| .. | ||
| images | ||
| README.md | ||
11. Расширение масштаба
- 11.1. Пакеты и модули
- 11.1.1. Объявления import
- 11.1.2. Базовые пути поиска модулей
- 11.1.3. Поиск имен
- 11.1.4. Объявления public import
- 11.1.5. Объявления static import
- 11.1.6. Избирательные включения
- 11.1.7. Включения с переименованием
- 11.1.8. Объявление модуля
- 11.1.9. Резюме модулей
- 11.2. Безопасность
- 11.2.1. Определенное и неопределенное поведение
- 11.3.2. Атрибуты @safe, @trusted и @system
- 11.3. Конструкторы и деструкторы модулей
- 11.3.1. Порядок выполнения в рамках модуля
- 11.3.2. Порядок выполнения при участии нескольких модулей
- 11.4. Документирующие комментарии
- 11.5. Взаимодействие с C и C++
- 11.5.1. Взаимодействие с классами C++
- 11.6. Ключевое слово deprecated
- 11.7. Объявления версий
- 11.8. Отладочные объявления
- 11.9. Стандартная библиотека D
- 11.10. Встроенный ассемблер
- 11.10.1. Архитектура x86
- 11.10.2. Архитектура x86-64
- 11.10.3. Разделение на версии
- 11.10.4. Соглашения о вызовах
- 11.10.5. Рациональность
Поговорка гласит, что программу в 100 строк можно заставить работать, даже если она нарушает все законы правильного кодирования. Эта поговорка расширяема: действительно, можно написать программу в 10 000 строк, уделяя внимание лишь деталям кода и не соблюдая никаких более масштабных правил надлежащей модульной разработки. Возможно, где-то есть и проекты в несколько миллионов строк, нарушающие немало правил крупномасштабной разработки.
Многие твердые принципы разработки программного обеспечения также производят впечатление расширяемых. Разделение ответственности и сокрытие информации одинаково работают в случае небольшого модуля и при соединении целых приложений. Воплощение этих принципов, тем не менее, варьируется в зависимости от уровня, на котором эти принципы применяются. Эта часть посвящена сборке более крупных сущностей – целых файлов, каталогов, библиотек и программ.
Определяя свой подход к крупномасштабной модульности, D следует отдельным хорошо зарекомендовавшим себя принципам, а также вводит пару любопытных инноваций относительно поиска имен.
11.1. Пакеты и модули
Единицей компиляции, защиты и инкапсуляции является физический файл. Единицей логического объединения множества файлов является каталог. Вот и все сложности. С точки зрения модульности мы обращаемся к файлу с исходным кодом на D как к модулю, а к каталогу, содержащему файлы с исходным кодом на D, – как к пакету.
Нет причин думать, что исходному коду программы на самом деле будет удобнее в какой-нибудь супер-пупер базе данных. D использует «базу данных», которую долгое время настраивали лучшие из нас и которая прекрасно интегрируется со средствами обеспечения безопасности, системой управления версиями, защитой на уровне ОС, журналированием – со всем, что бы вы ни назвали, а также устанавливает низкий барьер входа для широкомасштабной разработки, поскольку основные необходимые инструменты – это редактор и компилятор.
Модуль D – это текстовый файл с расширением .d или .di. Инструментарий D не учитывает расширения файлов при обработке, но по общему соглашению в файлах с расширением .d находится код реализации, а в файлах с расширением .di (от D interface – интерфейс на D) – код интерфейсов. Текст файла должен быть в одной из следующих кодировок: UTF-8, UTF-16, UTF-32. В соответствии с небольшим стандартизированным протоколом, известным как BOM (byte order mark – метка порядка байтов), порядок следования байтов в файле (в случае UTF-16 или UTF-32) определяется несколькими первыми байтами файла. В табл. 11.1 показано, как компиляторы D идентифицируют кодировку файлов с исходным кодом (в соответствии со стандартом Юникод).
Таблица 11.1. Для различения файлов с исходным кодом на D используют ся метки порядка байтов. Шаблоны проверяются сверху вниз, первое же совпадение при сопоставлении устанавливает кодировку файла. xx – любое ненулевое значение байта
| Если первые байты... | ...то кодировка файла – ... | Игнорировать эти байты? |
|---|---|---|
00 00 FE FF |
UTF-32 с прямым порядком байтов1 | ✓ |
FF FE 00 00 |
UTF-32 с обратным порядком байтов2 | ✓ |
FE FF |
UTF-16 с прямым порядком байтов | ✓ |
FF FE |
UTF-16 с обратным порядком байтов | ✓ |
00 00 00 xx |
UTF-32 с прямым порядком байтов | |
xx 00 00 00 |
UTF-32 с обратным порядком байтов | |
00 xx |
UTF-16 с прямым порядком байтов | |
xx 00 |
UTF-16 с обратным порядком байтов | |
| Что-то другое | UTF-8 |
В некоторых файлах метка порядка байтов отсутствует, но у D есть средство, позволяющее автоматически недвусмысленно определить кодировку. Процедура автоопределения тонко использует тот факт, что любой правильно построенный модуль на D должен начинаться хотя бы с нескольких знаков, встречающихся в кодировке ASCII, то есть с кодовых точек Юникода со значением меньше 128. Ведь в соответствии с грамматикой D правильно построенный модуль должен начинаться или с ключевого слова языка D (состоящего из знаков Юникода с ASCII-кодами), или с ASCII-пробела, или с комментария, который начинается с ASCII-знака /, или с пары директив, начинающихся с #, которые также должны состоять из ASCII-знаков. Если выполнить проверку на соответствие шаблонам из табл. 11.1, перебирая эти шаблоны сверху вниз, первое же совпадение недвусмысленно укажет кодировку. Если кодировка определена ошибочно, вреда от этого все равно не будет – файл, несомненно, и так ошибочен, поскольку начинается со знаков, которые не может содержать корректный код на D.
Если первые два знака (после метки порядка байтов, если она есть) – это знаки #!, то эти знаки плюс следующие за ними знаки вплоть до первого символа новой строки \n игнорируются. Это позволяет использовать средство «shebang»3 тем системам, которые его поддерживают.
11.1.1. Объявления import
Для получения доступа к благам стандартной библиотеки в примерах кода из предыдущих глав обычно использовалась инструкция import:
import std.stdio; // Получить доступ к writeln и всему остальному
Чтобы включить один модуль в другой, укажите имя модуля в объявлении import. Имя модуля должно содержать путь до него относительно каталога, где выполняется компиляция. Рассмотрим пример иерархии каталогов (рис. 11.1).
Предположим, компиляция выполняется в каталоге root. Чтобы получить доступ к определениям файла widget.d из любого другого файла, этот другой файл должен содержать объявление верхнего уровня:
import widget;
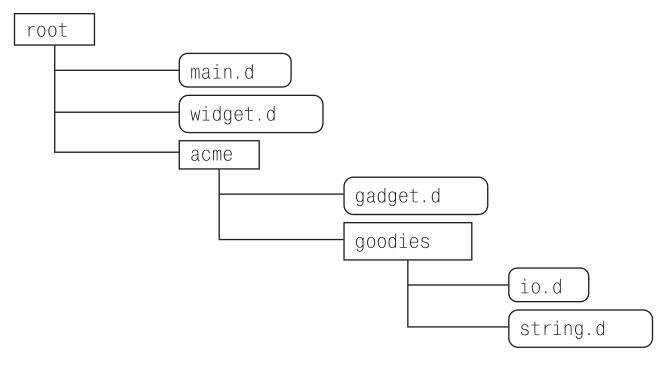
Рис. 11.1. Пример структуры каталога
«Объявление верхнего уровня» – это объявление вне всех контекстов (таких как функция, класс и структура)4. Встретив это объявление import, компилятор начнет искать widget.di (сначала) или widget.d (потом) начиная с каталога root, найдет widget.d и импортирует его идентификаторы. Чтобы использовать файл, расположенный глубже в иерархии каталогов, другой файл проекта должен содержать объявление import с указанием относительного пути до него от каталога root с точкой . в качестве разделителя:
import acme.gadget;
import acme.goodies.io;
В объявлениях import мы обычно используем списки значений, разделенных запятыми. Два предыдущих объявления эквивалентны следующему:
import acme.gadget, acme.goodies.io;
Обратите внимание: файл, расположенный на более низком уровне иерархии каталогов, такой как gadget.d, также должен указывать путь к другим файлам относительно каталога root, где выполняется компиляция, а не относительно собственного расположения. Например, чтобы получить доступ к идентификаторам файла io.d, файл gadget.d должен содержать объявление:
import acme.goodies.io;
а не
import goodies.io;
Другой пример: если файл io.d хочет включить файл string.d, то он должен содержать объявление import acme.goodies.string, хотя оба этих файла находятся в одном каталоге. Разумеется, в данном случае предполагается, что компиляция выполняется в каталоге root. Если вы перешли в каталог acme и компилируете gadget.d там, он должен содержать объявление import goodies.io.
Порядок включения модулей не имеет значения. Язык задуман таким образом, что семантика модуля не зависит от порядка, в каком этот модуль включает другие модули.
Объявление import присоединяет только идентификаторы (символы), следовательно, пакеты и модули на D должны иметь имена, являющиеся допустимыми идентификаторами языка D (см. раздел 2.1). Например, если у вас есть файл 5th_element.d, то вы просто не сможете включить его в другой модуль, поскольку «5th_element» не является допустимым идентификатором D. Точно так же, если вы храните файлы в каталоге input-output, то не сможете использовать этот каталог как пакет D. Иными словами, все файлы и каталоги, содержащие исходный код на языке D, должны носить лишь имена, являющиеся допустимыми идентификаторами. Дополнительное соглашение: имена всех пакетов и модулей не содержат заглавных букв. Цель этого соглашения – предотвратить путаницу в операционных системах с нестрогой обработкой регистра букв в именах файлов.
11.1.2. Базовые пути поиска модулей
Анализируя объявление import, компилятор выполняет поиск не только относительно текущего каталога, где происходит компиляция. Иначе невозможно было бы использовать ни одну из стандартных библиотек или других библиотек, развернутых за пределами каталога текущего проекта. В конце концов мы постоянно включаем модули из пакета std, хотя в поле зрения наших проектов нет никакого подкаталога std. Как же работает этот механизм?
Как и многие другие языки, D позволяет задать набор базовых путей (roots), откуда начинается поиск модулей. С помощью аргумента, передаваемого компилятору из командной строки, к списку базовых путей поиска модулей можно добавить любое количество каталогов. Точный синтаксис этой операции зависит от компилятора; эталонный компилятор dmd использует флаг командной строки -I, сразу за которым указывается путь, например -Ic:\Programs\dmd\src\phobos для Windows-версии и -I/usr/local/src/phobos для UNIX-версии. С помощью дополнительных флагов -I можно добавить любое количество путей в список путей поиска.
