например string, то придется указать инициализирующее значение для каждого из значений, поскольку компилятору неизвестна никакая естественная последовательность, которой он мог бы придерживаться.
Возвратимся к числовым перечислениям. Присвоив какому-либо члену перечисления особое значение, вы таким образом сбросите счетчик, используемый компилятором для присваивания значений идентификаторам. Например:
enum E { a, b = 2, c, d = -1, e, f }
assert(E.c == 3);
assert(E.e == 0);
Если два идентификатора перечисления получают одно и то же значение (как в случае с E.a и E.e), конфликта нет. Фактически равные значения можно создавать, даже не подозревая об этом – из-за непреодолимого желания типов с плавающей запятой удивить небдительных пользователей:
enum F : float { a = 1E30, b, c, d }
assert(F.a == F.d); // Тест пройден
Корень этой проблемы в том, что наибольшее значение типа int, которое может быть представлено значением типа float, равно 16_777_216, и выход за эту границу сопровождается все возрастающими диапазонами целых значений, представляемых одним и тем же числом типа float.
7.3.2. Свойства перечисляемых типов
Для всякого перечисляемого типа E определены три свойства: E.init (это свойство принимает первое из значений, определенных в E), E.min (наименьшее из определенных в E значений) и E.max (наибольшее из определенных в E значений). Два последних значения определены, только если базовым типом E является тип, поддерживающий сравнение во время компиляции с помощью оператора <.
Вы вправе определить внутри enum собственные значения min, max и init, но поступать так не рекомендуется: обобщенный код частенько рассчитывает на то, что эти значения обладают особой семантикой.
Один из часто задаваемых вопросов: «Можно ли добраться до имени перечисляемого значения?» Вне всяких сомнений, сделать это возможно и на самом деле легко, но не с помощью встроенного механизма, а на основе рефлексии времени компиляции. Рефлексия работает так: с некоторым перечисляемым типом Enum связывается известная во время компиляции константа __traits(allMembers, Enum), которая содержит все члены Enum в виде кортежа значений типа string. Поскольку строками можно манипулировать во время компиляции, как и во время исполнения, такой подход дает значительную гибкость. Например, немного забежав вперед, напишем функцию toString, которая возвращает строку, соответствующую заданному перечисляемому значению. Функция параметризирована перечисляемым типом.
string toString(E)(E value) if (is(E == enum))
{
foreach (s; __traits(allMembers, E))
{
if (value == mixin("E." ~ s)) return s;
}
return null;
}
enum OddWord { acini, alembicated, prolegomena, aprosexia }
void main()
{
auto w = OddWord.alembicated;
assert(toString(w) == "alembicated");
}
Незнакомое пока выражение mixin("E." ~ s) – это выражение mixin. Выражение mixin принимает строку, известную во время компиляции, и просто вычисляет ее как обычное выражение в рамках текущего контекста. В нашем примере это выражение включает имя перечисления E, оператор . для выбора внутренних элементов и переменную s для перебора идентификаторов перечисляемых значений. В данном случае s последовательно принимает значения "acini", "alembicated", ..., "aprosexia". Таким образом, конкатенированная строка примет вид "E.acini" и т. д., а выражение mixin вычислит ее, сопоставив указанным идентификаторам реальные значения. Обнаружив, что переданное значение равно очередному значению, вычисленному выражением mixin, функция toString возвращает результат. Получив некорректный аргумент value, функция toString могла бы порождать исключение, но чтобы упростить себе жизнь, мы решили просто возвращать константу null.
Рассмотренная функция toString уже реализована в модуле std.conv стандартной библиотеки, имеющем дело с общими преобразованиями. Имя этой функции немного отличается от того, что использовали мы: вам придется писать to!string(w) вместо toString(w), что говорит о гибкости этой функции (также можно сделать вызов to!dstring(w) или to!byte(w) и т. д.). Этот же модуль определяет и обратную функцию, которая конвертирует строку в значение перечисляемого типа; например вызов to!OddWord("acini") возвращает OddWord.acini.
7.4. alias
В ряде случаев мы уже имели дело с size_t – целым типом без знака, достаточно вместительным, чтобы представить размер любого объекта. Тип size_t не определен языком, он просто принимает форму uint или ulong в зависимости от адресного пространства конечной системы (32 или 64 бита соответственно).
