# 6. Классы. Объектно-ориентированный стиль
[🢀 5. Данные и функции. Функциональный стиль](../05-%D0%B4%D0%B0%D0%BD%D0%BD%D1%8B%D0%B5-%D0%B8-%D1%84%D1%83%D0%BD%D0%BA%D1%86%D0%B8%D0%B8-%D1%84%D1%83%D0%BD%D0%BA%D1%86%D0%B8%D0%BE%D0%BD%D0%B0%D0%BB%D1%8C%D0%BD%D1%8B%D0%B9-%D1%81%D1%82%D0%B8%D0%BB%D1%8C/) **6. Классы. Объектно-ориентированный стиль** [7. Другие пользовательские типы 🢂](../07-%D0%B4%D1%80%D1%83%D0%B3%D0%B8%D0%B5-%D0%BF%D0%BE%D0%BB%D1%8C%D0%B7%D0%BE%D0%B2%D0%B0%D1%82%D0%B5%D0%BB%D1%8C%D1%81%D0%BA%D0%B8%D0%B5-%D1%82%D0%B8%D0%BF%D1%8B/)
- [6.1. Классы](#6-1-классы)
- [6.2. Имена объектов – это ссылки](#6-2-имена-объектов-это-ссылки)
- [6.3. Жизненный цикл объекта](#6-3-жизненный-цикл-объекта)
- [6.3.1. Конструкторы](#6-3-1-конструкторы)
- [6.3.2. Делегирование конструкторов](#6-3-2-делегирование-конструкторов)
- [6.3.3. Алгоритм построения объекта](#6-3-3-алгоритм-построения-объекта)
- [6.3.4. Уничтожение объекта и освобождение памяти](#6-3-4-уничтожение-объекта-и-освобождение-памяти)
- [6.3.5. Алгоритм уничтожения объекта](#6-3-5-алгоритм-уничтожения-объекта)
- [6.3.6. Стратегия освобождения памяти](#6-3-6-стратегия-освобождения-памяти-5)
- [6.3.7. Статические конструкторы и деструкторы](#6-3-7-статические-конструкторы-и-деструкторы)
- [6.4. Методы и наследование](#6-4-методы-и-наследование)
- [6.4.1. Терминологический «шведский стол»](#6-4-1-терминологический-шведский-стол)
- [6.4.2. Наследование – это порождение подтипа. Статический и динамический типы](#6-4-2-наследование-это-порождение-подтипа-статический-и-динамический-типы)
- [6.4.3. Переопределение – только по желанию](#6-4-3-переопределение-только-по-желанию)
- [6.4.4. Вызов переопределенных методов](#6-4-4-вызов-переопределенных-методов)
- [6.4.5. Ковариантные возвращаемые типы](#6-4-5-ковариантные-возвращаемые-типы)
- [6.5. Инкапсуляция на уровне классов с помощью статических членов](#6-5-инкапсуляция-на-уровне-классов-с-помощью-статических-членов)
- [6.6. Сдерживание расширяемости с помощью финальных методов](#6-6-сдерживание-расширяемости-с-помощью-финальных-методов)
- [6.6.1. Финальные классы](#6-6-1-финальные-классы)
- [6.7. Инкапсуляция](#6-7-инкапсуляция)
- [6.7.1. private](#6-7-1-private)
- [6.7.2. package](#6-7-2-package)
- [6.7.3. protected](#6-7-3-protected)
- [6.7.4. public](#6-7-4-public)
- [6.7.5. export](#6-7-5-export)
- [6.7.6. Сколько инкапсуляции?](#6-7-6-сколько-инкапсуляции)
- [6.8. Основа безраздельной власти](#6-8-основа-безраздельной-власти)
- [6.8.1. string toString()](#6-8-1-string-tostring)
- [6.8.2. size_t toHash()](#6-8-2-size_t-tohash)
- [6.8.3. bool opEquals(Object rhs)](#6-8-3-bool-opequalsobject-rhs)
- [6.8.4. int opCmp(Object rhs)](#6-8-4-int-opcmpobject-rhs)
- [6.8.5. static Object factory (string className)](#6-8-5-static-object-factory-string-classname)
- [6.9. Интерфейсы](#6-9-интерфейсы)
- [6.9.1. Идея невиртуальных интерфейсов (NVI)](#6-9-1-идея-невиртуальных-интерфейсов-nvi)
- [6.9.2. Защищенные примитивы](#6-9-2-защищенные-примитивы)
- [6.9.3. Избирательная реализация](#6-9-3-избирательная-реализация)
- [6.10. Абстрактные классы](#6-10-абстрактные-классы)
- [6.11. Вложенные классы](#6-11-вложенные-классы)
- [6.11.1. Вложенные классы в функциях](#6-11-1-вложенные-классы-в-функциях)
- [6.11.2. Статические вложенные классы](#6-11-2-статические-вложенные-классы)
- [6.11.3. Анонимные классы](#6-11-3-анонимные-классы)
- [6.12. Множественное наследование](#6-12-множественное-наследование)
- [6.13. Множественное порождение подтипов](#6-13-множественное-порождение-подтипов)
- [6.13.1. Переопределение методов в сценариях множественного порождения подтипов](#6-13-1-переопределение-методов-в-сценариях-множественного-порождения-подтипов)
- [6.14. Параметризированные классы и интерфейсы](#6-14-параметризированные-классы-и-интерфейсы)
- [6.14.1. И снова гетерогенная трансляция](#6-14-1-и-снова-гетерогенная-трансляция)
- [6.15. Переопределение аллокаторов и деаллокаторов](#6-15-переопределение-аллокаторов-и-деаллокаторов-16)
- [6.16. Объекты scope](#6-16-объекты-scope-17)
- [6.17. Итоги](#6-17-итоги)
С годами объектно-ориентированное программирование (ООП) из симпатичного малыша выросло в несносного прыщавого подростка, но в конце концов повзрослело и превратилось в нынешнего уравновешенного индивида. Сегодня мы гораздо лучше осознаем не только мощь, но и неизбежные ограничения объектно-ориентированной технологии. В свою очередь, это позволило сообществу программистов понять, что наиболее выгодный подход к созданию надежных проектов – сочетать сильные стороны ООП и других парадигм программирования. Это довольно отчетливая тенденция: все больше современных языков программирования или включают эклектичные средства, или изначально разработаны для применения ООП в сочетании с другими парадигмами. D принадлежит к последним, и его достижения в сфере гармоничного объединения разных парадигм программирования некоторые даже считают выдающимися. В этой главе исследуются объектно-ориентированные средства D и их взаимодействие с другими средствами языка. Хорошая стартовая площадка для глубокого изучения объектно-ориентированной парадигмы – классический труд Бертрана Мейера «Объектно-ориентированное конструирование программных систем» (для более формального изучения лучше подойдут «Типы в языках программирования» Пирса).
[В начало ⮍](#6-классы-объектно-ориентированный-стиль)
## 6.1. Классы
Единицей объектной инкапсуляции в D служит класс. С помощью классов можно создавать объекты, как вырезают печенье с помощью формочек. Класс может определять константы, состояния классов, состояния объектов и методы. Например:
```d
class Widget
{
// Константа
enum fudgeFactor = 0.2;
// Разделяемое неизменяемое значение
static immutable defaultName = "A Widget";
// Некоторое состояние, определенное для всех экземпляров класса Widget
string name = defaultName;
uint width, height;
// Статический метод
static double howFudgy()
{
return fudgeFactor;
}
// Метод
void changeName(string another)
{
name = another;
}
// Метод, который нельзя переопределить
final void quadrupleSize()
{
width *= 2;
height *= 2;
}
}
```
Объект типа `Widget` создается с помощью выражения `new`, результат вычисления которого сохраняется в именованном объекте: `new Widget` (см. раздел 2.3.6.1). Для обращения к идентификатору, определенному внутри класса `Widget`, расположите его после имени объекта, с которым вы хотите работать, и разделите эти два идентификатора точкой. Если член класса, к которому нужно обратиться, является статическим, перед его идентификатором достаточно указать имя класса. Например:
```d
unittest
{
// Обратиться к статическому методу класса Widget
assert(Widget.howFudgy() == 0.2);
// Создать экземпляр класса Widget
auto w = new Widget;
// Поиграть с объектом типа Widget
assert(w.name == w.defaultName); // Или Widget.defaultName
w.changeName("Мой виджет");
assert(w.name == "Мой виджет");
}
```
Обратите внимание на небольшую хитрость. В приведенном коде использовано выражение `w.defaultName`, а не `Widget.defaultName`. Для обращения к статическому члену класса всегда можно вместо имени класса использовать имя экземпляра класса. Это возможно, потому что при обработке выражения слева от точки сначала выполняется разрешение имени и только потом идентификация объекта (если потребуется). Выражение w в любом случае вычисляется: будет оно использовано или нет.