Например, при анализе объявления import path.to.file сначала подкаталог path/to5 ищется в текущем каталоге. Если такой подкаталог существует, запрашивается файл file.d. Если файл найден, поиск завершается. В противном случае такой же поиск выполняется, начиная с каждого из базовых путей, заданных с помощью флага -I. Поиск завершается при первом нахождении модуля; если же все каталоги пройдены безрезультатно, компиляция прерывается с ошибкой «модуль не найден».
Если компонент path.to отсутствует, поиск модуля будет осуществляться непосредственно в базовых каталогах.
Для пользователя было бы обременительно добавлять флаг командной строки только для того, чтобы получить доступ к стандартной библиотеке или другим широко используемым библиотекам. Вот почему эталонный компилятор (и фактически любой другой) использует простой конфигурационный файл, содержащий несколько флагов командной строки по умолчанию, которые автоматически добавляются к каждому вызову компилятора из командной строки. Сразу после инсталляции компилятора конфигурационный файл должен содержать такие установки, чтобы с его помощью можно было найти, по крайней мере, библиотеку поддержки времени исполнения и стандартную библиотеку. Поэтому если вы просто введете
% dmd main.d
то компилятор сможет найти все артефакты стандартной библиотеки, не требуя никаких параметров в командной строке. Чтобы точно узнать, где ищется каждый из модулей, можно при запуске компилятора dmd добавить флаг -v (от verbose – подробно). Подробное описание того, как установленная вами версия D загружает конфигурационные параметры, вы найдете в документации для нее (в случае dmd документация размещена в Интернете).
В начало ⮍ Наверх ⮍
11.1.3. Поиск имен
Как ни странно, в D нет глобального контекста или глобального пространства имен. В частности, нет способа определить истинно глобальный объект, функцию или имя класса. Причина в том, что единственный способ определить такую сущность – разместить ее в модуле, а у любого модуля должно быть имя. В свою очередь, имя модуля порождает именованный контекст. Даже Object, предок всех классов, в действительности не является глобальным именем: на самом деле, это объект object.Object, поскольку он вводится в модуле object, поставляемом по умолчанию. Вот, например, содержимое файла widget.d:
// Содержимое файла widget.d
void fun(int x)
{
...
}
С определением функции fun не вводится глобально доступный идентификатор fun. Вместо этого все, кто включает модуль widget (например, файл main.d), получают доступ к идентификатору widget.fun:
// Содержимое main.d
import widget;
void main()
{
widget.fun(10); // Все в порядке, ищем функцию fun в модуле widget
}
Все это очень хорошо и модульно, но при этом довольно многословно и неоправданно строго. Если нужна функция fun и никто больше ее не определяет, почему компилятор не может просто отдать предпочтение widget.fun как единственному претенденту?
На самом деле, именно так и работает поиск имен. Каждый включаемый модуль вносит свое пространство имен, но когда требуется найти идентификатор, предпринимаются следующие шаги:
- Идентификатор ищется в текущем контексте. Если идентификатор найден, поиск успешно завершается.
- Идентификатор ищется в контексте текущего модуля. Если идентификатор найден, поиск успешно завершается.
- Идентификатор ищется во всех включенных модулях:
- если идентификатор не удается найти, поиск завершается неудачей;
- если идентификатор найден в единственном модуле, поиск успешно завершается;
- если идентификатор найден более чем в одном модуле и этот идентификатор не является именем функции, поиск завершается с ошибкой, выводится сообщение о дублировании идентификатора;
- если идентификатор найден более чем в одном модуле и этот идентификатор является именем функции, применяется механизм разрешения имен при кроссмодульной перегрузке (см. раздел 5.5.2).
Привлекательным следствием такого подхода является то, что клиентский код обычно может быть кратким, а многословным только тогда, когда это действительно необходимо. В предыдущем примере функция main.d могла вызвать fun проще, без каких-либо «украшений»:
// Содержимое main.d
import widget;
void main()
{
fun(10); // Все в порядке, идентификатор fun определен только в модуле widget
}
Пусть в файле io.d также определена функция fun с похожей сигнатурой:
// Содержимое io.d из каталога acme/goodies
void fun(long n)
{
...
}
И пусть модуль с функцией main включает и файл widget.d, и файл io.d. Тогда «неприукрашенный» вызов fun окажется ошибочным, но уточненные вызовы с указанием имени модуля по-прежнему будут работать нормально:
// Содержимое main.d
import widget, acme.goodies.io;
void main()
{
fun(10); // Ошибка! Двусмысленный вызов функции fun(): идентификатор fun найден в модулях widget и acme.goodies.io
widget.fun(10); // Все в порядке, точное указание
acme.goodies.io.fun(10); // Все в порядке, точное указание
}
Обратите внимание: сама собой двусмысленность не проявляется. Если вы не попытаетесь обратиться к идентификатору в двусмысленной форме, компилятор никогда не пожалуется.
В начало ⮍ Наверх ⮍
11.1.3.1. Кроссмодульная перегрузка функций
В разделе 5.5.2 обсуждается вопрос перегрузки функций в случае их расположения в разных модулях и приводится пример, в котором модули, определяющие функцию с одним и тем же именем, вовсе необязательно порождают двусмысленность. Теперь, когда мы уже знаем больше о модулях и модульности, пора поставить точку в этом разговоре.
Угон функций (function hijacking) представляет собой особенно хитрое нарушение модульности. Угон функций имеет место, когда функция в некотором модуле состязается за вызовы из функции в другом модуле и принимает их на себя. Типичное проявление угона функций: работающий модуль ведет себя по-разному в зависимости от того, каковы другие включенные модули, или от порядка, в котором эти модули включены.
Угоны могут появляться как следствие непредвиденных эффектов в других случаях исправно выполняемых и благонамеренных правил. В частности, кажется логичным, чтобы в предыдущем примере, где модуль widget определяет fun(int), а модуль acme.goodies.io – fun(long), вызов fun(10), сделанный в main, был присужден функции widget.fun, поскольку это «лучший» вариант. Однако это один из тех случаев, когда лучшее – враг хорошего. Если модуль с функцией main включает только acme.goodies.io, то вызов fun(10), естественно, отдается acme.goodies.io.fun как единственному кандидату. Однако если на сцену выйдет модуль widget, вызов fun(10) неожиданно переходит к widget.fun. На самом деле, widget вмешивается в контракт, который изначально заключался между main и acme.goodies.io – ужасное нарушение модульности.
Неудивительно, что языки программирования остерегаются угона. C++ разрешает угон функций, но большинство руководств по стилю программирования советуют этого приема избегать; а Python, как и многие другие языки, и вовсе запрещает любой угон. С другой стороны, переизбыток воздержания может привести к излишне строгим правилам, воспитывающим привычку использовать в именах длинные строки идентификаторов.
D разрешает проблему угона оригинальным способом. Основной руководящий принцип подхода D к кроссмодульной перегрузке состоит в том, что добавление или уничтожение включаемых модулей не должно влиять на разрешение имени функции. Возня с инструкциями import может привести к тому, что ранее компилируемые модули перестанут компилироваться, а ранее некомпилируемые модули станут компилируемыми. Опасный сценарий, который D исключает, – тот, при котором, поиграв с объявлениями import, вы оставите программу компилируемой, но с разными результатами разрешения имен при перегрузке.
Для любого вызова функции, найденного в модуле, справедливо, что если имя этой функции найдено более чем в одном модуле и если вызов может сработать с версией функции из любого модуля, то такой вызов ошибочен. Если же вызов можно заставить работать лишь при одном варианте разрешения имени, такой вызов легален, поскольку при таких условиях нет угрозы угона.
В приведенном примере, где widget определяет fun(int), а acme.goodies.io – fun(long), положение дел в модуле main таково:
import widget, acme.goodies.io;
void main()
{
fun(10); // Ошибка! Двусмысленная кроссмодульная перегрузка!
fun(10L); // Все в порядке, вызов недвусмысленно переходит к acme.goodies.io.fun
fun("10"); // Ошибка! Ничего не подходит!
}
Добавив или удалив из инструкции import идентификатор widget или acme.goodies.io, можно заставить сломанную программу работать, или сломать работающую программу, или оставить работающую программу работающей – но никогда с различными решениями относительно вызовов fun в последнем случае.
В начало ⮍ Наверх ⮍
11.1.4. Объявления public import
По умолчанию поиск идентификаторов во включаемых модулях не является транзитивным. Рассмотрим каталог на рис. 11.1. Если модуль main включает модуль widget, а модуль widget в свою очередь включает модуль acme.gadget, то поиск идентификатора, начатый из main, в модуле acme.gadget производиться не будет. Какие бы модули ни включал модуль widget, это лишь деталь реализации модуля widget, и для main она не имеет значения.
Тем не менее может статься, что модуль widget окажется лишь расширением другого модуля или будет иметь смысл лишь в связке с другим модулем. Например, определения из модуля widget могут использовать и требовать так много определений из модуля acme.goodies.io, что для любого другого модуля было бы бесполезно использовать widget, не включив также и acme.goodies.io. В таких случаях вы можете помочь клиентскому коду, воспользовавшись объявлением public import:
// Содержимое widget.d
// Сделать идентификаторы из acme.goodies.io видимыми всем клиентам widget
public import acme.goodies.io;
Данное объявление public import делает все идентификаторы, определенные модулем acme/goodies/io.d, видимыми из модулей, включающих widget.d (внимание) как будто widget.d определил их сам. По сути, public import добавляет в widget.d объявление alias для каждого идентификатора из io.d. (Дублирование кода объектов не происходит, только некоторое дублирование идентификаторов.) Предположим, что модуль io.d определяет функцию print(string), а в функцию main.d поместим следующий код:
import widget;
void main()
{
print("Здравствуй"); // Все в порядке, идентификатор print найден
widget.print("Здравствуй"); // Все в порядке, widget фактически определяет print
}
Что если на самом деле включить в main и модуль acme.goodies.io? Попробуем это сделать:
import widget;
import acme.goodies.io; // Излишне, но безвредно
void main()
{
print("Здравствуй"); // Все в порядке...
widget.print("Здравствуй"); // ...в порядке...
acme.goodies.io.print("Здравствуй"); // ... и в порядке!
}
Модулю io.d вред не нанесен: тот факт, что модуль widget определяет псевдоним для acme.goodies.io, ни в коей мере не влияет на исходный идентификатор. Дополнительный псевдоним – это просто альтернативное средство получения доступа к одному и тому же определению.
Наконец, в некотором более старом коде можно увидеть объявления private import. Такая форма использования допустима и аналогична обычному объявлению import.
