| .. | ||
| images | ||
| README.md | ||
2. Основные типы данных. Выражения
- 2.1. Идентификаторы
- 2.2. Литералы
- 2.2.1. Логические литералы
- 2.2.2. Целые литералы
- 2.2.3. Литералы с плавающей запятой
- 2.2.4. Знаковые литералы
- 2.2.5. Строковые литералы
- 2.2.6. Литералы массивов и ассоциативных массивов
- 2.2.7. Функциональные литералы (лямбда-функция)
- 2.3. Операции
- 2.3.1. l-значения и r-значения
- 2.3.2. Неявные преобразования чисел
- 2.3.2.1. Распространение интервала значений
- 2.3.3. Типы числовых операций
- 2.3.4. Первичные выражения
- 2.3.4.1. Выражение assert
- 2.3.4.2. Выражение mixin
- 2.3.4.3. Выражения is
- 2.3.4.4. Выражения в круглых скобках
- 2.3.5. Постфиксные операции
- 2.3.5.1. Доступ ко внутренним элементам
- 2.3.5.2. Увеличение и уменьшение на единицу
- 2.3.5.3. Вызов функции
- 2.3.5.4. Индексация
- 2.3.5.5. Срезы массивов
- 2.3.5.6. Создание вложенного класса
- 2.3.6. Унарные операции
- 2.3.6.1. Выражение new
- 2.3.6.2. Получение адреса и разыменование
- 2.3.6.3. Увеличение и уменьшение на единицу (префиксный вариант)
- 2.3.6.4. Поразрядное отрицание
- 2.3.6.5. Унарный плюс и унарный минус
- 2.3.6.6. Отрицание
- 2.3.6.7. Приведение типов
- 2.3.7. Возведение в степень
- 2.3.8. Мультипликативные операции
- 2.3.9. Аддитивные операции
- 2.3.10. Сдвиг
- 2.3.11. Выражения in
- 2.3.12. Сравнение
- 2.3.12.1. Проверка на равенство
- 2.3.12.2. Сравнение для упорядочивания
- 2.3.12.3. Неассоциативность
- 2.3.13. Поразрядные ИЛИ, ИСКЛЮЧАЮЩЕЕ ИЛИ и И
- 2.3.14. Логическое И
- 2.3.15. Логическое ИЛИ
- 2.3.16. Тернарная условная операция
- 2.3.17. Присваивание
- 2.3.18. Выражения с запятой
- 2.4. Итоги и справочник
Если вы когда-нибудь программировали на C, C++, Java или C#, то с основными типами данных и выражениями D у вас не будет никаких затруднений. Операции со значениями основных типов – неотъемлемая часть решений многих задач программирования. Эти средства языка, в зависимости от ваших предпочтений, могут сильно облегчать либо отравлять вам жизнь. Совершенного подхода не существует; нередко поставленные цели противоречат друг другу, заставляя руководствоваться собственным субъективным мнением. Это, в свою очередь, лишает язык возможности угодить всем до единого. Слишком строгая система обременяет программиста своими запретами: он вынужден бороться с компилятором, чтобы тот принял простейшие выражения. А сделай систему типизации чересчур снисходительной – и не заметишь, как окажешься по ту сторону корректности, эффективности или того и другого вместе.
Система основных типов D творит маленькие чудеса в границах, задаваемых его принадлежностью к семейству статически типизированных компилируемых языков. Определение типа по контексту, распространение интервала значений, всевозможные стратегии перегрузки операторов и тщательно спроектированная сеть автоматических преобразований вместе делают систему типизации D дотошным, но сдержанным помощником, который если и придирается, требуя внимания, то обычно не зря.
Основные типы данных можно распределить по следующим категориям:
- Тип без значения:
void, используется во всех случаях, когда формально требуется указать тип, но никакое осмысленное значение не порождается. - Тип null:
typeof(null)– тип константыnull, используется в основном в шаблонах, неявно приводится к указателям, массивам, ассоциативным массивам и объектным типам. - Логический (булев) тип:
boolс двумя возможными значениямиtrueиfalse. - Целые типы:
byte,short,intиlong, а также их эквиваленты без знакаubyte,ushort,uintиulong. - Вещественные типы с плавающей запятой:
float,doubleиreal. - Знаковые типы:
char,wcharиdchar, которые на самом деле содержат числа, предназначенные для кодирования знаков Юникода.
В табл. 2.1 вкратце описаны основные типы данных D с указанием их размеров и начальных значений по умолчанию. В языке D переменная инициализируется автоматически, если вы просто определили ее, не указав начального значения. Значение по умолчанию доступно для любого типа как <тип>.init; например int.init – это ноль.