[Исходный код](src/chapter-6-1/)
[В начало ⮍](#6-1-классы) [Наверх ⮍](#6-классы-объектно-ориентированный-стиль)
## 6.2. Имена объектов – это ссылки
Проведем небольшой эксперимент:
```d
import std.stdio;
class A
{
int x = 42;
}
unittest
{
auto a1 = new A;
assert(a1.x == 42);
auto a2 = a1;
a2.x = 100;
assert(a1.x == 100);
}
```
Этот эксперимент завершается успешно (все проверки пройдены), а значит, `a1` и `a2` не являются разными объектами: изменение объекта `a2` действительно отразилось и на ранее созданном объекте `a1`. Эти две переменные – всего лишь два разных имени одного и того же объекта, следовательно, изменение `a2` влияет на `a1`. Инструкция `auto a2 = a1;` не создает новый объект типа `A`, а только дает существующему объекту еще одно имя (рис. 6.1).
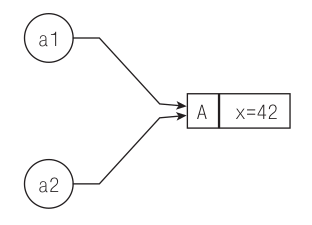
***Рис. 6.1.*** *Инструкция `auto a2 = a1` только вводит дополнительное имя для того же внутреннего объекта*
Такое поведение соответствует принципу: все экземпляры класса являются *сущностями*, то есть обладают «индивидуальностью» и не предполагают копирования без серьезных причин. Экземпляры значения (например, встроенные числа), напротив, характеризуются полным копированием; новый тип-значение определяется с помощью структуры (см. главу 7).
Итак, в мире классов сначала нам встречаются *объекты* (*экземпляры класса*), а затем *ссылки* на них. Воображаемые стрелки, присоединяющие ссылки к объектам, называются *привязками* (*bindings*); мы, например, говорим, что идентификаторы `a1` и `a2` привязаны к одному и тому же объекту, другими словами, имеют одну и ту же привязку. С объектами можно работать только через ссылки на них. Получив при создании место в памяти, объект остается там навсегда (по крайней мере до тех пор, пока он вам нужен). Если вам надоест какой-то объект, просто привяжите его ссылку к другому объекту. Например, если нужно, чтобы две ссылки обменялись привязками:
```d
unittest
{
auto a1 = new A;
auto a2 = new A;
a1.x = 100;
a2.x = 200;
// Заставим a1 и a2 обменяться привязками
auto t = a1;
a1 = a2;
a2 = t;
assert(a1.x == 200);
assert(a2.x == 100);
}
```
Вместо трех последних строк можно было бы использовать универсальную вспомогательную функцию `swap` из модуля `std.algorithm`: `swap(a1, a2)`, но явная запись процесса обмена нагляднее. На рис. 6.2 продемонстрированы привязки до и после обмена.
Сами объекты остаются на том же месте, то есть после создания они никогда не перемещаются в памяти. Просто замечательно, объект никогда не исчезнет: можно рассчитывать, что объект навсегда останется там, куда он был помещен при создании. (Сборщик мусора перерабатывает в фоновом режиме те объекты, которые больше не используются.) Ссылки на объекты (в данном случае `a1` и `a2`) можно заставить «смотреть в другую сторону», переназначив их привязку. Когда библиотека времени исполнения обнаруживает, что для какого-то объекта больше нет привязанных к нему ссылок, она может заново использовать выделенную под него память (этот процесс называется сбором мусора).[^1] Такое поведение
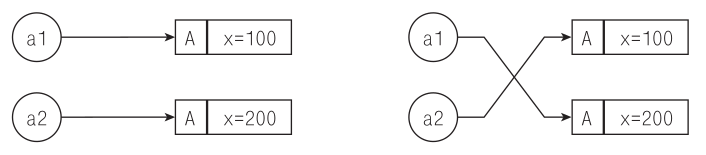
***Рис. 6.2.*** *Привязки до и после обмена. В процессе обмена меняются привязки к ссылкам; сами объекты остаются на том же месте*
в корне отличается от семантики *значения* (например, `int`), в случае которого нет никаких косвенных изменений или привязок: каждое имя прочно закреплено за значением, которым манипулируют с помощью этого идентификатора.
Ссылка, не привязанная к какому-либо объекту, – это «пустая» ссылка (`null`). При инициализации по умолчанию с помощью свойства `.init` ссылки на классы получают значение `null`. Можно сравнивать ссылку с константой `null` и присваивать ссылке значение `null`. Следующие проверки пройдут успешно:
```d
unittest
{
A a;
assert(a is null);
a = new A;
assert(a !is null);
a = null;
assert(a is null);
a = A.init;
assert(a is null);
}
```
Обращение к элементу непривязанной («пустой», `null`) ссылки ведет к аппаратной ошибке, экстренно останавливающей приложение (или на некоторых системах и при некоторых обстоятельствах запускающей отладчик). Если вы попытаетесь осуществить доступ к нестатическому элементу ссылки и компилятор может статически доказать, что эта ссылка в любом случае в этот момент окажется пустой, он откажется компилировать код.
```d
A a;
a.x = 5; // Ошибка! Ссылка a пуста!
```
Иногда компилятор ведет себя сдержанно, стараясь не слишком надоедать вам: если ссылка только *может* быть пустой (но не всегда будет таковой), коду дается «зеленый свет» и все разговоры об ошибках откладываются до времени исполнения программы. Например:
```d
A a;
if (‹условие›)
{
a = new A;
}
...
if (‹условие›)
{
a.x = 43; // Все в порядке
}
```
Компилятор «пропускает» такой код, даже несмотря на то, что между двумя вычислениями `‹условие›` может изменить значение. В общем случае было бы непросто проверить, насколько корректна инициализация объекта, так что компилятор решает, что вы сами знаете, что делаете (кроме самых простых случаев, когда он уверен, что вы пытаетесь использовать пустую ссылку неподобающим образом).
В языке D применяется такой же основанный на ссылочной семантике подход к обработке объектов классов, как и во многих других объектно-ориентированных языках. Использование для объектов классов ссылочной семантики и сбора мусора имеют как положительные, так и отрицательные следствия, включая следующие:
- **+ Полиморфизм**. Уровень косвенности, достигаемый благодаря последовательному использованию ссылок, делает возможной поддержку полиморфизма. Все ссылки обладают одинаковым размером, а ассоциированные с ними объекты могут иметь разные размеры, даже если имеют якобы один и тот же тип (что осуществляется через наследование, о котором речь пойдет очень скоро). Поскольку ссылки обладают одним и тем же размером независимо от размера объектов, на которые они ссылаются, вы всегда можете использовать вместо ссылок на объекты классов-потомков ссылки на объекты родительских классов. Кроме того, как следует работают массивы объектов – даже когда объекты в массиве обладают разными размерами. Если вы имели дело с C++, вам, конечно же, известно о необходимости использования указателей для организации полиморфизма и о разнообразных летальных проблемах, с которыми сталкивается программист, если забывает об этом.
- **+ Безопасность**. Многие воспринимают сбор мусора только как удобное средство, которое облегчает процесс кодирования, освобождая программиста от обязанности управлять памятью. Возможно, это прозвучит неожиданно, но модель вечной жизни (которая воплощается благодаря сбору мусора) и безопасность памяти прочно связаны. Там, где жизнь вечна, нет «висячих» ссылок, то есть ссылок на некоторый переставший существовать объект, память которого была заново использована – отдана в распоряжение совершенно постороннего объекта. Заметим, что той же степени безопасности можно добиться, везде используя семантику значения (команда `auto a2 = a1` дублирует экземпляр класса `A`, на который ссылается `a1`, и привязывает `a2` к копии). Такой подход, однако, вряд ли интересен, поскольку лишает возможности создавать какие-либо ссылочные структуры данных (такие как списки, графы и вообще любые разделяемые ресурсы).
- **– Цена выделения памяти**. В общем случае классы должны располагаться в куче, подлежащей сбору мусора, что обычно медленнее работает и съедает больше памяти, чем при размещении в стеке. В последнее время разница сильно уменьшилась, но она все же есть.
- **– Связанность идентификаторов, определенных далеко друг от друга**. Основной риск при использовании ссылок – неумеренное порождение псевдонимов. При повсеместном применении ссылочной семантики очень просто получить ссылки на один и тот же объект в разных – и самых неожиданных – местах. Переменные `a1` и `a2` на рис. 6.1 могут находиться сколь угодно далеко друг от друга, т. к. по логике приложения кроме них у того же объекта может быть множество других, висячих ссылок. Любопытно, но если объект неизменяем, проблема исчезает: пока никто не изменяет объект, нет и связанности. Сложности возникают, когда некоторое изменение, имевшее место в некотором контексте, неожиданно и драматично повлияет на состояние (как это видится из другой части приложения). Один из способов улучшить такое положение дел заключается в постоянном явном дублировании, которое обычно осуществляется с помощью специального метода `clone`. Минусы этой техники: она зависит от дисциплинированности человека, и такой образ действий может снизить скорость работы приложения, если некоторые его части решат консервативно клонировать объекты из принципа «как бы чего не вышло».