В начало ⮍ Наверх ⮍
11.1.5. Объявления static import
Иногда добавление включаемого модуля в неявный список для поиска идентификаторов при объявлении import (в соответствии с алгоритмом из раздела 11.1.3) может быть нежелательным. Бывает уместным желание осуществлять доступ к определенному в модуле функционалу только с явным указанием полного имени (а-ля имямодуля.имяидентификатора, а не имяидентификатора).
Простейший случай, когда такое решение оправданно, – использование очень популярного модуля в связке с модулем узкого назначения при совпадении ряда идентификаторов в этих модулях. Например, в стандартном модуле std.string определены широко используемые функции для обработки строк. Если вы взаимодействуете с устаревшей системой, применяющей другую кодировку (например, двухбайтный набор знаков, известный как DBCS – Double Byte Character Set), то захотите использовать идентификаторы из std.string в большинстве случаев, а идентификаторы из собственного модуля dbcs_string – лишь изредка и с точным указанием. Для этого нужно просто указать в объявлении import для dbcs_string ключевое слово static:
import std.string; // Определяет функцию string toupper(string)
static import dbcs_string; // Тоже определяет функцию string toupper(string)
void main()
{
auto s1 = toupper("hello"); // Все в порядке
auto s2 = dbcs_string.toupper("hello"); // Все в порядке
}
Уточним: если бы этот код не включал объявление import std.string, первый вызов просто не компилировался бы. Для static import поиск идентификаторов не автоматизируется, даже когда идентификатор недвусмысленно разрешается.
Бывают и другие ситуации, когда конструкция static import может быть полезной. Сдержать автоматический поиск и использовать более многословный, но одновременно и более точный подход может пожелать и модуль, включающий множество других модулей. В таких случаях ключевое слово static полезно использовать с целыми списками значений, разделенных запятыми:
static import teleport, time_travel, warp;
Или располагать его перед контекстом, заключенным в скобки, с тем же результатом:
static
{
import teleport;
import time_travel, warp;
}
В начало ⮍ Наверх ⮍
11.1.6. Избирательные включения
Другой эффективный способ справиться с конфликтующими идентификаторами – включить лишь определенные идентификаторы из модуля. Для этого используйте следующий синтаксис:
// Содержимое main.d
import widget : fun, gun;
Избирательные включения обладают точностью хирургического лазера: данное объявление import вводит ровно два идентификатора – fun и gun. После избирательного включения невидим даже идентификатор widget! Предположим, модуль widget определяет идентификаторы fun, gun и hun. В таком случае fun и gun можно будет использовать только так, будто их определил сам модуль main. Любые другие попытки, такие как hun, widget.hun и даже widget.fun, незаконны:
// Содержимое main.d
import widget : fun, gun;
void main()
{
fun(); // Все в порядке
gun(); // Все в порядке
hun(); // Ошибка!
widget.fun(); // Ошибка!
widget.hun(); // Ошибка!
}
Высокая точность и контроль, предоставляемые избирательным включением, сделали это средство довольно популярным – есть программисты, не приемлющие ничего, кроме избирательного включения; особенно много таких среди тех, кто прежде работал с языками, обладающими более слабыми механизмами включения и управления видимостью. И все же необходимо отметить, что другие упомянутые выше механизмы уничтожения двусмысленности, которые предоставляет D, ничуть не менее эффективны. Полный контроль над включаемыми идентификаторами был бы гораздо более полезен, если бы механизм поиска идентификаторов, используемый D по умолчанию, не был безошибочным.
В начало ⮍ Наверх ⮍
11.1.7. Включения с переименованием
Большие проекты имеют тенденцию создавать запутанные иерархии пакетов. Чрезмерно ветвистые структуры каталогов – довольно частый артефакт разработки, особенно в проектах, где заранее вводят щедрую, всеобъемлющую схему именования, способную сохранить стабильность даже при непредвиденных добавлениях в проект. Вот почему нередки ситуации, когда модулю приходится использовать очень глубоко вложенный модуль:
import util.container.finite.linear.list;
В таких случаях может быть весьма полезно включение с переименованием, позволяющее присвоить сущности util.container.finite.linear.list короткое имя:
import list = util.container.finite.linear.list;
С таким объявлением import программа может использовать идентификатор list.symbol вместо чересчур длинного идентификатора util.container.finite.linear.list.symbol. Если исходить из того, что модуль, о котором идет речь, определяет класс List, в итоге получим:
import list = util.container.finite.linear.list;
void main()
{
auto lst1 = new list.List; // Все в порядке
auto lst2 = new util.container.finite.linear.list.List; // Ошибка! Идентификатор util не определен!
auto lst3 = new List; // Ошибка! Идентификатор List не определен!
}
Включение с переименованием не делает видимыми переименованные пакеты (то есть util, container, ..., list), так что попытка использовать исходное длинное имя в определении lst2 завершается неудачей при поиске первого же идентификатора util. Кроме того, включение с переименованием, без сомнения, обладает статической природой (см. раздел 11.1.5) в том смысле, что не использует механизм автоматического поиска; вот почему не вычисляется выражение new List. Если вы действительно хотите не только переименовать идентификаторы, но еще и сделать их видимыми, очень удобно использовать конструкцию alias (см. раздел 7.4):
import util.container.finite.linear.list; // Нестатическое включение
alias util.container.finite.linear.list list; // Для удобства
void main()
{
auto lst1 = new list.List; // Все в порядке
auto lst2 = new util.container.finite.linear.list.List; // Все в порядке
auto lst3 = new List; // Все в порядке
}
Переименование также может использоваться в связке с избирательными включениями (см. раздел 11.1.6). Продемонстрируем это на примере:
import std.stdio : say = writeln;
void main()
{
say("Здравствуй, мир!"); // Все в порядке, вызвать writeln
std.stdio.say("Здравствуй, мир"); // Ошибка!
writeln("Здравствуй, мир!"); // Ошибка!
std.stdio.writeln("Здравствуй, мир!"); // Ошибка!
}
Как и ожидалось, применив избирательное включение, которое одновременно еще и переименовывает идентификатор, вы делаете видимым лишь включаемый идентификатор и ничего больше.
Наконец, можно переименовать и модуль, и включаемый идентификатор (включаемые идентификаторы):
import io = std.stdio : say = writeln, CFile = File;
Возможные взаимодействия между двумя переименованными включенными идентификаторами могли бы вызвать некоторые противоречия. Язык D решил этот вопрос, просто сделав предыдущее объявление тождественным следующим:
import io = std.stdio : writeln, File;
import std.stdio : say = writeln, CFile = File;
Дважды переименовывающее объявление import эквивалентно двум другим объявлениям. Первое из этих объявлений переименовывает только модуль, а второе – только включаемый идентификатор. Таким образом, новая семантика определяется в терминах более простых, уже известных видов инструкции import. Предыдущее определение вводит идентификаторы io.writeln, io.File, say и CFile.
В начало ⮍ Наверх ⮍
11.1.8. Объявление модуля
Как говорилось в разделе 11.1, по той простой причине, что import принимает лишь идентификаторы, пакеты и модули на D, которые предполагается хоть когда-либо включать в другие модули с помощью этой конструкции, должны иметь имена, являющиеся допустимыми идентификаторами языка D.
В отдельных ситуациях требуется, чтобы модуль замаскировался именем, отличным от имени файла, где расположен код модуля, и притворился бы, что путь до пакета, которому принадлежит модуль, отличается от пути до каталога, где на самом деле располагается упомянутый файл. Очевидная ситуация, когда это может понадобиться: имя модуля не является допустимым идентификатором D.
Предположим, вы пишете программу, которая придерживается более широкого соглашения по именованию, предписывающего использовать дефисы в имени файла, например gnome-cool-app.d. Тогда компилятор D откажется компилировать ее, даже если сама программа будет полностью корректной. И все потому, что во время компиляции D должен генерировать информацию о каждом модуле, каждый модуль должен обладать допустимым именем, а gnome-cool-app не является таковым. Простой способ обойти это правило – хранить исходный код под именем gnome-cool-app, а на этапе сборки переименовывать его, например в gnome_cool_app.d. Этот трюк, конечно, сработает, но есть способ проще и лучше: достаточно вставить в начало файла объявление модуля, которое выглядит так:
module gnome_cool_app;
Если такое объявление присутствует в gnome-cool-app.d (но обязательно в качестве первого объявления в файле), то компилятор будет доволен, поскольку он генерирует всю информацию о модуле, используя имя gnome_cool_app. В таком случае истинное имя вообще никак не проверяется; в объявлении модуля имя может быть хоть таким:
module path.to.nonexistent.location.app;
Тогда компилятор сгенерирует всю информацию о модуле, как будто он называется app.d и расположен в каталоге path/to/nonexistent/location. Компилятору все равно, потому что он не обращается по этому адресу: поиск файлов ассоциируется исключительно с import, а здесь, при непосредственной компиляции gnome-cool-app.d, никаких включений нет.
В начало ⮍ Наверх ⮍
11.1.9. Резюме модулей
Язык D поощряет модель разработки, которая не требует отделения объявлений от сущностей, определяемых программой (в C и C++ эти понятия фигурируют как «заголовки» и «исходные коды»). Вы просто располагаете код в модуле и включаете этот модуль в другие с помощью конструкции import. Тем не менее иногда хочется принять другую модель разработки, предписывающую более жесткое разделение между сигнатурами, которые модуль должен реализовать, и кодом, который стоит за этими сигнатурами. В этом случае потребуется работать с так называемыми резюме модулей (module summaries), построенными на основе исходного кода. Резюме модуля – это минимум того, что необходимо знать модулю о другом модуле, чтобы использовать его.
Резюме модуля – это фактически модуль без комментариев и реализаций функций. Реализации функций, использующих параметры времени компиляции, тем не менее в резюме модуля остаются. Ведь функции с параметрами времени компиляции должны быть доступны во время компиляции, так как могут быть вызваны непредвиденным образом в модуле-клиенте.
Резюме модуля состоит из корректного кода на D. Например:
/**
Это документирующий комментарий для этого модуля
*/
module acme.doitall;
/**
Это документирующий комментарий для класса A
*/
class A
{
void fun() { ... }
final void gun() { ... }
}
class B(T)
{
void hun() { ... }
}
void foo()
{
...
}
void bar(int n)(float x)
{
...
}
При составлении резюме модуля doitall этот модуль копируется, но исключаются все комментарии, а тела всех функций заменяются на ; (исключение составляют функции с параметрами времени компиляции – такие функции остаются нетронутыми):
module acme.doitall;
class A
{
void fun();
final void gun();
}
class B(T)
{
void hun() { ... }
}
void foo();
void bar(int n)(float x)
{
...