Если бы вы открыли файл object.di, один из копируемых на компьютер пользователя (а значит, и на ваш) при инсталляции компилятора D, то нашли бы объявление примерно следующего вида:
alias typeof(int.sizeof) size_t;
Свойство .sizeof точно измеряет размер типа в байтах; в данном случае это тип int. Вместо int в примере мог быть любой другой тип; в данном случае имеет значение не указанный тип, а тип размера, возвращаемый оператором typeof. Компилятор измеряет размеры объектов, используя uint на 32-разрядных архитектурах и ulong на 64-разрядных. Следовательно, конструкция alias позволяет назначить size_t синонимом uint или ulong.
Обобщенный синтаксис объявления с ключевым словом alias ничуть не сложнее приведенного выше:
alias ‹существующийИдентификатор› ‹новыйИдентификатор›;
В качестве идентификатора ‹существующийИдентификатор› можно подставить все, у чего есть имя. Это может быть тип, переменная, модуль – если что-то обладает идентификатором, то для этого объекта можно создать псевдоним. Например:
import std.stdio;
void fun(int) {}
void fun(string) {}
int var;
enum E { e }
struct S { int x; }
S s;
unittest
{
alias object.Object Root; // Предок всех классов
alias std phobos; // Имя пакета
alias std.stdio io; // Имя модуля
alias var sameAsVar; // Переменная
alias E MyEnum; // Перечисляемый тип
alias E.e myEnumValue; // Значение этого типа
alias fun gun; // Перегруженная функция
alias S.x field; // Поле структуры
alias s.x sfield; // Поле объекта
}
Правила применения псевдонима просты: используйте псевдоним везде, где допустимо использовать исходный идентификатор. Именно это делает компилятор, но с точностью до наоборот: он с пониманием заменяет идентификатор-псевдоним оригинальным идентификатором. Даже сообщения об ошибках и отлаживаемая программа могут «видеть сквозь» псевдонимы и показывать исходные идентификаторы, что может оказаться неожиданным. Например, в некоторых сообщениях об ошибках или в отладочных символах можно увидеть immutable(char)[] вместо string. Но что именно будет показано, зависит от реализации компилятора.
С помощью конструкции alias можно создавать псевдонимы псевдонимов для идентификаторов, уже имеющих псевдонимы. Например:
alias int Int;
alias Int MyInt;
Здесь нет ничего особенного, просто следование обычным правилам: к моменту определения псевдонима MyInt псевдоним Int уже будет заменен исходным идентификатором int, для которого Int является псевдонимом.
Конструкцию alias часто применяют, когда требуется дать сложной цепочке идентификаторов более короткое имя или в связке с перегруженными функциями из разных модулей (см. раздел 5.5.2).
Также конструкцию alias часто используют с параметризированными структурами и классами. Например:
// Определить класс-контейнер
class Container(T)
{
alias T ElementType;
...
}
unittest
{
Container!int container;
Container!int.ElementType element;
...
}
Здесь общедоступный псевдоним ElementType, созданный классом Container, – единственный разумный способ обратиться из внешнего мира к аргументу, привязанному к параметру T класса Container. Идентификатор T видим лишь внутри определения класса Container, но не снаружи: выражение Container!int.T не компилируется.
Наконец, конструкция alias весьма полезна в сочетании с конструкцией static if. Например:
// Из файла object.di
// Определить тип разности между двумя указателями
static if (size_t.sizeof == 4)
{
alias int ptrdiff_t;
}
else
{
alias long ptrdiff_t;
}
// Использовать ptrdiff_t ...
С помощью объявления псевдоним ptrdiff_t привязывается к разным типам в зависимости от того, по какой ветке статического условия пойдет поток управления. Без этой возможности привязки код, которому потребовался такой тип, пришлось бы разместить в одной из веток static if.
7.5. Параметризированные контексты (конструкция template)
Мы уже рассмотрели средства, облегчающие параметризацию во время компиляции (эти средства сродни шаблонам из C++ и родовым типам из языков Java и C#), – это функции (см. раздел 5.3), параметризированные классы (см. раздел 6.14) и параметризированные структуры, которые подчиняются тем же правилам, что и параметризированные классы. Тем не менее иногда во время компиляции требуется каким-либо образом манипулировать типами, не определяя функцию, структуру или класс. Один из механизмов, подходящих под это описание (широко используемый в C++), – выбор того или иного типа в зависимости от статически известного логического условия. При этом не определяется никакой новый тип и не вызывается никакая функция – лишь создается псевдоним для одного из существующих типов.
Для случаев, когда требуется организовать параметризацию во время компиляции без определения нового типа или функции, D предоставляет параметризированные контексты. Такой параметризированный контекст вводится следующим образом:
template Select(bool cond, T1, T2)
{
...