Сравним ссылочную семантику с семантикой значений а-ля `int`. У семантики значений есть свои преимущества, среди которых выделяется логический вывод: в выражениях всегда можно заменять равные значения друг на друга, при этом результат не изменяется. (А к ссылкам, использующим для изменения состояния объектов вызовы методов, такой подход неприменим.) Другое важное преимущество семантики значений – скорость. Но даже если вы воспользуетесь динамической щедростью полиморфизма, от ссылочной семантики никуда не деться. Некоторые языки пытались предоставить возможность использовать и ту, и другую семантику и заслужили прозвище «нечистых» (в противоположность чисто объектно-ориентированным языкам, использующим ссылочную семантику унифицированно для всех типов). D нечист и очень гордится этим. Во время разработки необходимо принять решение: если вы желаете работать с некоторым типом в рамках объектно-ориентированной парадигмы, следует выбрать тип `class`; иначе придется использовать тип `struct` и поступиться всеми удобствами ООП, присущими ссылочной семантике.
[Исходный код](src/chapter-6-2/)
[В начало ⮍](#6-2-имена-объектов-это-ссылки) [Наверх ⮍](#6-классы-объектно-ориентированный-стиль)
## 6.3. Жизненный цикл объекта
Теперь, когда мы получили общее представление о местонахождении объекта, подробно изучим его жизненный цикл. Объект создается с помощью выражения `new`:
```d
import std.math;
class Test
{
double a = 0.4;
double b;
}
unittest
{
// Объект создается с помощью выражения new
auto t = new Test;
assert(t.a == 0.4 && isNaN(t.b));
}
```
При вычислении выражения `new Test` конструируется объект типа `Test` с состоянием по умолчанию, то есть экземпляр класса `Test`, каждое из полей которого инициализировано своим значением по умолчанию. Любой тип `T` обладает статически известным значением по умолчанию, обратиться к которому можно через свойство `T.init` (значения свойств `.init` для базовых типов приведены в табл. 2.1). Если вы хотите инициализировать некоторые поля значениями, отличными от соответствующих значений свойства `.init`, укажите при определении этих полей статически известные инициализирующие значения, как показано в предыдущем примере для поля `a`. Выполнение теста модуля при этом не порождает исключений, так как это поле явно инициализируется константой `0.4`, а поле `b` не трогали, а значит, оно неявно инициализируется значением выражения `double.init`, то есть NaN («нечисло»).
[Исходный код](src/chapter-6-3/)
[В начало ⮍](#6-3-жизненный-цикл-объекта) [Наверх ⮍](#6-классы-объектно-ориентированный-стиль)
### 6.3.1. Конструкторы
Разумеется, в большинстве случаев бывает недостаточно инициализировать поля лишь статически известными значениями. Выполнить при создании объекта некоторый код позволяет специальная функция – *конструктор*. Конструктор – это функция с именем `this` и без объявления возвращаемого типа.
```d
class Test
{
double a = 0.4;
int b;
this(int b)
{
this.b = b;
}
}
unittest
{
auto t = new Test(5);
}
```
Если класс определяет хотя бы один конструктор, то неявный конструктор становится недоступным. С классом `Test`, определенным выше, инструкция
```d
auto t = new Test;
```
уже не работает. Цель такого запрета – помочь избежать типичной ошибки: разработчик заботливо определяет ряд конструкторов с параметрами, но совершенно забывает о конструкторе по умолчанию. Как обычно в D такую защиту от забывчивости легко обойти: достаточно показать компилятору, что вы обо всем помните:
```d
class Test
{
double a = 0.4;
int b;
this(int b)
{
this.b = b;
}
this() {} // Конструктор по умолчанию,
// все поля инициализируются неявно
}
```
Внутри метода (кроме статических методов, см. раздел 6.5) ссылка `this` неявно привязывается к объекту-адресату вызова. Иногда (как в предыдущем примере, иллюстрирующем общепринятое соглашение об именовании внутри конструкторов) эта ссылка может оказаться полезной: если с помощью параметра `a` предполагается инициализировать член класса, следует назвать параметр так же, как и член класса, а обращение к последнему уточнить явной ссылкой на объект в виде ключевого слова `this`, избегая таким образом двусмысленности при обращении к параметру и члену класса.
Несмотря на то что можно изменить свойство `this.field` для любого поля `field`, нельзя переназначить привязку самой ссылки `this`, которая всегда воспринимается компилятором как r-значение:
```d
class NoGo
{
void fun()
{
// Просто привяжем this к другому объекту
this = new NoGo; // Ошибка! Нельзя изменять this!
}
}
```
Обычные правила перегрузки функций (раздел 5.5) применимы и к конструкторам: класс может определять любое количество конструкторов, но каждый из них должен обладать уникальной сигнатурой (отличающейся числом или типом параметров, хотя бы на один параметр).
[Исходный код](src/chapter-6-3-1/)
[В начало ⮍](#6-3-1-конструкторы) [Наверх ⮍](#6-классы-объектно-ориентированный-стиль)
### 6.3.2. Делегирование конструкторов
Рассмотрим класс `Widget`, определяющий два конструктора:
```d
class Widget
{
this(uint height)
{
this.width = 1;
this.height = height;
}
this(uint width, uint height)
{
this.width = width;
this.height = height;
}
uint width, height;
...
}
```
В этом коде много повторений, что лишь усугубилось бы в случае классов большего размера, но, к счастью, один конструктор может положиться на другой:
```d
class Widget
{
this(uint height)
{
this(1, height); // Положиться на другой конструктор
}
this(uint width, uint height)
{
this.width = width;
this.height = height;
}
uint width, height;
...
}
```
Однако с вызовом конструкторов а-ля `this(1, h)` связан ряд ограничений. Во-первых, такой вызов возможен только из другого конструктора. Во-вторых, если вы решили сделать такой вызов, то обязаны убедить компилятор, что в вашем конструкторе ровно один такой вызов, несмотря ни на что. Например, следующий конструктор некорректен:
```d
this(uint h)
{
if (h > 1)
{
this(1, h);
}
// Ошибка! При невыполнении условия конструктор будет пропущен
}
```
В этой ситуации компилятор выяснит, что возможны случаи, когда другой конструктор не будет вызван, и интерпретирует это как ошибку. Смысл такого ограничения в четком разграничении двух альтернатив: конструктор или создает и инициализирует объект сам, или делегирует выполнение этой задачи другому конструктору. Варианты, когда неясно, как поступит конструктор (решит действовать самостоятельно или переложит работу на другого), бракуются.
Дважды вызывать один и тот же конструктор также некорректно:
```d
this(uint h)
{
if (h > 1)
{
this(1, h);
}
this(0, h);
}
```
Дважды инициализировать объект еще хуже, чем забыть его инициализировать, так что в этом случае также диагностируется ошибка. В двух словах, конструктору разрешается вызвать другой конструктор или ровно ноль, или ровно один раз. Соблюдение этого правила проверяется во время компиляции с помощью простого анализа потока управления.
[В начало ⮍](#6-3-2-делегирование-конструкторов) [Наверх ⮍](#6-классы-объектно-ориентированный-стиль)
### 6.3.3. Алгоритм построения объекта
Во всех языках построение объекта – не очень простой процесс. Все начинается с получения участка нетипизированной памяти, которая по мере наполнения информацией начинает выглядеть и вести себя как экземпляр класса. И тут никак не обойтись без магии.
В языке D построение объекта включает следующие шаги:
1. *Выделение памяти*. Библиотека времени исполнения выделяет участок «сырой» памяти в куче, достаточный для размещения нестатических полей объекта. Память подо все объекты, основанные на классах, выделяется динамически – в отличие от C++, в D нет способа выделить для объекта память в стеке[^2]. Если выделить память не удалось, построение объекта прерывается: порождается исключительная ситуация.
*Инициализация полей*. Каждое поле инициализируется своим значением по умолчанию. Как уже говорилось, в качестве значения поля по умолчанию выступает значение, указанное при объявлении поля в виде `= значение`, или при отсутствии такой записи значение свойства `.init` типа поля.
2. *Брендирование*. После завершения инициализации полей значениями по умолчанию объекту присваивается статус полноправного экземпляра класса `T` (объект брендируется) еще *до* того, как будет вызван настоящий конструктор.
3. *Вызов конструктора*. Наконец, компилятор инициирует вызов подходящего конструктора. Если класс не определяет собственный конструктор, этот шаг пропускается.
Поскольку объект считается «живым» и правильно построенным сразу после инициализации по умолчанию, настоятельно рекомендуется использовать инициализирующие значения, которые всегда приводят объект в осмысленное состояние. Настоящий конструктор внесет затем свои поправки, приведя объект в другое интересное состояние (разумеется, также осмысленное).
Если ваш конструктор заново присваивает значения некоторым полям, то двойное присваивание не должно быть причиной проблем с быстродействием. В большинстве случаев, если тело конструктора достаточно простое, компилятору хватает ума понять, что первое присваивание лишнее, и применить механизм оптимизации с мрачным названием «уничтожение мертвых присваиваний» (dead assignment elimination).
Если важнее всего эффективность, то в качестве инициализирующего значения поля можно указать ключевое слово `void`; в этом случае нужно очень внимательно проследить за местонахождением инициализирующего присваивания: оно должно быть внутри конструктора[^3]. Возможно, вам покажется удобным использовать `= void` с массивами фиксированной длины. Оптимизация двойной инициализации всех элементов массива – очень сложная задача для компилятора, и вы можете ему помочь. Следующий код эффективно инициализирует массив фиксированного размера значениями `0.0`, `0.1`, `0.2`, ..., `12.7`.