}
Резюме содержит информацию, необходимую другому модулю, чтобы использовать acme.doitall. В большинстве случаев резюме модулей автоматически вычисляются внутри работающего компилятора. Но компилятор может сгенерировать резюме по исходному коду и по вашему запросу (в случае эталонной реализации компилятора dmd для этого предназначен флаг -H). Сгенерированные резюме полезны, когда вы, к примеру, хотите распространить библиотеку в виде заголовков плюс скомпилированная библиотека.
Заметим, что исключение тел функций все же не гарантировано. Компилятор волен оставлять тела очень коротких функций в целях инлайнинга. Например, если функция acme.doitall.foo обладает пустым телом или просто вызывает другую функцию, ее тело может присутствовать в сгенерированном интерфейсном файле.
Подход к разработке, хорошо знакомый программистам на C и C++, заключается в сопровождении заголовочных файлов (то есть резюме) и файлов с реализациями вручную и по отдельности. Если вы изберете этот способ, работать придется несколько больше, но зато вы сможете поупражняться в коллективном руководстве. Например, право изменять заголовочные файлы может быть закреплено за командой проектировщиков, контролирующей все детали интерфейсов, которые модули предоставляют друг другу. А команду программистов, реализующих эти интерфейсы, можно наделить правом изменять файлы реализации и правом на чтение (но не изменение) заголовочных файлов, используемых в качестве текущей документации, направляющей процесс реализации. Компилятор проверяет, соответствует ли реализация интерфейсу (ну, по крайней мере синтаксически).
С языком D у вас есть выбор – вы можете: 1) вообще обойтись без резюме модулей, 2) разрешить компилятору сгенерировать их за вас, 3) сопровождать модули и резюме модулей вручную. Все примеры в этой книге выбирают вариант 1) – не использовать резюме модулей, оставив все заботы компилятору. Чтобы опробовать две другие возможности, вам сначала потребуется организовать модули так, чтобы их иерархия соответствовала изображенной на рис. 11.2.
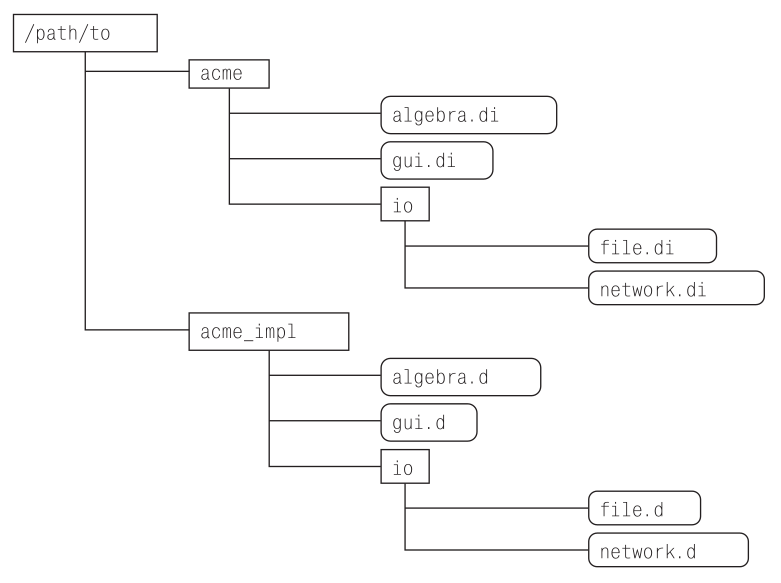
Рис. 11.2. Структура каталога для отделения резюме модулей («заголовков») от файлов реализации
Чтобы использовать пакет acme, потребуется добавить родительский каталог каталогов acme и acme_impl к базовым путям поиска модулей проекта (см. раздел 11.1.2), а затем включить модули из acme в клиентский код с помощью следующих объявлений:
// Из модуля client.d
import acme.algebra;
import acme.io.network;
Каталог acme включает только файлы резюме. Чтобы заставить файлы реализации взаимодействовать, необходимо, чтобы в качестве префикса в именах соответствующих модулей фигурировал пакет acme, а не acme_impl. Вот где приходят на помощь объявления модулей. Даже несмотря на то, что файл algebra.d находится в каталоге acme_impl, включив следующее объявление, модуль algebra может заявить, что входит в пакет acme:
// Из модуля acme_impl/algebra.d
module acme.algebra;
Соответственно модули в подпакете io будут использовать объявление:
// Из модуля acme_impl/io/file.d
module acme.io.file;
Эти строки позволят компилятору сгенерировать должные имена пакетов и модулей. Чтобы во время сборки программы компилятор нашел тела функций, просто передайте ему файлы реализации:
% dmd client.d /path/to/acme_impl/algebra.d
Директива import в client.d обнаружит интерфейсный файл acme.di в каталоге /path/to/acme. А компилятор найдет файл реализации точно там, где указано в командной строке, с корректными именами пакета и модуля.
Если коду из client.d потребуется использовать множество модулей из пакета acme, станет неудобно указывать все эти модули в командной строке компилятора. В таких случаях лучший вариант – упаковать весь код пакета acme в бинарную библиотеку и передавать dmd только ее. Синтаксис для сборки библиотеки зависит от реализации компилятора; если вы работаете с эталонной реализацией, вам потребуется сделать что-то типа этого:
% cd /path/to/acme_impl
% dmd -lib -ofacme algebra.d gui.d io/file.d io/network.d
Флаг -lib предписывает компилятору собрать библиотеку, а флаг -of (от output file – файл вывода) направляет вывод в файл acme.lib (Windows) или acme.a (UNIX-подобные системы). Чтобы клиентский код мог работать с такой библиотекой, нужно ввести что-то вроде:
% dmd client.d acme.lib
Если библиотека acme широко используется, ее можно сделать одной из библиотек, которые проект использует по умолчанию. Но тут уже многое зависит от реализации компилятора и от операционной системы, так что для успеха операции придется прочесть это жуткое руководство.
В начало ⮍ Наверх ⮍
11.2. Безопасность
Понятие безопасности языков программирования всегда было противоречивым, но за последние годы его определение удивительно кристаллизовалось.
Интуитивно понятно, что безопасный язык тот, который «защищает свои собственные абстракции» [46, гл. 1]. В качестве примера таких абстракций D приведем класс:
class A { int x; }
и массив:
float[] array;
По правилам языка D (тоже «абстракция», предоставляемая языком) изменение внутреннего элемента x любого объекта типа A не должно изменять какой-либо элемент массива array, и наоборот, изменение array[n] для некоторого n не должно изменять элемент x некоторого объекта типа A. Как ни благоразумно запрещать такие бессмысленные операции, в D есть способы заставить их обе выполниться – формируя указатели с помощью cast или задействуя union.
void main()
{
float[] array = new float[1024];
auto obj = cast(A) array.ptr;
...
}
Изменение одного из элементов массива array (какого именно, зависит от реализации компилятора, но обычно второго или третьего) изменяет obj.x.
В начало ⮍ Наверх ⮍
11.2.1. Определенное и неопределенное поведение
Кроме только что приведенного примера с сомнительным приведением указателя на float к ссылке на класс есть и другие ошибки времени исполнения, свидетельствующие о том, что язык нарушил определенные обещания. Хорошими примерами могут послужить разыменование указателя null, деление на ноль, а также извлечение вещественного квадратного корня из отрицательного числа. Никакая корректная программа не должна когда-либо выполнять такие операции, и тот факт, что они все же могут иметь место в программе, типы которой проверяются, можно рассматривать как несостоятельность системы типов.
Проблема подобного критерия корректности, который «хорошо было бы принять»: список ошибок бесконечно пополняется. D сводит свое понятие безопасности к очень точному и полезному определению: безопасная программа на D характеризуется только определенным поведением. Различия между определенным и неопределенным поведением:
- определенное поведение: выполнение фрагмента программы в заданном состоянии завершается одним из заранее определенных исходов; один из возможных исходов – резкое прекращение выполнения (именно это происходит при разыменовании указателя
nullи при делении на ноль); - неопределенное поведение: эффект от выполнения фрагмента программы в заданном состоянии не определен. Это означает, что может произойти все, что угодно в пределах физических возможностей. Хороший пример – только что упомянутый случай с
cast: программа с такой «раковой клеткой» некоторое время может продолжать работу, но наступит момент, когда какая-нибудь запись в array с последующим случайным обращением кobjприведет к тому, что исполнение выйдет из-под контроля.
(Неопределенное поведение перекликается с понятием недиагностиро ванных ошибок, введенным Карделли. Он выделяет две большие категории ошибок времени исполнения: диагностированные и недиагностированные ошибки. Диагностированные ошибки вызывают немедленный останов исполнения, а недиагностированные – выполнение произвольных команд. В программе с определенным поведением никогда не возникнет недиагностированная ошибка.)
У противопоставления определенного поведения неопределенному есть пара интересных нюансов. Рассмотрим, к примеру, язык, определяющий операцию деления на ноль с аргументами типа int, так что она должна всегда порождать значение int.max. Такое условие переводит деление на ноль в разряд определенного поведения – хотя данное определение этого действия и нельзя назвать полезным. Примерно в том же ключе std.math в действительности определяет, что операция sqrt(-1) должна возвращать double.nan. Это также определенное поведение, поскольку double.nan – вполне определенное значение, которое является частью спецификации языка, а также функции sqrt. Даже деление на ноль – не ошибка для типов с плавающей запятой: этой операции заботливо предписывается возвращать или плюс бесконечность, или минус бесконечность, или NaN («нечисло») (см. главу 2). Результаты выполнения программ всегда будут предсказуемыми, когда речь идет о функции sqrt или делении чисел с плавающей запятой.
Программа безопасна, если она не порождает неопределенное поведение.
В начало ⮍ Наверх ⮍
11.3.2. Атрибуты @safe, @trusted и @system
Нехитрый способ гарантировать отсутствие недиагностированных ошибок – просто запретить все небезопасные конструкции D, например особые случаи применения выражения cast. Однако это означало бы невозможность реализовать на D многие системы. Иногда бывает очень нужно переступить границы абстракции, например, рассматривать область памяти, имеющей некоторый тип, как область памяти с другим типом. Именно так поступают менеджер памяти и сборщик мусора. В задачи языка D всегда входила способность выразить логику такого программного обеспечения на системном уровне.
С другой стороны, многие приложения нуждаются в небезопасном доступе к памяти лишь в сильно инкапсулированной форме. Язык может заявить о том, что он безопасен, даже если его сборщик мусора реализован на небезопасном языке. Ведь с точки зрения безопасного языка нет возможности использовать сборщик небезопасным образом. Сборщик сам по себе инкапсулирован внутри библиотеки поддержки времени исполнения, реализован на другом языке и воспринимается безопасным языком как волшебный примитив. Любой недостаток безопасности сборщика мусора был бы проблемой реализации языка, а не клиентского кода.