}
Этот код – на самом деле лишь каркас для только что упомянутого механизма выбора во время компиляции. Скоро мы доберемся и до реализации, а пока сосредоточимся на порядке объявления. Объявление с ключевым словом template вводит именованный контекст (в данном случае это Select) с параметрами, вычисляемыми во время компиляции (в данном случае это логическое значение и два типа). Объявить контекст можно на уровне модуля, внутри определения класса, внутри определения структуры, внутри любого другого объявления контекста, но не внутри определения функции.
В теле параметризированного контекста разрешается использовать все те же объявления, что и обычно, кроме того, могут быть использованы параметры контекста. Доступ к любому объявлению контекста можно получить извне, расположив перед его именем имя контекста и ., например: Select!(true, int, double).foo. Давайте прямо сейчас закончим определение контекста Select, чтобы можно было поиграть с ним:
template Select(bool cond, T1, T2)
{
static if (cond)
{
alias T1 Type;
}
else
{
alias T2 Type;
}
}
unittest
{
alias Select!(false, int, string).Type MyType;
static assert(is(MyType == string));
}
Заметим, что тот же результат мы могли бы получить на основе структуры или класса, поскольку эти типы могут определять в качестве своих внутренних элементов псевдонимы, доступные с помощью обычного синтаксиса с оператором . (точка):
struct /* или class */ Select2(bool cond, T1, T2)
{
static if (cond)
{
alias T1 Type;
}
else
{
alias T2 Type;
}
}
unittest
{
alias Select2!(false, int, string).Type MyType;
static assert(is(MyType == string));
}
Согласитесь, такое решение выглядит не очень привлекательно. К примеру, для Select2 в документации пришлось бы написать: «Не создавайте объекты типа Select2! Он определен только ради псевдонима внутри него!» Доступный специализированный механизм определения параметризированных контекстов позволяет избежать двусмысленности намерений, не вызывает недоумения и исключает возможность некорректного использования.
В контексте, определенном с ключевым словом template, можно объявлять не только псевдонимы – там могут присутствовать самые разные объявления. Определим еще один полезный шаблон. На этот раз это будет шаблон, возвращающий логическое значение, которое сообщает, является ли заданный тип строкой (в любой кодировке):
template isSomeString(T)
{
enum bool value = is(T : const(char[])) || is(T : const(wchar[])) || is(T : const(dchar[]));
}
unittest
{
// Не строки
static assert(!isSomeString!(int).value);
static assert(!isSomeString!(byte[]).value);
// Строки
static assert(isSomeString!(char[]).value);
static assert(isSomeString!(dchar[]).value);
static assert(isSomeString!(string).value);
static assert(isSomeString!(wstring).value);
static assert(isSomeString!(dstring).value);
static assert(isSomeString!(char[4]).value);
}
Параметризированные контексты могут быть рекурсивными; к примеру, вот одно из возможных решений задачи с факториалом:
template factorial(uint n)
{
static if (n <= 1)
enum ulong value = 1;
else
enum ulong value = factorial!(n - 1).value * n;
}
Несмотря на то что factorial является совершенным функциональным определением, в данном случае это не лучший подход. При необходимости вычислять значения во время компиляции, пожалуй, стоило бы воспользоваться механизмом вычислений во время компиляции (см. раздел 5.12). В отличие от приведенного выше шаблона factorial, функция factorial более гибка, поскольку может вычисляться как во время компиляции, так и во время исполнения. Конструкция template больше всего подходит для манипуляции типами, имеющей место в Select и isSomeString.
7.5.1. Одноименные шаблоны
Конструкция template может определять любое количество идентификаторов, но, как видно из предыдущих примеров, нередко в ней определен ровно один идентификатор. Обычно шаблон определяется лишь с целью решить единственную задачу и в качестве результата сделать доступным единственный идентификатор (такой как Type в случае Select или value в случае isSomeString).
Необходимость помнить о том, что в конце вызова надо указать этот идентификатор, и всегда его указывать может раздражать. Многие просто забывают добавить в конец .Type, а потом удивляются, почему вызов Select!(cond, A, B) порождает таинственное сообщение об ошибке.
D помогает здесь, определяя правило, известное как фокус с одноименным шаблоном: если внутри конструкции template определен идентификатор, совпадающий с именем самого шаблона, то при любом последующем использовании имени этого шаблона в его конец будет автоматически дописываться одноименный идентификатор. Например:
template isNumeric(T)
{
enum bool isNumeric = is(T : long) || is(T : real);
}
unittest
{
static assert(isNumeric!(int));
static assert(!isNumeric!(char[]));
}
Если теперь некоторый код использует выражение isNumeric!(T), компилятор в каждом случае автоматически заменит его на isNumeric!(T).isNumeric, чем освободит пользователя от хлопот с добавлением идентификатора в конец имени шаблона.