```d
class Transmogrifier
{
double[128] alpha = void;
this()
{
foreach (i, ref e; alpha)
{
e = i * 0.1;
}
}
...
}
```
Иногда некоторые поля намеренно оставляют неинициализированными. Например, экземпляр класса `Transmogrifier` может отслеживать уже задействованную часть массива `alpha` с помощью переменной `usedAlpha`, изначально равной нулю. Таким образом, составные части объекта будут знать, что на самом деле инициализирована только часть массива, а именно элементы с индексами от `0` до `usedAlpha - 1`:
```d
class Transmogrifier
{
double[128] alpha = void;
size_t usedAlpha;
this()
{
// Оставить переменную usedAlpha равной 0, а массив alpha – неинициализированным
}
...
}
```
Изначально переменная `usedAlpha` равна нулю, этого достаточно для инициализации объекта класса `Transmogrifier`. По мере роста `usedAlpha` код не должен читать элементы в интервале `alpha[usedAlpha .. $]`, а только присваивать им значения. Разумеется, за этим должны следить вы, а не компилятор (вот пример того, что порой эффективность неизбежно связана с проверяемостью на этапе компиляции). Хотя такая оптимизация обычно незначительна, иногда лишние принудительные инициализации могут существенно отразиться на общих результатах, и полезно иметь запасной выход.
[В начало ⮍](#6-3-3-алгоритм-построения-объекта) [Наверх ⮍](#6-классы-объектно-ориентированный-стиль)
### 6.3.4. Уничтожение объекта и освобождение памяти
Для всех объектов классов D поддерживает кучу, пополняемую благодаря сбору мусора. Можно считать, что сразу же после выделения памяти под объект он становится вечным (в пределах времени работы самого приложения). Сборщик мусора перерабатывает память, используемую объектом, только если убежден, что больше нет доступных ссылок на этот объект. Такой подход способствует созданию чистого и безопасного кода, основанного на классах.
Для некоторых классов важно иметь зацепку в процессе уничтожения, чтобы освобождать возможно задействованные ими дополнительные ресурсы. Такие классы могут определять *деструктор*, задаваемый как специальная функция с именем `~this`:
```d
import core.stdc.stdlib;
class Buffer
{
private void* data;
// Конструктор
this()
{
data = malloc(1024);
}
// Деструктор
~this()
{
free(data);
}
...
}
```
Этот пример иллюстрирует экстремальную ситуацию – класс, который самостоятельно обслуживает собственный буфер «сырой» памяти. В большинстве случаев класс использует должным образом инкапсулированные ресурсы, так что определять деструкторы вовсе не обязательно.
[В начало ⮍](#6-3-4-уничтожение-объекта-и-освобождение-памяти) [Наверх ⮍](#6-классы-объектно-ориентированный-стиль)
### 6.3.5. Алгоритм уничтожения объекта
Уничтожение объекта, как и его построение, происходит по определенному алгоритму:
1. Сразу же после брендирования (шаг 3 построения) объект считается «живым» и попадает под наблюдение сборщика мусора. Обратите внимание: это происходит, даже если позже при выполнении определенного пользователем конструктора возникнет исключение. Учитывая, что инициализация по умолчанию и брендирование всегда выполняются успешно, можно сделать вывод, что объект, которому успешно выделена память, с точки зрения сборщика мусора выглядит как полноценный объект.
2. Объект используется в любом месте программы.
3. Все доступные ссылки на объект исчезли; объект больше недоступен никакому коду.
4. В некоторый момент (зависит от реализации) система осознает, что память объекта может быть переработана, и вызывает деструктор.
5. Спустя еще некоторое время (сразу после вызова деструктора или когда-нибудь позже) система заново использует память объекта.
Важная деталь, имеющая отношение к двум последним шагам: сборщик мусора гарантирует, что деструктор объекта никогда не сможет обратиться к объекту, память которого уже освобождена. Можно обратиться к только что уничтоженному объекту, но не объекту, память которого только что освобождена. В языке D уничтоженные объекты «удерживают» память в течение небольшого промежутка времени – пока не уничтожены связанные с ними объекты. Иначе была бы невозможна безопасная реализация уничтожения и освобождения памяти объектов, ссылающихся друг на друга по кругу (например, кольцевого списка).
Описанный жизненный цикл может варьироваться по разным причинам. Во-первых, очень вероятно, что выполнение приложения завершится еще до достижения даже шага 4, как бывает с маленькими приложениями в системах с достаточным количеством памяти. В таком случае D предполагает, что завершающееся приложение *де-факто* освободит все ресурсы, ассоциированные с ним, так что никакого деструктора язык не вызывает.
Другой способ вмешаться в естественный жизненный цикл объекта – явный вызов деструктора, например с помощью функции `clear` из модуля `object` (модуль стандартной библиотеки, автоматически подключаемый во время каждой компиляции).
```d
unittest
{
auto b = new Buffer;
...
clear(b); // Избавиться от дополнительного состояния b
... // Здесь все еще можно использовать b
}
```
Вызовом `clear(b)` пользователь выражает желание явно вызвать деструктор `b` (если таковой имеется), стереть состояние этого объекта до `Buffer.init` и установить указатель на таблицу виртуальных функций в `null`, после чего при попытке вызвать метод этого объекта будет сгенерирована ошибка времени исполнения. Тем не менее, в отличие от аналогичной функции в C++, функция `clear` не освобождает память объекта, а в D отсутствует оператор `delete`. (Раньше в D был оператор `delete`, но он уже не используется и считается устаревшим.) Вы все равно можете освободить память, вызвав функцию `GC.free()` из модуля `core.memory`, если действительно, *действительно* знаете, что делаете. В отличие от освобождения памяти, вызывать функцию `clear` безопасно, поскольку в этом случае все данные остаются на месте и нет угрозы появления «висячих» указателей. После выполнения инструкции `clear(obj);` можно, как и раньше, обращаться к объекту `obj` и использовать его для любых целей, даже если он уже не обладает никаким особенным состоянием. Например, следующий код D считает корректным[^4]:
```d
unittest
{
auto b = new Buffer;
auto b1 = b; // Дополнительный псевдоним для b
clear(b);
assert(b1.data !is null); // Дополнительный псевдоним все еще ссылается на (корректный) "скелет" b
}
```
Таким образом, после вызова функции `clear` объект остается «живым» и пригодным для использования, но его деструктор уже вызван, а состояние объекта соответствует состоянию, которое экземпляры этого класса приобретают после вызова конструктора. Любопытно, что в процессе следующего сбора мусора деструктор объекта будет вызван *снова*. Это происходит, потому что сборщик мусора, естественно, и понятия не имеет о том, в каком состоянии вы оставили объект.
Почему была выбрана такая модель поведения? Ответ прост: благодаря разделению уничтожения объекта и освобождения памяти вы получаете возможность вручную контролировать «дорогие» ресурсы, которые могут находиться в ведении объекта (такие как файлы, сокеты, мьютексы и системные дескрипторы), и одновременно гарантии безопасности памяти. Использование `new` и `clear` предохраняет вас от создания висячих указателей. (Встреча с которыми реально угрожает тому, кто якшается с функциями `malloc` и `free` из C или с той же функцией `GC.free`.) В общем случае имеет смысл разделять освобождение ресурсов (безопасно) и переработку памяти (небезопасно). Память в корне отличается от всех других ресурсов, поскольку она представляет собой физическую основу для системы типов. Случайно перераспределив ее, вы рискуете подорвать любые гарантии, которые только может дать система типов.
[В начало ⮍](#6-3-5-алгоритм-уничтожения-объекта) [Наверх ⮍](#6-классы-объектно-ориентированный-стиль)
### 6.3.6. Стратегия освобождения памяти[^5]
На всем протяжении данной главы предлагается, иногда весьма навязчиво, одна стратегия освобождения памяти – использование сборщика мусора. Эта стратегия необычайно удобна, но имеет серьезный недостаток – нерациональное использование памяти. Рассмотрим работу сборщика мусора.
Когда сборщик мусора выделяет некоторую область памяти, он запоминает указатель на эту область и ее размер и начинает вести учет ссылок на данную область. Когда не остается ни одной ссылки на эту область, эта область становится вакантной для освобождения. Но освобождение происходит не сразу.
Если в какой-то момент для выделения очередного блока памяти сборщику мусора не хватает собственного пула памяти, он запускает процедуру сбора мусора, надеясь освободить достаточно памяти для выделения блока запрошенного размера. Если после сбора мусора памяти пула по-прежнему не хватает, сборщик мусора запрашивает память у операционной системы. Процесс сбора мусора сопровождается приостановкой всех потоков выполнения и занимает сравнительно продолжительное время. Впрочем, можно инициировать внеочередной сбор мусора, вызвав функцию `core.memory.GC.collect()`.
Функция `core.memory.GC.disable()` запрещает автоматический вызов процесса сбора мусора, `core.memory.GC.enable()` разрешает его. Если функция `disable` была вызвана несколько раз, то функция `enable` должна быть вызвана как минимум столько же раз для разрешения автоматического сбора мусора.
Функция `core.memory.GC.minimize()` возвращает лишнюю память операционной системе.