Таблица 2.1. Основные типы данных D
| Тип данных | Описание | Начальное значение по умолчанию |
|---|---|---|
void |
Без значения | n/a |
typeof(null) |
Тип константы null |
n/a |
bool |
Логическое (булево) значение | false |
byte |
Со знаком, 8 бит | 0 |
ubyte |
Без знака, 8 бит | 0 |
short |
Со знаком, 16 бит | 0 |
ushort |
Без знака, 16 бит | 0 |
int |
Со знаком, 32 бита | 0 |
uint |
Без знака, 32 бита | 0 |
long |
Со знаком, 64 бита | 0 |
ulong |
Без знака, 64 бита | 0 |
float |
32 бита, с плавающей запятой | float.nan |
double |
64 бита, с плавающей запятой | double.nan |
real |
Наибольшее, какое только может позволить аппаратное обеспечение | real.nan |
char |
Без знака, 8 бит, в UTF-8 | 0xFF |
wchar |
Без знака, 16 бит, в UTF-16 | 0xFFFF |
dchar |
Без знака, 32 бита, в UTF-32 | 0x0000FFFF |
2.1. Идентификаторы
Идентификатор, или символ – это чувствительная к регистру строка знаков, начинающаяся с буквы или знака подчеркивания, после чего следует любое количество букв, знаков подчеркивания или цифр. Единственное исключение из этого правила: идентификаторы, начинающиеся с двух знаков подчеркивания, зарезервированы под ключевые слова самого D. Идентификаторы, начинающиеся с одного знака подчеркивания, разрешены, и в настоящее время даже принято именовать поля классов таким способом.
Интересная особенность идентификаторов D – их интернациональность: «буква» в определении выше – это не только буква латинского алфавита (от A до Z и от a до z), но и знак из универсального набора1, определенного в стандарте C992.
Например, abc, α5, _, Γ_1, _AbC, Ab9C и _9x – допустимые идентификаторы, а 9abc и __abc – нет.
Если перед идентификатором стоит точка (.какЗдесь), то компилятор ищет его в пространстве имен модуля, а не в текущем лексически близком пространстве имен. Этот префиксный оператор-точка имеет тот же приоритет, что и обычный идентификатор.
2.1.1. Ключевые слова
Приведенные в табл. 2.2 идентификаторы – это ключевые слова, зарезервированные языком для специального использования. Пользовательский код не может переопределять их ни при каких условиях.
Таблица 2.2. Ключевые слова языка D
abstract else macro switch
alias enum mixin synchronized
align export module
asm extern template
assert new this
auto false nothrow throw
final null true
body finally try
bool float out typeid
break for override typeof
byte foreach
function package ubyte
case pragma uint
cast goto private ulong
catch protected union
char ifIf public unittest
class immutable pure ushort
const import
continue in real version
inout ref void
dchar int return
debug interface wchar
default invariant scope while
delegate isIs short with
deprecated static
do long struct
double lazy super
Некоторые из ключевых слов распознаются как первичные выражения. Например, ключевое слово this внутри определения метода означает текущий объект, а ключевое слово super как статически, так и динамически заставляет компилятор обратиться к классу-родителю текущего класса (см. главу 6). Идентификатор $ разрешен только внутри индексного выражения или выражения получения среза и обозначает длину индексируемого массива. Идентификатор null обозначает пустой объект, массив или указатель.
Первичное выражение typeid(T) возвращает информацию о типе T (за дополнительной информацией обращайтесь к документации для вашей реализации компилятора).
2.2. Литералы
2.2.1. Логические литералы
Логические (булевы) литералы – это true («истина») и false («ложь»).
2.2.2. Целые литералы
D работает с десятичными, восьмеричными3, шестнадцатеричными и двоичными целыми литералами. Десятичная константа - это последовательность цифр, возможно, с суффиксом L, U, u, LU, Lu, UL или ul. Вывод о типе десятичного литерала делается исходя из следующих правил:
- нет суффикса: если значение «помещается» в
int, тоint, иначеlong; - только
U/u: если значение «помещается» вuint, тоuint, иначеulong. - только
L: тип константы -long. U/uиLсовместно: тип константы -ulong.
Например:
auto
a = 42, // a имеет тип int
b = 42u, // b имеет тип uint
c = 42UL, // c имеет тип ulong
d = 4_000_000_000, // long; в int не поместится
e = 4_000_000_000u, // uint; в uint не поместится
f = 5_000_000_000u; // ulong; в uint не поместится
Вы можете свободно вставлять в числа знаки подчеркивания (только не ставьте их в начало, иначе вы на самом деле создадите идентификатор). Знаки подчеркивания помогают сделать большое число более наглядным:
auto targetSalary = 15_000_000;
Чтобы написать шестнадцатеричное число, используйте префикс 0x или 0X, за которым следует последовательность знаков 0–9, a–f, A–F или _. Двоичный литерал создается с помощью префикса 0b или 0B, за которым идет последовательность из 0, 1 и тех же знаков подчеркивания. Как и у десятичных чисел, у всех этих литералов может быть суффикс. Правила, с помощью которых их типы определяются по контексту, идентичны правилам для десятичных чисел.