Шаблон, проделывающий фокус с «тезками», может определять внутри себя и другие идентификаторы, но они будут попросту недоступны за пределами этого шаблона. Дело в том, что компилятор заменяет идентификаторы на раннем этапе процесса поиска имен. Единственный способ получить доступ к таким идентификаторам – обратиться к ним из тела самого шаблона. Например:
template isNumeric(T)
{
enum bool test1 = is(T : long);
enum bool test2 = is(T : real);
enum bool isNumeric = test1 || test2;
}
unittest
{
static assert(isNumeric!(int).test1); // Ошибка! Тип bool не определяет свойство test1!
}
Это сообщение об ошибке вызвано соблюдением правила об одноименности: перед тем как делать что-либо еще, компилятор расширяет вызов isNumeric!(int) до isNumeric!(int).isNumeric. Затем пользовательский код делает попытку заполучить значение isNumeric!(int).isNumeric.test1, что равносильно попытке получить внутренний элемент test1 из логического значения, отсюда и сообщение об ошибке. Короче говоря, используйте одноименные шаблоны тогда и только тогда, когда хотите открыть доступ лишь к одному идентификатору. Этот случай скорее частый, чем редкий, поэтому одноименные шаблоны очень популярны и удобны.
7.5.2. Параметр шаблона this4
Познакомившись с классами и структурами, можно параметризовать наш обобщенный метод типом неявного аргумента this. Например:
class Parent
{
static string getName(this T)()
{
return T.stringof;
}
}
class Derived1: Parent{}
class Derived2: Parent{}
unittest
{
assert(Parent.getName() == "Parent");
assert(Derived1.getName() == "Derived1");
assert(Derived2.getName() == "Derived2");
}
Параметр шаблона this T предписывает компилятору в теле getName считать T псевдонимом typeof(this).
В обычный статический метод класса не передаются никакие скрытые параметры, поэтому невозможно определить, для какого конкретно класса вызван этот метод. В приведенном примере компилятор создает три экземпляра шаблонного метода Parent.getName(this T)(): Parent.getName(), Derived1.getName() и Derived2.getName().
Также параметр this удобен в случае, когда один метод нужно использовать для разных квалификаторов неизменяемости объекта (см. главу 8).
7.6. Инъекции кода с помощью конструкции mixin template
При некоторых программных решениях приходится добавлять шаблонный код (такой как определения данных и методов) в одну или несколько реализаций классов. К типичным примерам относятся поддержка сериализации, шаблон проектирования «Наблюдатель» и передача событий в оконных системах.
Для этих целей можно было бы воспользоваться механизмом наследования, но поскольку реализуется лишь одиночное наследование, определить для заданного класса несколько источников шаблонного кода невозможно. Иногда необходим механизм, позволяющий просто вставить в класс некоторый готовый код, вместо того чтобы писать его вручную.
Здесь-то и пригодится конструкция mixin template (шаблон mixin). Стоит отметить, что сейчас это средство в основном экспериментальное. Возможно, в будущих версиях языка шаблоны mixin заменит более общий инструмент AST-макросов.
Шаблон mixin определяется почти так же, как параметризированный контекст (шаблон), о котором недавно шла речь. Пример шаблона mixin, определяющего переменную и функции для ее чтения и записи:
mixin template InjectX()
{
private int x;
int getX() { return x; }
void setX(int y)
{
... // Проверки
x = y;
}
}
Определив шаблон mixin, можно вставить его в нескольких местах:
// Сделать инъекцию в контексте модуля
mixin InjectX;
class A
{
// Сделать инъекцию в класс
mixin InjectX;
...
}
void fun()
{
// Сделать инъекцию в функцию
mixin InjectX;
setX(10);
assert(getX() == 10);
}
Теперь этот код определяет переменную и две обслуживающие ее функции на уровне модуля, внутри класса A и внутри функции fun – как будто тело InjectX было вставлено вручную. В частности, потомки класса A могут переопределять методы getX и setX, как если бы сам класс определял их. Копирование и вставка без неприятного дублирования кода – вот что такое mixin template.