Может возникнуть соблазн уничтожать объекты вручную, оставляя сборщику мусора наиболее сложные ситуации, когда отследить жизнь объекта проблематично.
Рассмотрим пример:
```d
import std.c.stdlib;
class Storage
{
private SomeClass sub_obj_1;
private SomeClass sub_obj_2;
private void* data;
this()
{
sub_obj_1 = new SomeClass;
sub_obj_2 = new SomeClass;
data = malloc(4096);
}
~this()
{
free(data);
// Блок data выделен функцией malloc и не учтен сборщиком мусора,
// а значит, должен быть уничтожен вручную.
}
}
...
Storage obj = new Storage; // Создали объект Storage
...
delete obj; // Уничтожили объект
```
Объект `obj` действительно уничтожен. Что же стало с внутренними объектами `obj`? Они остались целы, и сборщик мусора их рано или поздно уничтожит. Но предположим, мы уверены, что кроме как в объекте `obj` ссылок на эти объекты нет, и логично уничтожить их вместе с `obj`.
Что ж, изменим соответствующим образом деструктор:
```d
~this()
{
delete sub_obj_1;
delete sub_obj_2;
free(data);
}
```
Приведенный пример теперь отработает как надо. Но что если объект `obj` не уничтожать вручную, а оставить на откуп сборщику мусора? В этой ситуации никто не гарантирует, что деструктор `obj` будет запущен до уничтожения `sub_obj_1`. Если все произойдет наоборот, то деструктор `obj` попытается уничтожить уничтоженный объект, что вызовет аварийное завершение программы.
Значит, вызывать деструктирующие функции в деструкторе следует только в том случае, если этот деструктор вызывается вручную, а не сборщиком мусора.
Как определить, кто вызывает деструктор? Для этого достаточно определить собственный деаллокатор (см. раздел 6.15) (если, конечно, ваша реализация компилятора предоставляет такую возможность).
```d
class Foo
{
char[] arr;
void* buffer;
this()
{
arr = new char[500];
buffer = std.c.malloc(500);
}
~this()
{
std.c.free(buffer);
}
private void dispose()
{
delete arr;
}
delete(void* v)
{
(cast(F)v).dispose();
core.memory.GC.free(v);
}
}
```
В данном случае мы переопределяем поведение оператора `delete`, сообщая ему, что перед непосредственным освобождением памяти следует вызвать метод `dispose`. В случае уничтожения объекта сборщиком мусора метод `dispose` вызван не будет.
[В начало ⮍](#6-3-6-стратегия-освобождения-памяти-5) [Наверх ⮍](#6-классы-объектно-ориентированный-стиль)
### 6.3.7. Статические конструкторы и деструкторы
Внутри классов, как и повсюду в D, статические данные (объявляемые с ключевым словом `static`) должны всегда инициализироваться константами, известными во время компиляции. Чтобы предоставить легальное средство выполнения кода во время запуска потока, компилятор позволяет определять специальную функцию `static this()`. Код инициализации на уровне модуля и на уровне класса объединяется, и библиотека поддержки времени исполнения обрабатывает статическую инициализацию в заданном порядке.
Внутри класса можно определить один или несколько статических конструкторов по умолчанию:
```d
class A
{
static A a1;
static this()
{
a1 = new A;
}
...
static this()
{
a2 = new A;
}
static A a2;
}
```
Такая функция называется *статическим конструктором класса*. Во время загрузки приложения перед выполнением функции `main` (а в многопоточном приложении – в момент создания нового потока) runtime-библиотека последовательно выполняет все статические конструкторы в том порядке, в каком они объявлены в исходном коде. В предыдущем примере поле `a1` будет инициализировано раньше, чем поле `a2`. Порядок выполнения статических конструкторов различных классов внутри одного модуля тоже определяется лексическим порядком. Статические конструкторы в модулях, не имеющих отношения друг к другу, выполняются в произвольном порядке. Наконец, самое интересное: статические конструкторы классов в модулях, взаимно зависящих друг от друга, упорядочиваются так, чтобы исключить возможность использования класса до выполнения его статического конструктора.
Инициализации упорядочиваются так: допустим, класс `A` определен в модуле `MA`, а класс `B` – в модуле `MB`. Тогда возможны следующие ситуации:
- только один из классов `A` и `B` определяет статический конструктор – здесь не нужно беспокоиться ни о каком упорядочивании;
- ни один из модулей `MA` и `MB` не включает другой модуль (`MB` и `MA` соответственно) – последовательность инициализации классов не определяется (сработает любой порядок, поскольку модули не зависят друг от друга);
- модуль `MA` включает модуль `MB` – статический конструктор `B` выполняется перед статическим конструктором `A`;
- модуль `MB` включает модуль `MA` – статический конструктор `A` выполняется перед статическим конструктором `B`;
- модуль `MA` включает модуль `MB` и модуль `MB` включает модуль `MA` – диагностируется ошибка «циклическая зависимость», и выполнение прерывается на этапе загрузки программы.
Эта цепь рассуждений на самом деле больше зависит не от классов `A` и `B`, а от самих модулей и отношений включения между ними. Подробно эти темы обсуждаются в главе 11.
Если при выполнении статического конструктора возникает исключение, выполнение программы также прерывается. Если же все проходит успешно, классам также дается возможность убрать за собой во время останова потока с помощью деструкторов, которые, как и можно было предположить, выглядят так:
```d
class A
{
static A a1;
static ~this()
{
clear(a1);
}
...
static A a2;
static ~this()
{
clear(a2);
}
}
```
Статические деструкторы запускаются в процессе останова потока. Для каждого модуля они выполняются в порядке, *обратном* порядку их определения. В примере выше деструктор `a2` будет вызван до вызова деструктора `a1`. При участии нескольких модулей порядок вызова статических деструкторов, определенных в этих модулях, соответствует порядку, обратному тому, в котором этим модулям давался шанс вызвать свои статические конструкторы. «Бесконечная башня из черепах»[^6] наоборот.
[В начало ⮍](#6-3-7-статические-конструкторы-и-деструкторы) [Наверх ⮍](#6-классы-объектно-ориентированный-стиль)
## 6.4. Методы и наследование
Мы уже стали экспертами по созданию и уничтожению объектов. Пора посмотреть, как можно их использовать. Взаимодействие с объектом заключается в основном в вызове его методов. (В некоторых языках это называется «отправлением сообщений объекту».) Определение метода напоминает определение обычной функции, единственное отличие в том, что определение метода находится внутри класса. Рассмотрим пример. Допустим, было решено создать приложение «Записная книжка», позволяющее сохранять и просматривать контактную информацию. Единицей записываемой и отображаемой информации в таком приложении служит виртуальная визитная карточка, которую можно реализовать в виде класса `Contact`. Кроме прочего можно определить в нем метод, возвращающий цвет фона отображаемой контактной информации:
```d
class Contact
{
string bgColor()
{
return "Серый";
}
}
unittest
{
auto c = new Contact;
assert(c.bgColor() == "Серый");
}
```
Самое интересное начнется, когда вы решите, что класс должен стать *наследником* другого класса. Например, какие-то контакты в записной книжке относятся к друзьям, и для них хотелось бы использовать другой цвет фона:
```d
class Friend : Contact
{
string currentBgColor = "Светло-зеленый";
string currentReminder;
override string bgColor()
{
return currentBgColor;
}
string reminder()
{
...
return currentReminder;
}
}
```
Объявленный с помощью записи `: Contact` (наследование от класса `Contact`), класс `Friend` будет содержать все, что есть в классе `Contact`, плюс собственное дополнительное состояние (поля `currentBgColor` и `currentReminder` в примере) и собственные методы (метод `reminder` в примере).
В таких случаях говорят, что класс `Friend` – это подкласс класса `Contact`, а класс `Contact` – суперкласс класса `Friend`. Благодаря применяемому механизму работы с подклассами можно использовать экземпляр класса `Friend` везде, где бы ни ожидался экземпляр класса `Contact`:
```d
unittest
{
Friend f = new Friend;
Contact c = f; // Подставить экземпляр класса Friend вместо экземпляра класса Contact
auto color = c.bgColor(); // Вызвать метод класса Friend
}
```
Если бы занявший место экземпляра класса `Contact` экземпляр класса `Friend` вел себя *в точности* так же, как и экземпляр ожидаемого класса, отпали бы все (или почти все) причины использовать класс `Friend`. Одно из основных средств, предоставляемых объектной технологией, – возможность классам-наследникам переопределять функции классов-предков и таким образом модульно настраивать поведение сущностей среды. Как можно догадаться, переопределение задается с помощью ключевого слова `override` (класс `Friend` переопределяет метод `bgColor`), которое обозначает, что вызов `c.bgColor()` (где вместо c ожидается объект типа `Contact`, но на самом деле используется объект типа `Friend`) всегда инициирует вызов версии метода, предлагаемой классом `Friend`. Друзья всегда остаются друзьями, даже если компилятор думает, что это обыкновенные контакты.
[Исходный код](src/chapter-6-4/)
[В начало ⮍](#6-4-методы-и-наследование) [Наверх ⮍](#6-классы-объектно-ориентированный-стиль)
### 6.4.1. Терминологический «шведский стол»
Технология ООП постоянно и успешно развивалась как в академическом, так и в практическом направлении. На это были затрачены большие усилия, в том числе изобретено великое множество терминов, которые порой сбивают с толку. Остановимся ненадолго и посмотрим на имеющуюся номенклатуру.