Рисунок 2.1, заменяющий 1024 слова, кратко и точно определяет синтаксис целых литералов. Правила интерпретации автомата таковы: 1) каждое ребро «поглощает» знаки, соответствующие его ребру, 2) автомат пытается «расходовать» как можно больше знаков из входной последовательности4. Достижение конечного состояния (двойной кружок) означает, что число успешно распознано.
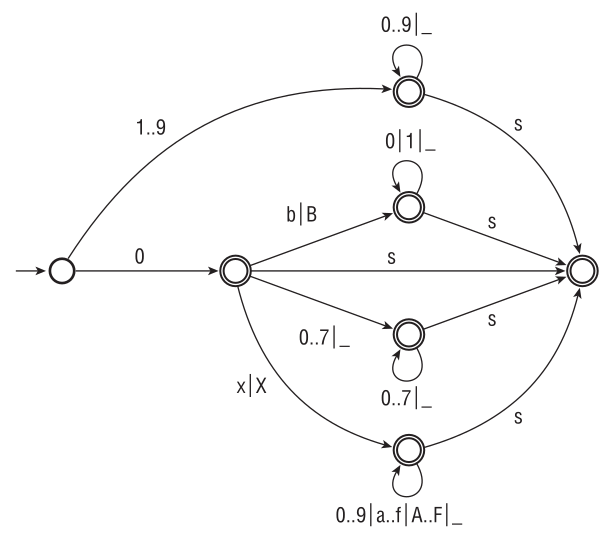
Рис. 2.1. Распознавание целых литералов в языке D. Автомат пытается сделать ряд последовательных шагов (поглощая знаки, соответствующие данному ребру), пока не остановится. Останов в конечном состоянии (двойной кружок) означает, что число успешно распознано. s обозначает суффикс вида U|u|L|UL|uL|Lu|LU
2.2.3. Литералы с плавающей запятой
Литералы с плавающей запятой могут быть десятичными и шестнадцатеричными. Десятичные литералы с плавающей запятой легко определить по аналогии с только что определенными десятичными целыми числами: десятичный литерал с плавающей запятой состоит из десятичного литерала, который также может содержать точку5 в любой позиции, за ней могут следовать показатель степени (характеристика) и суффикс. Показатель степени6 – это то, что обозначается как e, E, e+, E+, e- или E-, после чего следует целый десятичный литерал без знака7. В качестве суффикса может выступать f, F или L. Разумеется, хотя бы что-то одно из e/E и f/F должно присутствовать, иначе если в числе нет точки, вместо числа с плавающей запятой получим целое. Суффикс f/F заставляет компилятор определить тип литерала как float, а суффикс L – как real. Иначе литералу будет присвоен тип double.
Может показаться, что шестнадцатеричные константы с плавающей запятой – вещь странноватая. Однако, как показывает практика, они очень удобны, если нужно записать число очень точно. Внутреннее представление чисел с плавающей запятой характеризуется тем, что числа хранятся в двоичном виде, поэтому запись вещественного числа в десятичном виде повлечет преобразования, невозможные без округлений, поскольку 10 – не степень 2. Шестнадцатеричная форма записи, напротив, позволяет записать число с плавающей запятой точно так, как оно будет представлено. Полный курс по представлению чисел с плавающей запятой выходит за рамки этой книги; отметим лишь, что все реализации D гарантированно используют формат IEEE 754, полную информацию о котором можно найти в Сети (сделайте запрос «формат чисел с плавающей запятой IEEE 754»).