Как может большой проект обеспечить безопасность большинства своих модулей, в то же время обходя правила в некоторых избранных случаях? Подход D к безопасности – предоставить пользователю право самому решать, чего он хочет: вы можете на уровне объявлений заявить, придерживается ли ваш код правил безопасности или ему нужна возможность переступить ее границы. Обычно информация о свойствах модуля указывается сразу же после объявления модуля, как здесь:
module my_widget;
@safe:
...
В этом месте определяются атрибуты @safe, @trusted и @system, которые позволяют модулю объявить о своем уровне безопасности. (Такой подход не нов; в языке Модула-3 применяется тот же подход, чтобы отличить небезопасные и безопасные модули.)
Код, размещенный после атрибута @safe, обязуется использовать ин
струкции лишь из безопасного подмножества D, что означает:
- никаких преобразований указателей в неуказатели (например,
int), и наоборот; - никаких преобразований между указателями, типы которых не имеют отношения друг к другу;
- проверка границ при любом обращении к массиву;
- никаких объединений, включающих указатели, классы и массивы, а также структуры, которые содержат перечисленные запрещенные типы в качестве внутренних элементов;
- никаких арифметических операций с указателями;
- запрет на получение адреса локальной переменной (на самом деле, требуется запрет утечки таких адресов, но отследить это гораздо сложнее);
- функции должны вызывать лишь функции, обладающие атрибутом
@safeили@trusted; - никаких ассемблерных вставок;
- никаких преобразований типа, лишающих данные статуса
const,immutableилиshared; - никаких обращений к каким-либо сущностям с атрибутом
@system.
Иногда эти правила могут оказаться излишне строгими; например, в стремлении избежать утечки указателей на локальные переменные можно исключить из рядов безопасных программ очевидно корректные программы. Тем не менее безопасное подмножество D (по прозвищу SafeD) все же довольно мощное – целые приложения могут быть полностью написаны на SafeD.
Объявление или группа объявлений могут заявить, что им, напротив, требуется низкоуровневый доступ. Такие объявления должны содержать атрибут @system:
@system:
void * allocate(size_t size);
void deallocate(void* p);
...
Атрибут @system действенно отключает все проверки, позволяя использовать необузданную мощь языка – на счастье или на беду.
Наконец, подход библиотек нередко состоит в том, что они предлагают клиентам безопасные абстракции, подспудно используя небезопасные средства. Такой подход применяют многие компоненты стандартной библиотеки D. В таких объявлениях можно указывать атрибут @trusted.
Модулям без какого-либо атрибута доступен уровень безопасности, назначаемый по умолчанию. Выбор уровня по умолчанию можно настроить с помощью конфигурационных файлов компилятора и флагов командной строки; точная настройка зависит от реализации компилятора. Эталонная реализация компилятора dmd предлагает атрибут по умолчанию @system; задать атрибут по умолчанию @safe можно с помощью флага командной строки -safe.
В момент написания этой книги SafeD находится в состоянии α-версии, так что порой небезопасные программы проходят компиляцию, а безопасные – нет, но мы активно работаем над решением этой проблемы.
В начало ⮍ Наверх ⮍
11.3. Конструкторы и деструкторы модулей
Иногда модулям требуется выполнить какой-то инициализирующий код для вычисления некоторых статических данных. Сделать это можно, вставляя явные проверки («Были ли эти данные добавлены?») везде, где осуществляется доступ к соответствующим данным. Если такой подход неудобен/неэффективен, помогут конструкторы модулей.
Предположим, что вы пишете модуль, зависящий от операционной системы, и поведение этого модуля зависит от флага. Во время компиляции легко распознать основные платформы (например, «Я Mac» или «Я PC»), но определять версию Windows придется во время исполнения.
Чтобы немного упростить задачу, условимся, что наш код различает лишь ОС Windows Vista и более поздние или ранние версии относительно нее. Пример кода, определяющего вид операционной системы на этапе инициализации модуля:
private enum WinVersion { preVista, vista, postVista }
private WinVersion winVersion;
static this()
{
OSVERSIONINFOEX info;
info.dwOSVersionInfoSize = OSVERSIONINFOEX.sizeof;
GetVersionEx(&info) || assert(false);
if (info.dwMajorVersion < 6)
{
winVersion = WinVersion.preVista;
}
else if (info.dwMajorVersion == 6 && info.dwMinorVersion == 0)
{
winVersion = WinVersion.vista;
}
else
{
winVersion = WinVersion.postVista;
}
}
Этот геройский подвиг совершает конструктор модуля static this(). Такие конструкторы модулей всегда выполняются до main. Любой заданный модуль может содержать любое количество конструкторов.
В свою очередь, синтаксис деструкторов модулей предсказуем:
// На уровне модуля
static ~this()
{
...
}
Статические деструкторы выполняются после того, как выполнение main завершится каким угодно образом, будь то нормальный возврат или порождение исключения. Модули могут определять любое количество деструкторов модуля и свободно чередовать конструкторы и деструкторы модуля.
В начало ⮍ Наверх ⮍
11.3.1. Порядок выполнения в рамках модуля
Порядок выполнения конструкторов модуля в рамках заданного модуля всегда соответствует последовательности расположения этих конструкторов в модуле, то есть сверху вниз (лексический порядок). Порядок выполнения деструкторов модуля – снизу вверх (обратный лексический порядок).
Если один из конструкторов модуля не сможет выполниться и породит исключение, то не будет выполнена и функция main. Выполняются лишь статические деструкторы, лексически расположенные выше отказавшего конструктора модуля. Если не сможет выполниться и породит исключение какой-либо деструктор модуля, остальные деструкторы выполнены не будут, а приложение прекратит свое выполнение, выведя сообщение об ошибке в стандартный поток.
В начало ⮍ Наверх ⮍
11.3.2. Порядок выполнения при участии нескольких модулей
Если модулей несколько, определить порядок вызовов сложнее. Эти правила идентичны определенным для статических конструкторов классов (см. раздел 6.3.6) и исходят из того, что модули, включаемые другими модулями, должны инициализироваться первыми, а очищаться – последними. Вот правила, определяющие порядок выполнения статических конструкторов модулей модуль1 и модуль2:
- конструкторы или деструкторы модулей определяются только в одном из модулей
модуль1имодуль2, тогда не нужно заботиться об упорядочивании; модуль1не включает модульмодуль2, амодуль2не включаетмодуль1: упорядочивание не регламентируется – любой порядок сработает, поскольку модули не зависят друг от друга;модуль1включаетмодуль2: конструкторымодуля2выполняются до конструкторовмодуля1, а деструкторымодуля2– после деструкторовмодуля1;модуль2включаетмодуль1: конструкторымодуля1выполняются до конструкторовмодуля2, а деструкторымодуля1– после деструкторовмодуля2;модуль1включаетмодуль2, амодуль2вкючаетмодуль1: диагностируется ошибка «циклическая зависимость» и выполнение прерывается на этапе загрузки программы.
Проверка на циклическую зависимость модулей в настоящий момент делается во время исполнения. Такие циклы можно отследить и во время компиляции или сборки, но это мало что дает: проблема проявляется в том, что программа отказывается загружаться, и можно предположить, что перед публикацией программа запускается хотя бы один раз. Тем не менее чем раньше обнаружена проблема, тем лучше, так что язык оставляет реализации возможность выявить это некорректное состояние и сообщить о нем.
В начало ⮍ Наверх ⮍
11.4. Документирующие комментарии
Писать документацию скучно, а для программиста нет ничего страшнее скуки. В результате документация обычно содержит скупые, неполные и устаревшие сведения.
Автоматизированные построители документации стараются вывести максимум информации из чистого кода, отразив заслуживающие внимания отношения между сущностями. Тем не менее современным автоматизированным построителям нелегко задокументировать высокоуровневые намерения по реализации. Современные языки помогают им в этом, предписывая использовать так называемые документирующие комментарии – особые комментарии, описывающие, например, определенную пользователем сущность. Языковой процессор (или сам компилятор, или отдельная программа) просматривает комментарии вместе с кодом и генерирует документацию в одном из популярных форматов (таком как XML, HTML или PDF).
D определяет для документирующих комментариев спецификацию, описывающую формат комментариев и процесс их преобразования в целевой формат. Сам процесс не зависит от целевого формата; транслятор, управляемый простым и гибким шаблоном (также определяемым пользователем), генерирует документацию фактически в любом заданном формате.
Всеобъемлющее изучение системы трансляции документирующих комментариев не входит в задачу этой книги. Замечу только, что вам не помешает уделить этому больше внимания; документация многих проектов на D, а также веб-сайт эталонной реализации компилятора и его стандартной библиотеки полностью сгенерированы на основе документирующих комментариев D.
В начало ⮍ Наверх ⮍
11.5. Взаимодействие с C и C++
Модули на D могут напрямую взаимодействовать с функциями C и C++. Есть ограничение: к этим функциям не относятся обобщенные функции С++, поскольку для этого компилятор D должен был бы включать полноценный компилятор C++. Кроме того, схема расположения полей класса D не совместима с классами C++, использующими виртуальное наследование.
Чтобы вызвать функцию C или C++, просто укажите в объявлении функции язык и не забудьте связать ваш модуль с соответствующими библиотеками:
extern(C) int foo(char*);
extern(C++) double bar(double);
Эти объявления сигнализируют компилятору, что вызов генерируется с соответствующими схемой расположения в стеке, соглашением о вызовах и кодировкой имен (также называемой декорированием имен – name mangling), даже если сами функции D отличаются по всем или некоторым из этих пунктов.
Чтобы вызвать функцию на D из программы на C или C++, просто добавьте в реализацию одно из приведенных выше объявлений:
extern(C) int foo(char*)
{
... // Реализация
}
extern(C++) double bar(double)
{
... // Реализация
}
Компилятор опять организует необходимое декорирование имен и использует соглашение о вызовах, подходящее для языка-клиента. То есть эту функцию можно с одинаковым успехом вызывать из модулей как на D, так и на «иностранных языках».