Если класс `D` является прямым наследником класса `B`, то `D` называют *подклассом* `B`, *дочерним классом* `B` или классом, *производным от* `B`. А класс `B` называют *суперклассом*, *родительским классом* (*родителем*) или *базовым классом* `D`.
Класс `X` считается потомком класса `B`, если и только если `X` является дочерним классом `B` или `X` является потомком дочернего класса `B`. Это рекурсивное определение означает, что если вы посмотрите на родителя `X`, а потом на родителя родителя `X` и так далее, то в тот или иной момент вы встретите `B`.
В этой книге повсеместно используются понятийные пары *родительский класс*/*дочерний класс* и *предок*/*потомок*, поскольку эти слова точнее отражают разницу между прямым и косвенным родством, чем пара терминов *суперкласс*/*подкласс*.
Странно, но несмотря на то что классы – это типы, подтип – это не то же самое, что и подкласс (а супертип – не то же самое, что и суперкласс). Подтип – это более широкое понятие: тип `S` является подтипом типа `T`, если значение типа `S` можно без какого-либо риска употреблять во всех контекстах, где ожидается значение типа `T`. Обратите внимание: в этом определении ничего не говорится о наследовании. И на самом деле, наследование – это лишь один из способов реализовать порождение подтипов; в общем случае есть и другие средства (в том числе в D). Отношение между порождением подтипов и наследованием можно охарактеризовать так: подтипами класса `C` являются потомки класса `C` плюс сам класс `C`. Подтип `C`, отличный от `C`, – это *собственный подтип* (*proper subtype*).
[В начало ⮍](#6-4-1-терминологический-шведский-стол) [Наверх ⮍](#6-классы-объектно-ориентированный-стиль)
### 6.4.2. Наследование – это порождение подтипа. Статический и динамический типы
Рассмотрим пример порождения подтипа наследованием. Как уже говорилось, экземпляр класса-потомка всегда может заменить экземпляр своего предка:
```d
class Contact { ... }
class Friend : Contact { ... }
void fun(Contact c) { ... }
unittest
{
auto c = new Contact; // c имеет тип Contact
fun(c);
auto f = new Friend; // f имеет тип Friend
fun(f);
}
```
Несмотря на то что функция `fun` ожидает экземпляр класса `Contact`, передача в качестве аргумента объекта `f` вполне допустима, так как класс `Friend` является подклассом (и, следовательно, подтипом) класса `Contact`.
Применяя механизм порождения подтипов, компилятор нередко отчасти «забывает» об истинном типе объекта. Например:
```d
class Contact { string bgColor() { return ""; } }
class Friend : Contact
{
override string bgColor() { return "Светло-зеленый"; }
}
unittest
{
Contact c = new Friend; // c имеет тип Contact, но на самом деле ссылается на экземпляр класса Friend
assert(c.bgColor() == "Светло-зеленый"); // Это действительно друг!
}
```
Учитывая, что переменная `c` имеет тип `Contact`, ее можно использовать только так, как может быть использован объект типа `Contact`, – даже если она привязана к объекту типа `Friend`. Например, нельзя вызвать `c.reminder`, поскольку этот метод специфичен для класса `Friend` и отсутствует в классе `Contact`. Тем не менее команда `assert` в примере показывает, что друзья всегда остаются друзьями: вызов `c.bgColor` доказывает, что вызывается метод класса `Friend`. Как было описано в разделе 6.3, после завершения построения объекта он становится вечным, так что экземпляр класса `Friend`, созданный с помощью оператора `new`, никогда никуда не исчезнет. Любопытная особенность, с которой мы столкнулись, состоит в том, что *ссылка* `c`, привязанная к нему, имеет тип `Contact`, а не `Friend`. В таких случаях говорят, что `c` обладает статическим типом `Contact` и динамическим типом `Friend`. Ни к чему не привязанная ссылка (`null`) не имеет динамического типа.
Отделить тип `Friend` от маски типа `Contact`, за которой он скрывается, – или в общем случае потомка от предка – задача посложнее. Есть одно но: операция может закончиться неудачей. Что если на самом деле контакт не ссылается на экземпляр класса `Friend`? В большинстве случаев компилятор не сможет сказать, так это или нет. Выполнить такое извлечение поручим оператору `cast`:
```d
unittest
{
auto c = new Contact; // Статический и динамический типы переменной с совпадают. Это Contact
auto f = cast(Friend) c;
assert(f is null); // Переменная f имеет статический тип Friend и ни к чему не привязана
c = new Friend; // Статический: Contact, динамический: Friend
f = cast(Friend) c; // Статический: Friend, динамический: Friend
assert(f !is null); // Есть!
}
```
[В начало ⮍](#6-4-2-наследование-это-порождение-подтипа-статический-и-динамический-типы) [Наверх ⮍](#6-классы-объектно-ориентированный-стиль)
### 6.4.3. Переопределение – только по желанию
Ключевое слово `override` – это обязательная часть сигнатуры метода `Friend.bgColor`. Поначалу это может немного раздражать. В конце концов компилятор мог бы сам понять, что выполняется переопределение, и соответствующим образом все увязать. Зачем обязательно писать `override`?
Ответ связан с сопровождением кода. Компилятору на самом деле ничего не стоит автоматически выяснить, какие методы вы пожелали переопределить. Проблема в том, что он не может определить, какие методы вы *не* хотели переопределять. Такая ситуация может возникнуть, когда вы решаете изменить класс-предок уже после того, как определили класс-потомок. Представьте, например, что изначально в классе `Contact` определен только метод `bgColor`. Вы производите от него класс `Friend` и переопределяете метод `bgColor`, как это показано в предыдущем фрагменте кода. Вы также можете определить в классе `Friend` и другой метод, например метод `Friend.reminder`, позволяющий извлекать напоминания о некотором конкретном друге. Если позже кто-то еще (или вы сами спустя три месяца) определит метод `reminder` для класса `Contact` с иным смыслом, то получит странную неполадку: вызовы, адресованные методу `Contact.reminder`, будут перенаправляться методу `Friend.reminder` независимо от того, кому они адресованы, классу `Contact` или классу `Friend`, – класс `Friend` к этому явно не готов.
Обратная ситуация, по крайней мере, настолько же пагубна. Скажем, мы поменяли свои планы и решили удалить или переименовать один из методов класса `Contact`. Разработчику придется вручную пройти всех потомков класса `Contact` и решить, что делать с осиротевшими методами. Такие действия почти всегда приводят к ошибкам, и иногда их просто невозможно выполнить во всей полноте, поскольку разные части иерархии классов могут писать разные разработчики.
Таким образом, требование писать `override` позволяет модифицировать классы-предки без риска неожиданно навредить классам-потомкам.
[В начало ⮍](#6-4-3-переопределение-только-по-желанию) [Наверх ⮍](#6-классы-объектно-ориентированный-стиль)
### 6.4.4. Вызов переопределенных методов
Иногда метод, перекрывший другой метод, хочет вызвать как раз именно его. Рассмотрим, например, графический виджет `Button`, наследник класса `Clickable`. Класс `Clickable` знает, как рассылать сообщения о нажатиях кнопки объектам-слушателям, но совершенно не в курсе относительно каких-либо графических эффектов. Чтобы обеспечить визуальную реакцию на клик, класс `Button` переопределяет метод `onClick`, определенный в классе `Clickable`, задает код, реализующий все необходимое для визуального эффекта, и желает вызвать метод `Clickable.onClick`, который выполнил бы все, что касается рассылки сообщений.
```d
class Clickable
{
void onClick() { ... }
}
class Button : Clickable
{
void drawClicked() { ... }
override void onClick()
{
drawClicked(); // Реализует графический эффект
super.onClick(); // Рассылает слушателям сообщение о нажатии кнопки
}
}
```
Вызвать метод, который был переопределен, можно с помощью встроенного псевдонима `super`, предписывающего компилятору обратиться к ранее определенному методу родительского класса. Таким способом можно вызвать любой метод – необязательно переопределенный в классе, откуда делается вызов (например, в методе `Button.onClick` можно сделать вызов вида `super.onDoubleClick`). Если честно, идентификатор, к которому вы обращаетесь, даже не обязан быть именем метода. С таким же успехом это может быть имя поля и вообще любой другой идентификатор. Например:
```d
class Base
{
double number = 5.5;
}
class Derived : Base
{
int number = 10;
double fun()
{
return number + super.number;
}
}
```
Метод `Derived.fun` обращается к собственному полю, а также к полю родительского класса, которое по стечению обстоятельств имеет другой тип.
Формат `Имякласса.имячленакласса`, служит для обращений ко внутренним элементам не только родительского класса, но и любого предка. На самом деле, ключевое слово `super` – не что иное, как псевдоним, замещающий имя текущего класса-родителя. В предыдущем примере совершенно безразлично, что написать: `Base.number` или `super.number`. Очевидная разница лишь в том, что ключевое слово `super` помогает создать код, который легче сопровождать: если родительский класс изменится, то вам не потребуется искать обращения к нему и заменять старое имя на новое.