Шестнадцатеричный литерал с плавающей запятой состоит из префикса 0x или 0X, за которым следует строка шестнадцатеричных цифр, содержащая точку в любой позиции. Затем идет обязательный показатель степени8, который начинается с p, P, p+, P+, p- или P- и заканчивается десятичными (не шестнадцатеричными!) цифрами. Только так называемая мантисса – дробная часть перед показателем степени – выражается шестнадцатеричным числом; сам показатель степени – целое десятичное число. Показатель степени шестнадцатеричной константы с плавающей запятой означает степень 2 (а не 10, как в случае с десятичным представлением). Завершается литерал необязательным суффиксом f, F или L9. Рассмотрим несколько подходящих примеров:
auto
a = 1.0, // a имеет тип double
b = .345E2f, // b = 34.5 имеет тип float
c = 10f, // c имеет тип float из-за суффикса
d = 10., // d имеет тип double
e = 0x1.fffffffffffffp1023, // наибольшее возможное значение типа double
f = 0XFp1F; // f = 30.0, тип float
Рисунок 2.2 без лишних слов описывает литералы с плавающей запятой языка D. Правила интерпретации автомата те же, что и для автомата, иллюстрирующего распознавание целых литералов: переход выполняется по мере чтения знаков литерала с целью прочитать как можно больше. Представление в виде автомата проясняет несколько фактов, которые было бы утомительно описывать, не используя формальный аппарат. Например, 0x.p1 и 0xp1 – вполне приемлемые, хотя и странные формы записи нуля, а конструкции типа 0e1, .e1 и 0x0.0 запрещены.
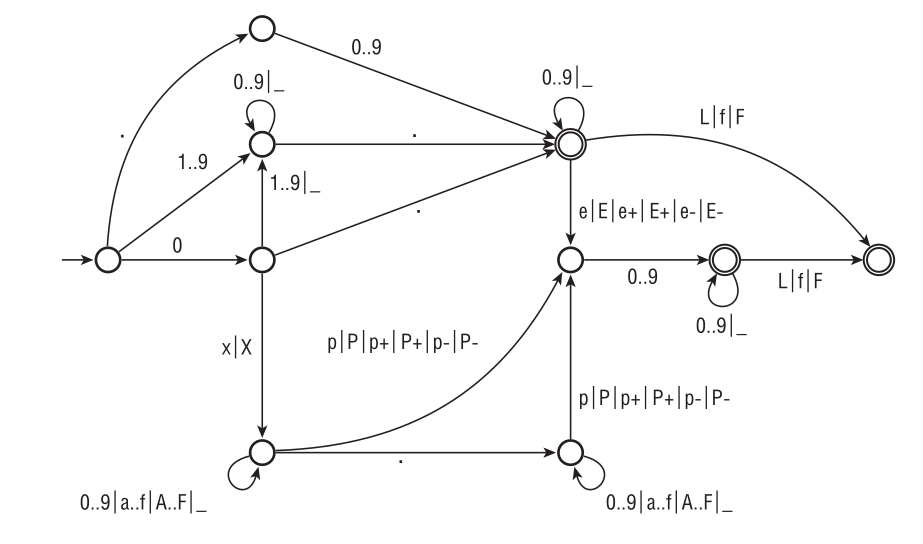
Рис. 2.2. Распознавание литералов с плавающей запятой
2.2.4. Знаковые литералы
Знаковый литерал – это один знак, заключенный в одиночные кавычки, например 'a'. Если в качестве знака выступают сами кавычки, их нужно экранировать с помощью обратной косой черты: '\''. На самом деле в D, как и в других языках, определены несколько разных escape-последовательностей10 (см. табл. 2.3). В дополнение к стандартному набору управляющих непечатаемых символов D предоставляет следующие возможности записать знаки Юникода: '\u03C9' (знаки \u, за которыми следуют ровно 4 шестнадцатеричные цифры), '\U0000211C' (знаки \U, за которыми следуют ровно 8 шестнадцатеричных цифр) и '\©' (имя, окруженное знаками \& и ;). Первый из этих примеров – знак ω в Юникоде, второй – красивая письменная ℬ, а последний – грозный знак ©. Если вам нужен полный список знаков, которые можно отобразить, поищите в Интернете информацию о таблице знаков Юникода.