В начало ⮍ Наверх ⮍
11.5.1. Взаимодействие с классами C++6
Как уже говорилось, D не способен отобразить классы C++ в классы D. Это связано с различием реализаций механизма наследования в этих языках. Тем не менее интерфейсы D очень похожи на классы C++, поэтому D реализует следующий механизм взаимодействия с классами C++:
// Код на С++
class Foo
{
public:
virtual int method(int a, int b)
{
return a + b;
}
};
Foo* newFoo()
{
return new Foo();
}
void deleteFoo(Foo* obj)
{
delete obj;
}
// Код на D
extern (C++)
{
interface Foo
{
int method(int, int);
}
Foo newFoo();
void deleteFoo(Foo);
}
void main()
{
auto obj = newFoo;
scope(exit) deleteFoo(obj);
assert(obj.method(2, 3) == 5);
}
Следующий код создает класс, реализующий интерфейс С++, и использует объект этого интерфейса в вызове внешней функции С++, принимающей в качестве аргумента указатель на объект класса С++ Foo.
extern (C++) void call(Foo);
// В коде C++ эта функция должна быть определена как void call(Foo* f);
extern (C++) interface Foo
{
int bar(int, int);
}
class FooImpl : Foo
{
extern (C++) int bar(int a, int b)
{
// ...
}
}
void main()
{
FooImpl f = new FooImpl();
call(f);
}
В начало ⮍ Наверх ⮍
11.6. Ключевое слово deprecated
Перед любым объявлением (типа, функции или данных) может располагаться ключевое слово deprecated. Оно действует как класс памяти, но нисколько не влияет собственно на генерацию кода. Вместо этого deprecated лишь информирует компилятор о том, что помеченная им сущность не предназначена для использования. Если такая сущность все же будет использована, компилятор выведет предупреждение или даже откажется компилировать, если он был запущен с соответствующим флагом (-w в случае dmd).
Ключевое слово deprecated служит для планомерной постепенной миграции от старых версий API к более новым версиям. Причисляя соответствующие объявления к устаревшим, можно настроить компилятор так, чтобы он или принимал, или отклонял объявления с префиксом deprecated. Подготовив очередное изменение, отключите компиляцию deprecated – ошибки точно укажут, где требуется ваше вмешательство, что позволит вам шаг за шагом обновить код.
В начало ⮍ Наверх ⮍
11.7. Объявления версий
В идеальном мире, как только программа написана, ее можно запускать где угодно. А здесь, на Земле, то и дело что-то заставляет вносить в программу изменения – другая версия библиотеки, сборка для особых целей или зависимость от платформы. Чтобы помочь справиться с этим, D определяет объявление версии version, позволяющее компилировать код в зависимости от определенных условий.
Способ использования версии намеренно прост и прямолинеен. Вы или устанавливаете версию, или проверяете ее. Сама версия может быть или целочисленной константой, или идентификатором:
version = 20100501;
version = FinalRelease;
Чтобы проверить версию, напишите:
version(20100501)
{
... // Объявления
}
version (PreFinalRelease)
{
... // Объявления
}
else version (FinalRelease)
{
... // Другие объявления
}
else
{
... // Еще объявления
}
Если версия уже присвоена, «охраняемые» проверкой объявления компилируются, иначе они игнорируются. Конструкция version может включать блок else, назначение которого очевидно.
Установить версию можно лишь до того, как она будет прочитана. Попытки установить версию после того, как она была задействована в проверке, вызывают ошибку времени компиляции:
version (ProEdition)
{
... // Объявления
}
version = ProEdition; // Ошибка!
Реакция такова, поскольку присваивания версий не предназначены для того, чтобы версии изменять: версия должна быть одной и той же независимо от того, на какой фрагмент программы вы смотрите.
Указывать версию можно не только в файлах с исходным кодом, но и в командной строке компилятора (например, -version=123 или -version=xyz в случае эталонной реализации компилятора dmd). Попытка установить версию как в командной строке, так и в файле с исходным кодом также приведет к ошибке.
Простота семантики version не случайна. Было бы легко сделать конструкцию version более мощной во многих отношениях, но очень скоро она начала бы работать наперекор своему предназначению. Например, управление версиями C с помощью связки директив #if/#elif/#else, безусловно, позволяет реализовать больше тактик в определении версий – именно поэтому управление версиями в проекте на C обычно содержит змеиный клубок условий, направляющих компиляцию. Конструкция version языка D намеренно ограничена, чтобы с ее помощью можно было реализовать лишь простое, единообразное управление версиями.
Компиляторы, как водится, имеют множество предопределенных версий, таких как платформа (например, Win32, Posix или Mac), порядок байтов (LittleEndian, BigEndian) и так далее. Если включено тестирование модулей, автоматически задается проверка version(unittest). Особыми идентификаторами времени исполнения __FILE__ и __LINE__ обозначаются соответственно имя текущего файла и строка в этом файле. Полный список определений version приведен в документации вашего компилятора.
В начало ⮍ Наверх ⮍
11.8. Отладочные объявления
Отладочное объявление – это лишь особая версия с идентичным синтаксисом присваивания и проверки. Конструкция debug была определена специально для того, чтобы стандартизировать порядок объявления отладочных режимов и средств.
Типичный случай использования конструкции debug:
module mymodule;
...
void fun()
{
int x;
...
debug(mymodule) writeln("x=", x);
...
}
Чтобы отладить модуль mymodule, укажите в командной строке при компиляции этого модуля флаг -debug=mymodule, и выражение debug(mymodule) вернет true, что позволит скомпилировать код, «охраняемый» соответствующей конструкцией debug. Если использовать debug(5), то «охраняемый» этой конструкцией код будет включен при уровне отладки >= 5. Уровень отладки устанавливается либо присваиванием debug целочисленной константы, либо флагом компиляции. Допустимо также использовать конструкцию debug без аргументов. Код, следующий за такой конструкцией, будет добавлен, если компиляция запущена с флагом -debug. Как и в случае version, нельзя присваивать отладочной версии идентификатор после того, как он уже был проверен.
В начало ⮍ Наверх ⮍
11.9. Стандартная библиотека D
Стандартная библиотека D, фигурирующая в коде под именем Phobos7, органично развивалась вместе с языком. В результате она включает как API старого стиля, так и новейшие библиотечные артефакты, использующие более современные средства языка.
Библиотека состоит из двух основных пакетов – core и std. Первый содержит фундаментальные средства поддержки времени исполнения: реализации встроенных типов, сборщик мусора, код для начала и завершения работы, поддержка многопоточности, определения, необходимые для доступа к библиотеке времени исполнения языка C, и другие компоненты, связанные с перечисленными. Пакет std предоставляет функциональность более высокого уровня. Преимущество такого подхода в том, что другие библиотеки можно надстраивать поверх core, а с пакетом std они будут лишь сосуществовать, не требуя его присутствия.
Пакет std обладает плоской структурой: большинство модулей располагаются в корне пакета. Каждый модуль посвящен отдельной функциональной области. Информация о некоторых наиболее важных модулях библиотеки Phobos представлена в табл. 11.2.
Таблица 11.2. Обзор стандартных модулей
| Модуль | Описание |
|---|---|
std.algorithm |
Этот модуль можно считать основой мощнейшей способности к обобщению, присущей языку. Вдохновлен стандартной библиотекой шаблонов C++ (Standard Template Library, STL). Содержит больше 70 важных алгоритмов, реализованных очень обобщенно. Большинство алгоритмов применяются к структурированным последовательностям идентичных элементов. В STL базовой абстракцией последовательности служит итератор, соответствующий примитив D – диапазон, для которого краткого обзора явно недостаточно; полное введение в диапазоны D доступно в Интернете |
std.array |
Функции для удобства работы с массивами |
std.bigint |
Целое число переменной длины с сильно оптимизированной реализацией |
std.bitmanip |
Типы и часто используемые функции для низкоуровневых битовых операций |
std.concurrency |
Средства параллельных вычислений (см. главу 13) |
std.container |
Реализации разнообразных контейнеров |
std.conv |
Универсальный магазин, удовлетворяющий любые нужды по преобразованиям. Здесь определены многие полезные функции, такие как to и text |
std.datetime |
Полезные вещи, связанные с датой и временем |
std.file |
Файловые утилиты. Зачастую этот модуль манип улирует файлами целиком; например, в нем есть функция read, которая считывает весь файл, при этом std.file.read и понятия не имеет о том, что можно открывать файл и читать его маленькими порциями (об этом заботится модуль std.stdio, см. далее) |
std.functional |
Примитивы для определения и композиции функций |
std.getopt |
Синтаксический анализ командной строки |
std.json |
Обработка данных в формате JSON |
std.math |
В высшей степени оптимизированные, часто используемые математические функции |
std.numeric |
Общие числовые алгоритмы |
std.path |
Утилиты для манипуляций с путями к файлам |
std.random |
Разнообразные генераторы случайных чисел |
std.range |
Определения и примитивы классификации, имеющие отношение к диапазонам |
std.regex |
Обработчик регулярных выражений |
std.stdio |
Стандартные библиотечные средства ввода/вывода, построенные на основе библиотеки stdio языка C. Входные и выходные файлы предоставляют интерфейсы в стиле диапазонов, благодаря чему многие алгоритмы, определенные в модуле std.algorithm, могут работать непосредственно с файлами |
std.string |
Функции, специфичные для строк. Строки тесно связаны с std.algorithm, так что модуль std.string, относительно небольшой по размеру, в основном лишь ссылается (определяя псевдонимы) на части std.algorithm, применимые к строкам |
std.traits |
Качества типов и интроспекция |
std.typecons |
Средства для определения новых типов, таких как Tuple |
std.utf |
Функции для манипулирования кодировками UTF |
std.variant |
Объявление типа Variant, который является контейнером для хранения значения любого типа. Variant – это высокоуровневый union |
В начало ⮍ Наверх ⮍
11.10. Встроенный ассемблер8
Строго говоря, большую часть задач можно решить, не обращаясь к столь низкоуровневому средству, как встроенный ассемблер, а те немногие задачи, которым без этого не обойтись, можно написать и скомпилировать отдельно, после чего скомпоновать с вашей программой на D обычным способом. Тем не менее встроенный в D ассемблер – очень мощное средство повышения эффективности кода, и упомянуть его необходимо. Конечно, в рамках одной главы невозможно всеобъемлюще описать язык ассемблера, да это и не нужно – ассемблеру для популярных платформ посвящено множество книг9. Поэтому здесь мы приводим синтаксис и особенности применения встроенного ассемблера D, а описание используемых инструкций оставим специализированным изданиям.
К моменту написания данной книги компиляторы языка D существовали для платформ x86 и x86-64, соответственно синтаксис встроенного ассемблера определен пока только для этих платформ.
В начало ⮍ Наверх ⮍
11.10.1. Архитектура x86
Инструкции ассемблера можно встроить в код, разместив их внутри конструкции asm:
asm
{
naked;
mov ECX, EAX;
mov EAX, [ESP+size_t.sizeof*1];
mov EBX, [ESP+size_t.sizeof*2];
L1:
mov DH, [EBX + ECX - 1];
mov [EAX + ECX - 1], DH;
loop L1;
ret;
}
Внутри конструкции asm допустимы следующие сущности:
- инструкция ассемблера:
‹инструкция› ‹арг1›, ‹арг2›, ..., ‹аргn›;
- метка:
‹метка›:
- псевдоинструкция:
‹псевдоинструкция› ‹арг1›, ‹арг2›, ..., ‹аргn›;
- комментарии.