Конечно же, следующий логический шаг – подумать о том, что InjectX не принимает никаких параметров, но производит впечатление, что мог бы, – и действительно может:
mixin template InjectX(T)
{
private T x;
T getX() { return x; }
void setX(T y)
{
... // Проверки
x = y;
}
}
Теперь при обращении к InjectX нужно передавать аргумент так:
mixin InjectX!int;
mixin InjectX!double;
Но на самом деле такие вставки приводят к двусмысленности: что если вы сделаете две рассмотренные подстановки, а затем пожелаете воспользоваться функцией getX? Есть две функции с этим именем, так что проблема с двусмысленностью очевидна. Чтобы решить этот вопрос, D позволяет вводить имена для конкретных подстановок в шаблоны mixin:
mixin InjectX!int MyInt;
mixin InjectX!double MyDouble;
Задав такие определения, вы можете недвусмысленно обратиться к внутренним элементам любого из шаблонов mixin, просто указав нужный контекст:
MyInt.setX(5);
assert(MyInt.getX() == 5);
MyDouble.setX(5.5);
assert(MyDouble.getX() == 5.5);
Таким образом, шаблоны mixin – это почти как копирование и вставка; вы можете многократно копировать и вставлять код, а потом указывать, к какой именно вставке хотите обратиться.
7.6.1. Поиск идентификаторов внутри mixin
Самая большая разница между шаблоном mixin и обычным шаблоном (в том виде, как он определен в разделе 7.5), способная вызвать больше всего вопросов, – это поиск имен.
Шаблоны исключительно модульны: код внутри шаблона ищет идентификаторы в месте определения шаблона. Это положительное качество: оно гарантирует, что, проанализировав определение шаблона, вы уже ясно представляете его содержимое и осознаете, как он работает.
Шаблон mixin, напротив, ищет идентификаторы в месте подстановки, а это означает, что понять поведение шаблона mixin можно только с учетом контекста, в котором вы собираетесь этот шаблон использовать.
Чтобы проиллюстрировать разницу, рассмотрим следующий пример, в котором идентификаторы объявляются как в месте определения, так и в месте подстановки:
import std.stdio;
string lookMeUp = "Найдено на уровне модуля";
template TestT()
{
string get() { return lookMeUp; }
}
mixin template TestM()
{
string get() { return lookMeUp; }
}
void main()
{
string lookMeUp = "Найдено на уровне функции";
alias TestT!() asTemplate;
mixin TestM!() asMixin;
writeln(asTemplate.get());
writeln(asMixin.get());
}
Эта программа выведет на экран:
Найдено на уровне модуля
Найдено на уровне функции
Склонность шаблонов mixin привязываться к локальным идентификаторам придает им выразительности, но следовать их логике становится сложно. Такое поведение делает шаблоны mixin применимыми лишь в ограниченном количестве случаев; прежде чем доставать из ящика с инструментами эти особенные ножницы, необходимо семь раз отмерить.
7.7. Итоги
Классы позволяют эффективно представить далеко не любую абстракцию. Например, они не подходят для мелкокалиберных объектов, контекстно-зависимых ресурсов и типов значений. Этот пробел восполняют структуры. В частности, благодаря конструкторам и деструкторам легко определять типы контекстно-зависимых ресурсов.
Объединения – низкоуровневое средство, позволяющее хранить разные типы данных в одной области памяти с перекрыванием.
Перечисления – это обычные отдельные значения, определенные пользователем. Перечислению может быть назначен новый тип, что позволяет более точно проверять типы значений, определенных в рамках этого типа.
alias – очень полезное средство, позволяющее привязать один идентификатор к другому. Нередко псевдоним – единственное средство получить извне доступ к идентификатору, вычисляемому в рамках вложенной сущности, или к длинному и сложному идентификатору.
Параметризированные контексты, использующие конструкцию template, весьма полезны для определения вычислений во время компиляции, таких как интроспекция типов и определение особенностей типов. Одноименные шаблоны позволяют предоставлять абстракции в очень удобной, инкапсулированной форме.
Кроме того, предлагаются параметризированные контексты, принимающие форму шаблонов mixin, которые во многом ведут себя подобно макросам. В будущем шаблоны mixin может заменить развитое средство AST-макросов.
🢀 6. Классы. Объектно-ориентированный стиль 7. Другие пользовательские типы 8. Квалификаторы типа 🢂
-
Не считая эквивалентных имен, создаваемых с помощью
alias, о чем мы еще поговорим в этой главе (см. раздел 7.4). ↩︎ -
Термин «клуктура» предложил Бартош Милевски. ↩︎
-
Кроме того,
‹код1›может сохранить указатель на значениеw, которое использует‹код2›. ↩︎ -
На момент написания оригинала книги данная возможность отсутствовала, но поскольку теперь она существует, мы добавили ее описание в перевод. – Прим. науч. ред. ↩︎