Таблица 2.3. Экранирующие последовательности в D
| Escape-последовательность | Тип | Описание |
|---|---|---|
\" |
char |
Двойная кавычка (если двусмысленно) |
\\ |
char |
Обратная косая черта |
\a |
char |
Звуковой сигнал (Bell, ASCII 7) |
\b |
char |
Backspace (ASCII 8) |
\f |
char |
Смена страницы (ASCII 12) |
\n |
char |
Перевод строки (ASCII 10) |
\r |
char |
Возврат каретки (ASCII 13) |
\t |
char |
Табуляция (ASCII 9) |
\v |
char |
Вертикальная табуляция (ASCII 11) |
\<1–3 восьмеричные цифры> |
char |
Знак UTF-8 в восьмеричном представлении (не больше 3778) |
\x<2 шестнадцатеричные цифры> |
char |
Знак UTF-8 в шестнадцатеричном представлении |
\u<4 шестнадцатеричные цифры> |
wchar |
Знак UTF-16 в шестнадцатеричном представлении |
\U<8 шестнадцатеричных цифр> |
dchar |
Знак UTF-32 в шестнадцатеричном представлении |
\&<имя знака>; |
dchar |
Имя знака Юникод |
2.2.5. Строковые литералы
Теперь, когда мы знаем, как представляются отдельные знаки, строковые литералы для нас пустяк. D прекрасно справляется с обработкой строк отчасти благодаря своим мощным средствам представления строковых литералов. Как и другие языки, работающие со строками, D различает строки, заключенные в кавычки (внутри которых можно размещать экранированные последовательности из табл. 2.3), и WYSIWYG-строки11 (которые компилятор распознает «вслепую», не пытаясь обнаружить и расшифровать никакие escape-последовательности). Стиль WYSIWYG очень удобен для представления строк, где иначе пришлось бы использовать множество экранированных знаков; два выдающихся примера – регулярные выражения и пути к файлам в системе Windows. Строки, заключенные в кавычки (quoted strings), – это последовательности знаков в двойных кавычках, "как в этом примере". В таких строках все escape-последовательности из табл. 2.3 являются значимыми. Строки всех видов, расположенные подряд, автоматически подвергаются конкатенации:
auto crlf = "\r\n";
auto a = "В этой строке есть \"двойные кавычки\", а также
перевод строки, даже два" "\n";
Текст умышленно перенесен на новую строку после слова также: строковый литерал может содержать знак перевода строки (реальное начало новой строки в исходном коде, а не комбинацию \n), который будет сохранен именно в этом качестве.
2.2.5.1. Строковые литералы: WYSIWYG, с разделителями, строки токенов, шестнадцатеричные и импортированные
WYSIWYG-строка либо начинается с r" и заканчивается на " (r"как здесь"), либо начинается и заканчивается грависом12 (как здесь). В WYSIWYG-строке может встретиться любой знак (кроме соответствующих знаков начала и конца литерала), который хранится так же, как и выглядит. Это означает, что вы не можете представить, например, знак двойной кавычки внутри заключенной в такие же двойные кавычки WYSIWYG-строки. Это не проблема, потому что всегда можно сделать конкатенацию строк, представленных с помощью разных синтаксических правил. Например:
auto a = r"Строка с \ и " `"` " внутри.";
Из практических соображений можно считать, что двойная кавычка внутри r"такой строки" обозначается последовательностью 〈"`"`"〉, а гравис внутри такой строки – последовательностью 〈`"`"`〉. Счастливого подсчета кавычек.
Иногда бывает удобно описать строку, ограниченную с двух сторон какими-то символами. Для этих целей D предоставляет особый вид строковых литералов – литерал с разделителями.
auto a = q"[Какая-то строка с "кавычками", `обратными апострофами` и [квадратными скобками]]";
Теперь в a находится строка, содержащая кавычки, обратные апострофы и квадратные скобки, то есть все, что мы видим между q"[ и ]". И никаких обратных слэшей, нагромождения ненужных кавычек и прочего мусора. Общий формат этого литерала: сначала идет префикс q и двойная кавычка, за которой сразу без пробелов следует знак-разделитель. Оканчивается строка знаком-разделителем и двойной кавычкой, за которой может следовать суффикс, указывающий на тип литерала: c, w или d. Допустимы следующие парные разделители: [ и ], ( и ), < и >, { и }. Допускаются вложения парных разделителей, то есть внутри пары скобок может быть другая пара скобок, которая становится частью строки. В качестве разделителя можно также использовать любой знак, например:
auto a = q"/Просто строка/"; // Эквивалентно строке "Просто строка"
При этом строка распознается до первого вхождения ограничивающего знака:
auto a = q"/Просто/строка/"; // Ошибка.
auto b = q"[]]"; // Опять ошибка.
auto с = q"[[]]"; // А теперь все нормально, т. к. разделители [] допускают вложение.
Если в качестве разделителя нужно использовать какую-то последовательность знаков, открывающую и закрывающую последовательности следует писать на отдельной строке:
auto a = q"EndOfString
Несколько
строк
текста
EndOfString";
Кроме того, D предлагает такой вид строкового литерала, как строка токенов. Такой литерал начинается с последовательности q{ и заканчивается на }. При этом текст, расположенный между { и }, должен представлять из себя последовательность токенов языка D и интерпретируется как есть.
auto a = q{ foo(q{hello}); }; // Эквивалентно " foo(q{hello}); "
auto b = q{ № }; // Ошибка! "№" - не токен языка
auto a = q{ __EOF__ }; // Ошибка! __EOF__ - не токен, а конец файла
Также D определяет еще один вид строковых литералов – шестнадцатеричную строку, то есть строку, состоящую из шестнадцатеричных цифр и пробелов (пробелы игнорируются) между x" и ". Шестнадцатеричные строки могут быть полезны для определения сырых данных; компилятор не пытается интерпретировать содержимое литералов никак знаки Юникода, ни как-то еще – только как шестнадцатеричные цифры. Пробелы внутри строк игнорируются.