Каждая инструкция пишется в нижнем регистре. После инструкции через запятую указываются аргументы. Инструкция обязательно завершается точкой с запятой. Несколько инструкций могут располагаться в одной строке. Метка объявляется перед соответствующей инструкцией как идентификатор метки с последующим двоеточием. Переход к метке может осуществляться с помощью оператора goto вне блока asm, а также с помощью инструкций семейства jmp и call. Аналогично внутри блока asm разрешается использовать метки, объявленные вне блоков asm. Комментарии в код на ассемблере вносятся так же, как и в остальном коде на D, другой синтаксис комментариев недопустим. Аргументом инструкции может быть идентификатор, объявленный вне блока asm, имя регистра, адрес (с применением обычных правил адресации данной платформы) или литерал соответствующего типа. Адреса можно записывать так (все эти адреса указывают на одно и то же значение):
mov EDX, 5[EAX][EBX];
mov EDX, [EAX+5][EBX];
mov EDX, [EAX+5+EBX];
Также разрешается использовать любые константы, известные на этапе компиляции, и идентификаторы, объявленные до блока asm:
int* p = arr.ptr;
asm
{
mov EAX, p[EBP]; // Помещает в EAX значение p.
mov EAX, p; // То же самое.
mov EAX, [p + 2*int.sizeof]; // Помещает в EAX второй элемент целочисленного массива.
}
Если размер операнда неочевиден, используется префикс ‹тип› ptr:
add [EAX], 3; // Размер операнда 3 неочевиден.
add [EAX], int ptr 3; // Теперь все ясно.
Префикс ptr можно использовать в сочетании с типами near, far, byte, short, int, word, dword, qword, float, double и real. Префикс far ptr не используется в плоской модели памяти D. По умолчанию компилятор использует byte ptr. Префикс seg возвращает номер сегмента адреса:
mov EAX seg p[EBP];
Этот префикс также не используется в плоской модели кода.
Также внутри блока asm доступны символы: $, указывающий на адрес следующей инструкции, и __LOCAL_SIZE, означающий количество байт в локальном кадре стека.
Для доступа к полю структуры, класса или объединения следует поместить адрес объекта в регистр и использовать полное имя поля в сочетании с offsetof:
struct Regs
{
uint eax, ebx, ecx, edx;
}
void pushRegs(Regs* p)
{
asm
{
push EAX;
mov EAX, p;
// Помещаем в p.ebx значение EBX
mov [EAX+Regs.ebx.offsetof], EBX;
// Помещаем в p.ecx значение ECX
mov [EAX+Regs.ecx.offsetof], ECX;
// Помещаем в p.edx значение EDX
mov [EAX+Regs.edx.offsetof], EDX;
pop EBX;
// Помещаем в p.eax значение EAX
mov [EAX+Regs.eax.offsetof], EBX;
}
}
Ассемблер x86 допускает обращение к следующим регистрам (имена регистров следует указывать заглавными буквами):
AL AH AX EAX BP EBPES CS SS DS GS FS
BL BH BX EBX SP ESPCR0 CR2 CR3 CR4
CL CH CX ECX DI EDIDR0 DR1 DR2 DR3 DR6 DR7
DL DH DX EDX SI ESITR3 TR4 TR5 TR6 TR7
ST
ST(0) ST(1) ST(2) ST(3) ST(4) ST(5) ST(6) ST(7)
MM0 MM1 MM2 MM3 MM4 MM5 MM6 MM7
XMM0 XMM1 XMM2 XMM3 XMM4 XMM5 XMM6 XMM7
Ассемблер D вводит следующие псевдоинструкции:
- align
‹целочисленное_выражение›;
целочисленное_выражение должно вычисляться на этапе компиляции. align выравнивает следующую инструкцию по адресу, кратному целочисленному_выражению, вставляя перед этой инструкцией нужное количество инструкций nop (от Not OPeration), имеющих код 0x90.
- even;
Псевдоинструкция even выравнивает следующую инструкцию почетному адресу (аналогична align 2). Выравнивание может сильно повлиять на производительность в циклах, где часто выполняется переход по выравниваемому адресу.
- naked;
Псевдоинструкция naked указывает компилятору не генерировать пролог и эпилог функции. В прологе, как правило, создается новый кадр стека, а в эпилоге размещается код возвращения значения. Используя naked, программист должен сам позаботиться о получении нужных аргументов и возвращении результирующего значения в соответствии с применяемым функцией соглашением о вызовах.
Также ассемблер D разрешает вставлять в код непосредственные значения с помощью псевдоинструкций db, ds, di, dl, df, dd, de, которые соответствуют типам byte, short, int, long, float, double и extended и соответственно размещают значения этого типа (extended – тип с плавающей запятой длиной 10 байт, известный в D как real). Каждая такая псевдоинструкция может иметь насколько аргументов. Строковый литерал в качестве аргумента эквивалентен указанию n аргументов, где n – длина строки, а каждый аргумент соответствует одному знаку строки.
Следующий пример делает то же самое, что и первый пример в этом разделе:
asm
{
naked;
db 0x89, 0xc1, 0x8b, 0x44, 0x24, 0x04, 0x8b;
db 0x5c, 0x24, 0x08, 0x8a, 0x74, 0x0b, 0xff;
db 0x88, 0x74, 0x08, 0xff, 0xe2, 0xf6, 0xc3; // Коротко и ясно.
}
Префиксы инструкций, такие как lock, rep, repe, repne, repnz и repz, указываются как отдельные псевдоинструкции:
asm
{
rep;
movsb;
}
Ассемблер D не поддерживает инструкцию pause. Вместо этого следует писать:
rep;
nop;
Для операций с плавающей запятой следует использовать формат с двумя аргументами.
fdiv ST(1); // Неправильно
fmul ST; // Неправильно
fdiv ST,ST(1); // Правильно
fmul ST,ST(0); // Правильно
В начало ⮍ Наверх ⮍
11.10.2. Архитектура x86-64
Архитектура x86-64 является дальнейшим развитием архитектуры х86 и в большинстве случаев сохраняет обратную совместимость с ней. Рассмотрим отличия архитектуры x86-64 от x86.
Регистры общего назначения в x86-64 расширены до 64 бит. Их имена: RAX, RBX, RCX, RDX, RBP, RSI, RDI, RSP, RIP и RFLAGS, причем RIP теперь доступен из ассемблерного кода. Вдобавок добавились восемь 64-разрядных регистров общего назначения R8, R9, R10, R11, R12, R13, R14, R15. Для доступа к младшим 32 битам такого регистра к названию добавляется суффикс D, к младшим 16 – W, к младшим 8 – B. Так, R8D – младшие 4 байта регистра R8, а R15B – младший байт R15. Также добавились восемь XMM-регистров XMM8–XMM15. Рассмотрим регистр RIP подробнее. Регистр RIP всегда содержит указатель на следующую инструкцию. Если в архитектуре х86, чтобы получить адрес следующей инструкции, приходилось писать код вида:
asm
{
call $; // Поместить в стек адрес следующей инструкции и передать на нее управление.
pop EBX; // Вытолкнуть адрес возврата в EBX.
add EBX, 6; // Скорректировать адрес на размер инструкций pop, add и mov.
mov AL, [EBX]; // Теперь AL содержит код инструкции nop;
nop;
}
то в x86-64 можно просто написать10:
asm
{
mov AL, [RIP]; // Загружаем код следующей инструкции.
nop;
}
К сожалению, выполнить переход по содержащемуся в RIP адресу с помощью jmp/jxx или call нельзя, равно как нельзя получить значение RIP, скопировав его в регистр общего назначения или стек. Впрочем, call $; как раз помещает в стек адрес следующей инструкции, что, по сути, идентично push RIP; (если бы такая инструкция была допустима). Подробную информацию можно найти в официальном руководстве по конкретному процессору.
В начало ⮍ Наверх ⮍
11.10.3. Разделение на версии
По своей природе ассемблерный код является платформозависимым. Для х86 нужен один код, для x86-64 – другой, для SPARC – третий, а компилятор для виртуальной машины вообще может не иметь встроенного ассемблера. Хорошая практика – реализовать требуемую функциональность без использования ассемблера, добавив альтернативные реализации, оптимизированные для конкретных архитектур. Здесь пригодится механизм версий.
Компилятор dmd определяет версию D_InlineAsm_X86, если доступен ассемблер х86, и D_InlineAsm_X86_64 если доступен ассемблер x86-64.
Вот пример такого кода:
void optimizedFunction(void* arg)
{
version(D_InlineAsm_X86)
{
asm
{
naked;
mov EBX, [EAX];
}
}
else
version(D_InlineAsm_X86_64)
{
asm
{
naked;
mov RBX, [RAX];
}
}
else
{
size_t s = *cast(size_t*)arg;
}
}
В начало ⮍ Наверх ⮍
11.10.4. Соглашения о вызовах
Все современные парадигмы программирования основаны на процедурной модели. Каким бы ни был ваш код – функциональным, объектно-ориентированным, агентно-ориентированным, многопоточным, распределенным, – он все равно будет вызывать процедуры. Разумеется, с повышением уровня абстракции, добавлением новых концепций процесс вызова процедур неизбежно усложняется.
Процедурный подход выгоден при организации взаимодействия фрагментов программы, написанных на разных языках. Во-первых, разные языки поддерживают разные парадигмы программирования, а во-вторых, даже одни и те же парадигмы могут быть реализованы по-разному. Между тем процедурный подход является тем самым фундаментом, на котором основано все остальное. Этот фундамент надежен, стандартизирован и проверен временем.
Вызов процедуры, как правило, состоит из следующих операций:
- передача аргументов;
- сохранение адреса возврата;
- переход по адресу процедуры;
- выполнение процедуры;
- передача возвращаемого значения;
- переход по сохраненному адресу возврата.
В высокоуровневом коде знать порядок выполнения этих операций необязательно, однако при написании кода на ассемблере их придется реализовывать самостоятельно.
То, как именно выполняются эти действия, определяется соглашениями о вызовах процедур. Их относительно немного, они хорошо стандартизированы. Разные языки используют разные соглашения о вызовах, но, как правило, допускают возможность использовать несколько соглашений. Соглашения о вызовах определяют, как передаются аргументы (через стек, через регистры, через общую память), порядок передачи аргументов, значение каких регистров следует сохранять, как передавать возвращаемое значение, кто возвращает указатель стека на исходную позицию (вызывающая или вызываемая процедура). В следующих разделах перечислены основные из этих соглашений.