Используя имена классов явно, можно прыгнуть вверх по иерархии наследования больше чем на один уровень. Уточнение имени метода с помощью ключевого слова `super` или имени класса ускоряет обращение к этому методу, поскольку дает компилятору точную информацию о том, какой функции нужно передать управление. Если адресуемый идентификатор не является именем переопределенного метода, на скорость такое уточнение никак не повлияет, только на область видимости.
Несмотря на то что деструкторы (см. раздел 6.3.4) – это всего лишь методы, у обработки вызова деструктора есть особенности. Нельзя явно вызвать деструктор родителя, однако при вызове деструктора текущего класса (или во время цикла сбора мусора, или в результате вызова `clear(obj)`) библиотека D поддержки во время выполнения всегда вызывает все деструкторы вверх по иерархии.
[В начало ⮍](#6-4-4-вызов-переопределенных-методов) [Наверх ⮍](#6-классы-объектно-ориентированный-стиль)
### 6.4.5. Ковариантные возвращаемые типы
Продолжим пример с классами `Widget`, `TextWidget` и `VisibleWidget`. Предположим, вы хотите добавить код, порождающий копию экземпляра класса `Widget`. Если дублируемый объект является экземпляром класса `Widget`, копия также должна быть экземпляром класса `Widget`, если дублируемый объект – экземпляр класса `TextWidget`, то копия также экземпляр класса `TextWidget` и т. д. Для корректного копирования можно определить в родительском классе метод `duplicate` и потребовать, чтобы каждый класс-потомок тоже реализовал метод с таким именем:
```d
class Widget
{
...
this(Widget source)
{
... // Скопировать состояние
}
Widget duplicate()
{
return new Widget(this); // Выделяет память и вызывает this(Widget)
}
}
```
Пока все идет хорошо. Теперь посмотрим на соответствующее переопределение в классе `TextWidget`:
```d
class TextWidget : Widget
{
...
this(TextWidget source)
{
super(source);
... // Скопировать состояние
}
override Widget duplicate()
{
return new TextWidget(this);
}
}
```
Все корректно, но заметна потеря статической информации: метод `TextWidget.duplicate` на самом деле возвращает экземпляр класса `Widget`, а не экземпляр класса `TextWidget`. Однако если заглянуть *внутрь* функции `TextWidget.duplicate`, то можно увидеть, что она возвращает `TextWidget`. Тем не менее эта информация теряется, как только `TextWidget.duplicate` возвращает результат, поскольку возвращаемым типом этого метода является тип `Widget` – тот же, что и у метода `Widget.duplicate`. Поэтому следующий код не работает (хотя в идеале должен бы работать):
```d
void workWith(TextWidget tw)
{
TextWidget clone = tw.duplicate(); // Ошибка! Нельзя преобразовать экземпляр класса Widget в экземпляр класса TextWidget!
...
}
```
Чтобы максимизировать количество доступной статической информации о типах, D вводит средство, известное как *ковариантные возвращаемые типы*. Звучит довольно громко, но смысл ковариантности возвращаемых типов довольно прост: если родительский класс возвращает некоторый тип `C`, то переопределенной функции разрешается возвращать не только `C`, но и любого потомка `C`. Благодаря этому средству можно позволить методу `TextWidget.duplicate` возвращать `TextWidget`. Не менее важно, что теперь вы можете прибавить себе веса в дискуссии, вставив при случае фразу «ковариантные возвращаемые типы». (Шутка. Если серьезно, даже не пытайтесь.)
[Исходный код](src/chapter-6-4-5/)
[В начало ⮍](#6-4-5-ковариантные-возвращаемые-типы) [Наверх ⮍](#6-классы-объектно-ориентированный-стиль)
## 6.5. Инкапсуляция на уровне классов с помощью статических членов
Иногда бывает полезно инкапсулировать в классе не только поля и методы, но и обычные функции, и (вот это да!) глобальные данные. Такие функции и данные не имеют какого-либо особого предназначения, кроме создания контекста внутри класса. Чтобы сделать обычные функции и данные разделяемыми между всеми объектами класса, определите их с ключевым словом `static`:
```d
class Widget
{
static Color defaultBgColor;
static Color combineBackgrounds(Widget bottom, Widget top)
{
...
}
}
```
Внутри статических методов нельзя использовать ссылку `this`. Это также объясняется тем, что статические методы – всего лишь обычные функции, определенные внутри класса. Логически из этого следует, что для получения доступа к данным `defaultBgColor` или к функции `combineBackgrounds` не нужен никакой объект – достаточно только имени класса:
```d
unittest
{
auto w1 = new Widget, w2 = new Widget;
auto c = Widget.defaultBgColor;
// Сработает и так: w1.defaultBgColor;
c = Widget.combineBackgrounds(w1, w2);
// Сработает и так: w2.combineBackgrounds(w1, w2);
}
```
Также вполне корректно обращаться к статическим внутренним элементам класса по имени объекта, а не класса. Обратите внимание: значение объекта будет вычислено в любом случае, даже когда на самом деле в этом нет необходимости.
```d
// Создает экземпляр класса Widget и тут же выбрасывает полученный объект
auto c = (new Widget).defaultBgColor;
```
[В начало ⮍](#6-5-инкапсуляция-на-уровне-классов-с-помощью-статических-членов) [Наверх ⮍](#6-классы-объектно-ориентированный-стиль)
## 6.6. Сдерживание расширяемости с помощью финальных методов
Иногда бывает нужно запретить подклассам переопределять некоторый метод. Это обычная практика, поскольку методы определяются не для того, чтобы служить лазейками для внесения изменений. В отдельных случаях требуется поддерживать определенные потоки управления
в четко заданном состоянии. (Вспоминается шаблон проектирования «Шаблонный метод».) Чтобы запретить классам-наследникам переопределять метод, определите его с ключевым словом `final`.
Рассмотрим пример приложения-тикера, формирующего биржевые сводки. Ему необходимо гарантировать своевременное обновление информации на экране при изменении котировок:
```d
class StockTicker
{
final void updatePrice(double last)
{
doUpdatePrice(last);
refreshDisplay();
}
void doUpdatePrice(double last) { ... }
void refreshDisplay() { ... }
}
```
Методы `doUpdatePrice` и `refreshDisplay` переопределяемы, а значит, могут быть изменены подклассами класса `StockTicker`. Например, некоторые тикеры могут определять триггеры и уведомления, срабатывающие только при заданных изменениях котировок, или отображать себя особым цветом. А вот метод `updatePrice` переопределить нельзя, поэтому инициатор вызова может быть уверен, что при обновлении котировки она обновится и на экране. На самом деле, как истинные борцы за корректность, мы должны определить метод `updatePrice` так:
```d
final void updatePrice(double last)
{
scope(exit) refreshDisplay();
doUpdatePrice(last);
}
```
Благодаря конструкции `scope(exit)` информация на экране обновится корректно, даже если при выполнении метода `doUpdatePrice` возникнет исключение. Такой подход реально гарантирует, что устройство вывода отображает самое свежее и корректное состояние объекта.
У финальных методов есть опасное преимущество, способное легко увлечь вас на темную сторону преждевременной оптимизации. Истина в том, что финальные методы могут быть эффективнее других, потому что при каждом вызове нефинальных методов делается один косвенный шаг, который гарантирует гибкость, обещанную ключевым словом `override`. Правда, некоторым финальным методам этот шаг также необходим. Например, если вызов финального переопределенного метода инициируется из класса-родителя, он обычно также подвержен косвенным вызовам; в общем случае компилятор по-прежнему не будет знать, куда пойдет вызов. Но если финальный метод определен впервые (а не переопределяет метод родительского класса), то когда бы вы его ни вызвали, компилятор будет на 100% уверен в том, куда «приземлится» вызов. Так что финальные методы, которые ничего не переопределяют, никогда не подвергаются косвенным вызовам; напротив, они наслаждаются теми же правилами вызова, низкими накладными расходами и возможностями инлайнинга, что и обычные функции. Может показаться, что финальные непереопределяющие методы гораздо быстрее остальных, но это преимущество нивелируют два фактора.
Во-первых, накладные расходы, связанные с вызовом из родительского класса, оцениваются в контексте функции, которая ничего не делает. Но чтобы оценить накладные расходы, которые что-то значат, кроме накладных расходов на инициирование выполнения нужно учитывать время, затрачиваемое на само выполнение кода внутри функции. Если функция короткая, относительные накладные расходы могут быть значительными, но чем более нетривиальным делом занимается функция, тем быстрее уменьшаются относительные накладные расходы, практически сходя на нет. Во-вторых, есть множество техник оптимизации работы компилятора, сборщика и библиотеки поддержки времени исполнения, эффективно работающих на минимизацию и полное уничтожение накладных расходов диспетчирования. Без сомнений, гораздо удобнее начать с гибкого кода, оптимизируя очень умеренно, а не сразу наделять методы чрезмерной строгостью, ограничивающей их возможности, ради потенциального быстродействия в отдаленном будущем.