auto
a = x"0A", // То же самое, что "\x0A"
b = x"00 F BCD 32"; // То же самое, что "\x00\xFB\xCD\x32"
Если ваш хакерский мозг уже начал прикидывать, как внедрить в программы на D двоичные данные, вы будете счастливы услышать об очень мощном способе определения строки: из файла!
auto x = import("resource.bin");
Во время компиляции переменная x будет инициализирована непосредственно содержимым файла resource.bin. (Это отличается от действия директивы C #include, поскольку в рассмотренном примере файл включается в качестве данных, а не кода.) По соображениям безопасности допустимы только относительные пути и пути поиска контролируются флагами компилятора. Эталонная реализация dmd использует флаг -J для управления путями поиска.
Строка, возвращаемая функцией import, не проверяется на соответствие кодировке UTF-8. Это сделано намеренно – для реализации возможности включать двоичные данные.
2.2.5.2. Тип строкового литерала
Каков тип строкового литерала? Проведем простой эксперимент:
import std.stdio;
void main()
{
writeln(typeid(typeof("Hello, world!")));
}
Встроенный оператор typeof возвращает тип выражения, а typeid конвертирует его в печатаемую строку. Наша маленькая программа печатает:
immutable(char)[]
открывая нам то, что строковые литералы – это массивы неизменяемых знаков. На самом деле, тип string, который мы использовали в примерах, – это краткая форма записи (или псевдоним), означающая immutable(char)[]. Рассмотрим подробно все три составляющие типа строковых литералов: неизменяемость, длина и базовый тип данных – знаковый.
Неизменяемость
Строковые литералы живут в неизменяемой области памяти. Это вовсе не говорит о том, что они хранятся на действительно не стираемых кристаллах ЗУ или в защищенной области памяти операционной системы. Это означает, что язык обязуется не перезаписывать память, выделенную под строку. Ключевое слово immutable воплощает это обязательство, запрещая во время компиляции любые операции, которые могли бы модифицировать содержимое неизменяемых данных, помеченных этим ключевым словом:
auto a = "Изменить этот текст нельзя";
a[0] = 'X'; // Ошибка! Нельзя модифицировать неизменяемую строку!
Ключевое слово immutable – это квалификатор типа (квалификаторы обсуждаются в главе 8); его действие распространяется на любой тип, указанный в круглых скобках после него. Если вы напишете immutable(char)[] str, то знаки в строке str нельзя будет изменять по отдельности, однако str можно заставить ссылаться на другую строку:
immutable(char)[] str = "One";
str[0] = 'X'; // Ошибка! Нельзя присваивать значения переменным типа immutable(char)!
str = "Two"; // Отлично, присвоим str другую строку
С другой стороны, если круглые скобки отсутствуют, квалификатор immutable будет относиться ко всему массиву:
immutable char[] a = "One";
a[0] = 'X'; // Ошибка!
a = "Two"; // Ошибка!
У неизменяемости масса достоинств, а именно: квалификатор immutable предоставляет достаточно гарантий, чтобы разрешить неразборчивое совместное использование данных модулями и потоками (см. главу 13). Поскольку знаки строки неизменяемы, никогда не возникает споров, и совместный доступ безопасен и эффективен.
Длина
Очевидно, что длина строкового литерала (13 для "Hello, world!") известна во время компиляции. Поэтому может казаться естественным давать наиболее точное определение каждой строке; например, строка "Hello, world!" может быть типизирована как char[13], что означает «массив ровно из 13 знаков». Однако опыт языка Паскаль показал, что статические размеры крайне неудобны. Так что в D тип литерала не включает информацию о его длине. Тем не менее, если вы действительно хотите работать со строкой фиксированного размера, то можете создать такую, явно указав ее длину:
immutable(char)[13] a = "Hello, world!";
char[13] b = "Hello, world!";
Типы массивов фиксированного размера T[N] могут неявно конвертироваться в типы динамических массивов T[] для всех типов T. В процессе преобразования информация не теряется, так как динамические массивы «помнят» свою длину:
import std.stdio;
void main()
{
immutable(char)[3] a = "Hi!";
immutable(char)[] b = a;
writeln(a.length, " ", b.length); // Печатает "3 3"
}
Базовый тип данных – знаковый
Последнее, но немаловажное, что нужно сказать о строковых литералах, – в качестве их базового типа может выступать char, wchar или dchar13. Использовать многословные имена типов необязательно: string, wstring и dstring – удобные псевдонимы для immutable(char)[], immutable(wchar)[] и immutable(dchar)[] соответственно. Если строковый литерал содержит хотя бы один 4-байтный знак типа dchar, то строка принимает тип dstring; иначе, если строка содержит хотя бы один 2-байтный знак типа wchar, то строка принимает тип wstring, иначе строка принимает знакомый тип string. Если ожидается тип, отличный от определяемого по контексту, литерал молча уступит, как в этом примере:
wstring x = "Здравствуй, широкий мир!"; // UTF-16
dstring y = "Здравствуй, еще более широкий мир!"; // UTF-32
Если вы хотите явно указать тип строки, то можете снабдить строковый литерал суффиксом: c, w или d, которые заставляют тип строкового литерала принять значение string, wstring или dstring соответственно.