В начало ⮍ Наверх ⮍
11.10.4.1. Соглашения о вызовах архитектуры x86
Архитектура x86 за долгие годы своего существования породила множество соглашений о вызовах процедур. У каждого из них есть свои преимущества и недостатки. Все они требуют восстановления значений сегментных регистров.
cdecl
Данное соглашение принято в языке C, отсюда и его название (C Declaration). Большинство языков программирования допускают использование этого соглашения, и с его помощью наиболее часто организуется взаимодействие подпрограмм, написанных на разных языках. В языке D оно объявляется как функция с атрибутом extern(C). Аргументы передаются через стек в обратном порядке, то есть начиная с последнего. Последним в стек помещается адрес возврата. Значение возвращается в регистре EAX, если по размеру оно меньше 4 байт, и на вершине стека, если его размер превышает 4 байта. В этом случае значение в EAX указывает на него. Если вы используете псевдоинструкцию naked, вам придется обрабатывать переданные аргументы вручную.
extern(C) int increment(int a) {
asm
{
naked;
mov EAX, [ESP+4]; // Помещаем в EAX значение a, смещенное на размер указателя (адреса возврата) от вершины стека.
inc EAX; // Инкрементируем EAX
ret; // Передаем управление вызывающей подпрограмме. Возвращаемое значение находится в EAX
}
}
Стек восстанавливает вызывающая подпрограмма.
pascal
Соглашение о вызовах языка Паскаль в D объявляется как функция с атрибутом extern(Pascal). Аргументы передаются в прямом порядке, стек восстанавливает вызываемая процедура. Значение возвращается через передаваемый неявно первый аргумент.
stdcall
Соглашение операционной системы Windows, используемое в WinAPI. Объявление: extern(Windows). Аналогично cdecl, но стек восстанавливает вызываемая подпрограмма.
fastcall
Наименее стандартизированное и наиболее производительное соглашение о вызовах. Имеет две разновидности – Microsoft fastcall и Borland fastcall. В первом случае первые два аргумента в прямом порядке передаются через регистры ECX и EDX. Остальные аргументы передаются через стек в обратном порядке. Во втором случае через регистры EAX, EDX и ECX передаются первые три аргумента в прямом порядке, остальные аргументы передаются через стек в обратном порядке. В обоих случаях, если размер аргумента больше размера регистра, он передается через стек. Компиляторы D на данный момент не поддерживают данное соглашение, однако при использовании динамических библиотек есть возможность получить указатель на такую функцию и вызвать ее с помощью встроенного ассемблера.
thiscall
Данное соглашение обеспечивает вызов методов класса в языке С++. Полностью аналогично stdcall. Указатель на объект, метод которого вызывается, передается через ECX.
Соглашение языка D
Функция D гарантирует сохранность регистров EBX, ESI, EDI, EBP.
Если данная функция имеет постоянное количество аргументов, переменное количество гомогенных аргументов или это шаблонная функция с переменным количеством аргументов, аргументы передаются в прямом порядке и стек очищает вызываемая процедура. (В противном случае аргументы передаются в обратном порядке, после чего передается аргумент _arguments. _argptr не передается, он вычисляется на базе _arguments. Стек в этом случае очищает вызывающая процедура.) После этого в стеке резервируется пространство под возвращаемое значение, если оно не может быть возвращено через регистр. Последним передается аргумент this, если вызываемая процедура – метод структуры или класса, или указатель на контекст, если вызываемая процедура – делегат. Последний аргумент передается через регистр EAX, если он умещается в регистр, не является трехбайтовой структурой и не относится к типу с плавающей запятой. Аргументы ref и out передаются как указатель, lazy – как делегат.
Возвращаемое значение передается так:
bool,byte,ubyte,short,ushort,int,uint, 1-, 2- и 4-байтовые структуры, указатели (в том числе на объекты и интерфейсы), ссылки – вEAX;long,ulong, 8-байтовые структуры – вEDX(старшая часть) иEAX(младшая часть);float,double,real,ifloat,idouble,ireal– вST0;cfloat,cdouble,creal– вST1(действительная часть) иST0(мнимая часть);- динамические массивы – в
EDX(указатель) иEAX(длина массива); - ассоциативные массивы – в
EAX; - делегаты – в
EDX(указатель на функцию) иEAX(указатель на контекст).
В остальных случаях аргументы передаются через скрытый аргумент, размещенный на стеке. В EAX в этом случае помещается указатель на этот аргумент.
В начало ⮍ Наверх ⮍
11.10.4.2. Соглашения о вызовах архитектуры x86-64
С переходом к архитектуре x86-64 количество соглашений о вызовах существенно сократилось. По сути, осталось только два соглашения о вызовах – Microsoft x64 calling convention для Windows и AMD64 ABI convention для Posix.
Microsoft x64 calling convention
Это соглашение о вызовах очень напоминает fastcall. Аргументы передаются в прямом порядке. Первые 4 целочисленных аргумента передаются в RCX, RDX, R8, R9. Аргументы размером 16 байт, массивы и строки передаются как указатель. Первые 4 аргумента с плавающей запятой передаются через XMM0, XMM1, XMM2, XMM3. При этом место под эти аргументы резервируется в стеке. Остальные аргументы передаются через стек. Стек очищает вызывающая процедура. Возвращаемое значение передается в RAX, если оно умещается в 8 байт и не является числом с плавающей запятой. Число с плавающей запятой возвращается в XMM0. Если возвращаемое значение больше 64 бит, память под него выделяет вызывающая процедура, передавая ее как скрытый аргумент. В этом случае в RAX возвращается указатель на этот аргумент.
AMD64 ABI convention
Данное соглашение о вызовах используется в Posix-совместимых операционных системах и напоминает предыдущее, однако использует больше регистров. Для передачи целых чисел и адресов используются регистры RDI, RSI, RDX, RCX, R8 и R9, для передачи чисел с плавающей запятой – XMM0, XMM1, XMM2, XMM3, XMM4, XMM5, XMM6 и XMM7. Если требуется передать аргумент больше 64 бит, но не больше 256 бит, он передается по частям через регистры общего назначения. В отличие от Microsoft x64, для переданных в регистрах аргументов место в стеке не резервируется. Возвращаемое значение передается так же, как и в Microsoft x64.
В начало ⮍ Наверх ⮍
11.10.5. Рациональность
Решив применить встроенный ассемблер для оптимизации программы, следует понимать цену повышения эффективности. Ассемблерный код трудно отлаживать, еще труднее сопровождать. Ассемблерный код об ладает плохой переносимостью. Даже в пределах одной архитектуры наборы инструкций разных процессоров несколько различаются. Более новый процессор может предложить более эффективное решение стоящей перед вами задачи. А раз уж вы добиваетесь максимальной производительности, то, возможно, предпочтете скомпилировать несколько версий своей программы для различных целевых архитектур, например одну переносимую версию, использующую только инструкции из набора i386, другую – для процессоров AMD, третью – для Intel Core. Для обычного высокоуровневого кода достаточно просто указать соответствующий флаг компиляции11, а вот в случае с ассемблером придется создавать несколько версий кода, делающих одно и то же, но разными способами.
version(AMD)
{
version = i686;
version = i386;
}
else version(iCore)
{
version = i686;
version = i386;
}
else version(i686)
{
version = i386;
}
void fastProcess()
{
version(AMD)
{
// ...
}
else version(iCore)
{
// ...
}
else version(i686)
{
// ...
}
else version(i386)
{
// ...
}
else
{
// ...
}
}
И все это ради того, чтобы выжать из функции fastProcess максимум производительности! Тут-то и надо задаться вопросом: а в самом ли деле эта функция является краеугольным камнем вашей программы? Может быть, ваша программа недостаточно производительна из-за ошибки на этапе проектирования, и выбор другого решения позволит сэкономить секунды процессорного времени – против долей миллисекунд, сэкономленных на оптимизации fastProcess? А может, время и, как следствие, деньги, которых требует написание ассемблерного кода, лучше направить на повышение производительности целевой машины? В любом случае задействовать встроенный ассемблер для повышения производительности нужно в последнюю очередь, когда остальные средства уже испробованы.
В начало ⮍ Наверх ⮍
-
Прямой порядок байтов – от старшего к младшему байту. – Прим. пер. ↩︎
-
Обратный порядок байтов – от младшего к старшему байту. – Прим. пер. ↩︎
-
«Shebang» – от англ. sharp-bang или hash-bang, произношение символов
#!– Прим. науч. ред. ↩︎ -
Текущие версии реализации позволяют включать модули на уровне классов и функций. – Прим. науч. ред. ↩︎
-
В тексте / используется в качестве обобщенного разделителя; необходимо понимать, что реа льный разделитель зависит от системы. ↩︎
-
Описание этой части языка не было включено в оригинал книги, но поскольку данная возможность присутствует в текущих реализациях языка, мы добавили ее описание в перевод. – Прим. науч. ред. ↩︎
-
Фобос (Phobos) – больший из двух спутников планеты Марс. «Марс» – изначальное название языка D (см. введение). Digital Mars (Цифровой Марс) – компания, разработавшая язык D и эталонную реализацию языка – компилятор
dmd(от Digital Mars D). – Прим. науч. ред. ↩︎ -
Описание этой части языка не было включено в оригинал книги, но поскольку эта возможность присутствует в текущих реализациях языка, мы добавили ее описание в перевод. – Прим. науч. ред. ↩︎
-
Например, есть хороший учебник для вузов «Assembler» В. И. Юрова. – Прим. науч. ред. ↩︎
-
Ассемблер dmd2.052 не поддерживает доступ к регистру
RIP. Возможно, данная функция появится позже. Ну а пока вместоmov AL, [RIP];вы можете написать мантруdb 0x8A, 0x05; di 0x00000000;, тем самым сообщив свое желание на языке процессора. Помните: если транслятор не понимает некоторые символы или инструкции, вы можете транслировать ассемблерный код в машинный сторонним транслятором и вставить в свой ассемблерный код числовое представление команды, воспользовавшись псевдоинструкциями семействаdb. – Прим. науч. ред. ↩︎ -
Компилятор dmd2.057 пока трудно назвать промышленным компилятором, поэтому упомянутого механизма в нем пока нет, а вот компилятор языка C
gccпредоставляет возможность указать целевую платформу. Это позволяет получить максимально эффективный машинный код для данной платформы, при этом в код на языке C вносить изменения не нужно. Читателям, нуждающимся в компиляторах D, способных генерировать более оптимизированный код, следует обратить внимание на проекты GDC (GNU D compiler) и LDC (LLVM D compiler) компиляторов D, построенных на базе генераторов кода GCC и LLVM. – Прим. науч. ред. ↩︎