2.2.6. Литералы массивов и ассоциативных массивов
Cтрока – это частный случай массива со своим синтаксисом литералов. А как представить литерал массива другого типа, например int или double? Литерал массива задается заключенным в квадратные скобки списком значений, разделенных запятыми14:
auto somePrimes = [ 2u, 3, 5, 7, 11, 13 ];
auto someDoubles = [ 1.5, 3, 4.5 ];
Размер массива вычисляется по количеству разделенных запятыми элементов списка. В отличие от строковых литералов, литералы массивов изменяемы, так что вы можете изменить их после инициализации:
auto constants = [ 2.71, 3.14, 6.023e22 ];
constants[0] = 2.21953167; // "Константа дивана"
auto salutations = [ "привет", "здравствуйте", "здорово" ];
salutations[2] = "Да здравствует Цезарь";
Обратите внимание: можно присвоить новую строку элементу массива salutations, но нельзя изменить содержимое старой строки, хранящееся в памяти. Этого и следовало ожидать, потому что членство в массиве не отменяет правил работы с типом string.
Тип элементов массива определяется «соглашением» между всеми элементами массива, которое вычисляется с помощью оператора сравнения ?: (см. раздел 2.3.16). Для литерала lit, содержащего больше одного элемента, компилятор вычисляет выражение true ? lit[0] : lit[1] и сохраняет тип этого выражения как тип L. Затем для каждого i-го элемента lit[i] до последнего элемента в lit компилятор вычисляет тип true ? L.init : lit[i] и снова сохраняет это значение в L. Конечное значение L и есть тип элементов массива.
На самом деле, все гораздо проще, чем кажется, – тип элементов массива устанавливается аналогично Польскому демократическому соглашению15: ищется тип, в который можно неявно конвертировать все элементы массива. Например, тип массива [1, 2, 2.2] – double, а тип массива [1, 2, 3u] – uint, так как результатом операции ?: с аргументами int и uint будет uint.
Литерал ассоциативного массива задается так:
auto famousNamedConstants = [ "пи" : 3.14, "e" : 2.71, "константа дивана" : 2.22 ];
Каждая ячейка литерала ассоциативного массива имеет вид ключ: значение. Тип ключей литерала ассоциативного массива вычисляется по массиву, в который неявно записываются все эти ключи, с помощью описанного выше способа. Тип значений вычисляется аналогично. После вычисления типа ключей K и типа значений V литерал типизируется как V[K]. Например, константа famousNamedConstants принимает тип double[string].
2.2.7. Функциональные литералы
В некоторых языках имя функции задается в ее определении; впоследствии такие функции вызываются по именам. Другие языки предоставляют возможность определить анонимную функцию (так называемую лямбда-функцию) прямо там, где она должна использоваться. Такое средство помогает строить мощные конструкции, задействующие функции более высокого порядка, то есть функции, принимающие в качестве аргументов и/или возвращающие другие функции. Функциональные литералы D позволяют определять анонимные функции in situ16 – когда бы ни ожидалось имя функции.
Задача этого раздела – всего лишь показать на нескольких интересных примерах, как определяются функциональные литералы. Примеры более действенного применения этого мощного средства отложим до главы 5. Вот базовый синтаксис функционального литерала:
auto f = function double(int x) { return x / 10.; };
auto a = f(5);
assert(a == 0.5);
Функциональный литерал определяется по тем же синтаксическим правилам, что и функция, с той лишь разницей, что определению предшествует ключевое слово function, а имя функции отсутствует. Рассмотренный пример в общем-то даже не использует анонимность, так как анонимная функция немедленно связывается с идентификатором f. Тип f – «указатель на функцию, принимающую int и возвращающую double». Этот тип записывается как double function(int) (обратите внимание: ключевое слово function и возвращаемый тип поменялись местами), так что эквивалентное определение f выглядит так:
double function(int) f = function double(int x) { return x / 10.; };
Кажущаяся странной перестановка function и double на самом деле сильно облегчает всем жизнь, позволяя отличить функциональный литерал по типу. Формулировка для легкого запоминания: слово function стоит в начале определения литерала, а в типе функции замещает имя функции.
Для простоты в определении функционального литерала можно опустить возвращаемый тип – компилятор определит его для вас по контексту, ведь ему тут же доступно тело функции.
auto f = function(int x) { return x / 10.; };
Наш функциональный литерал использует только собственный параметр x, так что его значение можно выяснить, взглянув лишь на тело функции и не принимая во внимание окружение, в котором она используется. Но что если функциональному литералу потребуется использовать данные, которые присутствуют в точке вызова, но не передаются как аргумент? В этом случае нужно заменить слово function словом delegate:
int c = 2;
auto f = delegate double(int x) { return c * x / 10.; };
auto a = f(5);
assert(a == 1);
c = 3;
auto b = f(5);
assert(b == 1.5);
Теперь тип f – delegate double(int x). Все правила распознавания типа для function применимы без изменений к delegate. Отсюда справедливый вопрос: если конструкции delegate могут делать все, на что способны function-конструкции (в конце концов конструкции delegate могут, но не обязаны использовать переменные своего окружения), зачем же сначала возиться с функциями? Нельзя ли всегда использовать конструкции delegate? Ответ прост: все дело в эффективности. Очевидно, что конструкции delegate обладают доступом к большему количеству информации, а по непреложному закону природы за такой доступ приходится расплачиваться. На самом деле, размер function равен размеру указателя, а delegate – в два раза больше (один указатель на функцию, один – на окружение).
-
Впрочем, использование нелатинских букв является дурным тоном. – Прим. науч. ред. ↩︎
-
С99 – обновленная спецификация C, в том числе добавляющая поддержку знаков Юникода. – Прим. пер. ↩︎
-
Сам язык не поддерживает восьмеричные литералы, но поскольку они присутствуют в некоторых C-подобных языках, в стандартную библиотеку был добавлен соответствующий шаблон. Теперь запись
std.conv.octal!777аналогична записи0777в C. – Прим. науч. ред. ↩︎ -
Для тех, кто готов воспринимать теорию: автоматы на рис. 2.1 и 2.2 – это детерминированные конечные автоматы (ДКА). ↩︎
-
В России в качестве разделителя целой и дробной части чисел с плавающей запятой принята запятая (поэтому и говорят: «числа с плавающей запятой»), однако в англоговорящих странах для этого служит точка, поэтому в языках программирования (обычно основанных на английском – международном языке информатики) разделителем является точка. – Прим. пер. ↩︎
-
Показатель степени 10 по-английски – exponent, поэтому для его обозначения и используется буква
e. – Прим. пер. ↩︎ -
Запись
Epозначает «умножить на 10 в степениp», то естьp– это порядок. – Прим. пер. ↩︎ -
Степень по-английски – power, поэтому показатель степени 2 обозначается буквой
p. – Прим. пер. ↩︎ -
Да, синтаксис странноватый, но D скопировал его из стандарта C99, чтобы не изобретать свою нотацию с собственными выкрутасами, которых все равно не избежать. ↩︎
-
Escape-последовательность (от англ. escape – избежать), экранирующая/управляющая последовательность – специальная комбинация знаков, отменяющая стандартную обработку компилятором следующих за ней знаков (они как бы «исключаются из рассмотрения»). – Прим. пер. ↩︎
-
WYSIWIG – акроним «What You See Is What You Get» (что видишь, то и получишь) – способ представления, при котором данные в процессе редактирования выглядят так же, как и в результате обработки каким-либо инструментом (компилятором, после отображения браузером и т. п.). – Прим. пер. ↩︎
-
Он же обратный апостроф. – Прим. науч. ред. ↩︎
-
Префиксы
wиd– от англ. wide (широкий) и double (двойной) – Прим. науч. ред. ↩︎ -
В литерале массива допустима запятая, после которой нет элемента, например [1, 2,] – длина этого массива равна 2, а последняя запятая попросту игнорируется. Это сделано для удобства автоматических генераторов кода: при генерации текста литерала массива они конкатенируют строки вида
"очередной_элемент", не обрабатывая отдельно последний элемент, запятая после которого была бы не нужна. – Прим. науч. ред. ↩︎ -
Заключенное в 1989 году соглашение между коммунистами и демократами, ознаменовавшее собой достижение компромисса между двумя партиями. В данном случае также ищется «компромиссный» тип. – Прим. пер. ↩︎
-
In situ (лат.) – на месте. – Прим. пер. ↩︎