Если вы работали c языками Java или C#, то немедленно узнаете в ключевом слове `final` старого знакомого, поскольку в D оно обладает той же семантикой, что и в этих языках. Если сравнить положение дел с C++, то можно обнаружить любопытную смену настроек по умолчанию: в C++ методы являются финальными по умолчанию (и не нужно специально что-то указывать, чтобы запретить наследование) и переопределяемыми, если явно пометить их ключевым словом `virtual`. Подчеркнем еще раз: по крайней мере в этом случае было решено предпочесть умолчания, ориентированные на гибкость. Скорее всего, вы будете использовать финальные методы в основном для реализации структурных решений и только иногда – чтобы избавиться от нескольких дополнительных циклов процессора.
[В начало ⮍](#6-6-сдерживание-расширяемости-с-помощью-финальных-методов) [Наверх ⮍](#6-классы-объектно-ориентированный-стиль)
### 6.6.1. Финальные классы
Иногда требуется, чтобы класс «закрыл тему». Для этого можно пометить ключевым словом `final` целый класс:
```d
class Widget { ... }
final class UltimateWidget : Widget { ... }
class PostUltimateWidget : UltimateWidget { ... } // Ошибка! Нельзя стать наследником финального класса
```
От финального класса нельзя наследовать – в иерархии наследования он является листом. Иногда это может оказаться важным средством разработки. Очевидно, что все методы финального класса также неявно объявляются как финальные: их никогда нельзя будет переопределить.
Любопытный побочный эффект финальных классов – твердые гарантии реализации. Клиентский код, использующий финальный класс, может быть уверен, что методы этого класса обладают известными реализациями с гарантированным действием, которое не может быть модифицировано никаким подклассом.
[В начало ⮍](#6-6-1-финальные-классы) [Наверх ⮍](#6-классы-объектно-ориентированный-стиль)
## 6.7. Инкапсуляция
Одна из характерных черт объектно-ориентированной, да и других техник разработки – *инкапсуляция*. Объект инкапсулирует детали своей реализации, выставляя напоказ лишь тщательно выверенный интерфейс. Таким способом объекты закрепляют за собой свободу изменять множество деталей своей реализации без угрозы для работоспособности клиентского кода. Это позволяет уменьшить количество связей в коде и, следовательно, количество зависимостей, подтверждая знаменитую истину: каждая техника разработки в конечном счете стремится облегчить управление зависимостями.
В то же время инкапсуляция – это проявление принципа *сокрытия информации* (*information hiding*), одного из основных для разработки программного обеспечения. Этот принцип гласит, что множество логически обособленных частей приложения должны определять и использовать для взаимодействия друг с другом абстрактные интерфейсы, скрывая детали их реализации. Обычно эти детали касаются структур данных, поэтому распространено понятие «сокрытие данных» (data hiding). Тем не менее сокрытие данных – лишь частный случай сокрытия информации, поскольку компонент может скрывать множество разнообразной информации, в том числе структурные решения и алгоритмические стратегии.
Сегодня инкапсуляция кажется благом, практически несомненным, но во многом такое отношение – результат накопленного коллективного опыта. Раньше все было не столь ясно и однозначно. В конце концов информация – вроде бы хорошая вещь, чем ее больше – тем лучше. С какой стати ее прятать?
Отмотаем пленку назад. В 1960-х Фред Брукс, автор основополагающей книги «Мифический человеко-месяц»[^7], выступал в поддержку прозрачного («белый ящик») подхода к разработке программного обеспечения под девизом «все знают всё». Под его руководством команда, работающая над операционной системой OS/360, регулярно получала документацию со сведениями обо всех деталях проекта благодаря замысловатой методике, основанной на печати документирующих комментариев. Проект был довольно успешным, но вряд ли можно утверждать, что прозрачность сыграла в этом серьезную роль; гораздо более правдоподобно то, что эта прозрачность была риском, минимизированным за счет усиленного управления. Окончательно причислить сокрытие информации к непререкаемым принципам сообщества программистов помогло только появление революционного сочинения Дэвида Парнаса. В 1995 году Брукс сам отметил, что его пропаганда прозрачности – единственное в «Мифическом человеко-месяце», что не прошло проверку временем. Но в 1972 году мысль о сокрытии информации вызывала полемику, о чем свидетельствует отзыв рецензента революционного сочинения Парнаса: «Очевидно, что Парнас не знает, о чем говорит, потому что никто так не делает». Довольно забавно, что десяток лет спустя положение дел изменилось настолько радикально, что то же сочинение стало почти банальностью: «Парнас лишь записал то, что и так делали все хорошие программисты».
Вернемся к инкапсуляции в контексте языка D. Любые тип, данные, функцию или метод можно определить с одним из следующих пяти спецификаторов. Начнем с самого закрытого спецификатора и постепенно дойдем до полной гласности.
[В начало ⮍](#6-7-инкапсуляция) [Наверх ⮍](#6-классы-объектно-ориентированный-стиль)
### 6.7.1. private
Спецификатор доступа `private` можно указывать на уровне класса, за пределами классов (на уровне модуля) или внутри структуры (см. главу 7). Во всех контекстах ключевое слово `private` действует одинаково – ограничивает доступ к идентификатору до текущего модуля (файла).
В других языках такой синтаксис имеет другую семантику: обычно доступ к закрытым идентификаторам ограничивают лишь до текущего класса. Тем не менее то, что спецификатор `private` ограничивает доступ до уровня модуля, прекрасно согласуется с общим подходом D к защите: все защищаемые единицы соответствуют защищаемым единицам операционной системы (файлу и каталогу). Преимущество защиты на уровне файла в том, что она способствует объединению маленьких тесно взаимосвязанных сущностей, обладающих определенными обязанностями. Если требуется защита на уровне класса, просто выделите ему собственный файл.
[В начало ⮍](#6-7-1-private) [Наверх ⮍](#6-классы-объектно-ориентированный-стиль)
### 6.7.2. package
Спецификатор доступа `package` можно указывать на уровне класса, за пределами классов (на уровне модуля) и внутри структуры (см. главу 7). Во всех контекстах ключевое слово `package` действует одинаково: доступ к идентификатору, определенному с этим ключевым словом, предоставляется всем файлам в том же каталоге, где находится и текущий модуль. Родительский каталог и подкаталоги каталога текущего модуля не обладают никакими особыми привилегиями.
[В начало ⮍](#6-7-2-package) [Наверх ⮍](#6-классы-объектно-ориентированный-стиль)
### 6.7.3. protected
Спецификатор доступа `protected` имеет смысл только внутри класса, но не на уровне модуля. При использовании внутри некоторого класса C этот спецификатор доступа означает, что доступ к объявленному идентификатору сохраняется за модулем, в котором определен класс С, а также за всеми потомками класса C независимо от того, в каком модуле они находятся. Например:
```d
class C
{
// Поле x доступно только в этом файле
private int x;
// Этот файл и все прямые и косвенные наследники класса C могут вызвать метод setX()
protected void setX(int x) { this.x = x; }
// Кто угодно может вызвать метод getX()
public int getX() { return x; }
}
```
И снова отметим, что право доступа, предоставляемое спецификатором доступа `protected`, транзитивно: оно переходит не только собственно к дочерним классам, но и ко всем поколениям потомков, наследующих от класса, определенного с ключевым словом `protected`. Это делает спецификатор доступа `protected` довольно щедрым в плане предоставления доступа.
[В начало ⮍](#6-7-3-protected) [Наверх ⮍](#6-классы-объектно-ориентированный-стиль)
### 6.7.4. public
Общедоступный уровень доступа `public` означает, что к объявленному таким способом идентификатору можно свободно обращаться из любого места в приложении. Все, что должно для этого сделать приложение, – поместить нужный идентификатор в свою область видимости (как правило, это делается с помощью импорта модуля, в котором объявлен данный идентификатор).
В языке D `public` – это также уровень доступа, который присваивается всем объектам по умолчанию. Поскольку порядок объявлений на компиляцию не влияет, хорошим тоном будет расположить видимые интерфейсы модуля или класса в начале файла, а затем ограничить доступ, применив (например) спецификатор доступа `private`, после чего можно разместить другие определения. Если придерживаться такой стратегии, клиенту будет достаточно посмотреть в начало файла или класса, чтобы узнать все о его доступных сущностях.
[В начало ⮍](#6-7-4-public) [Наверх ⮍](#6-классы-объектно-ориентированный-стиль)
### 6.7.5. export
Казалось бы, спецификатор доступа `public` – наименее закрытый из уровней доступа, самый щедрый из них. Тем не менее D определяет уровень доступа, разрешающий еще больше: `export`. Идентификатор, определенный с ключевым словом `export`, становится доступным даже *вне* программы, в которой он был определен. Это случай разделяемых библиотек, выставляющих всему миру напоказ свои интерфейсы. Компилятор выполняет зависящие от системы шаги, необходимые для экспорта идентификатора, часто включая и особые соглашения об именовании символов. Пока что в D не определена сложная инфраструктура динамической загрузки, так что спецификатор доступа `export` выполняет роль заглушки в ожидании более обширной поддержки.
[В начало ⮍](#6-7-5-export) [Наверх ⮍](#6-классы-объектно-ориентированный-стиль)
### 6.7.6. Сколько инкапсуляции?
Логичный и интересный вопрос: «Как сравнить пять определенных в D уровней доступа?» Например, мы только что согласились, что скрывать информацию – хорошо, и резонно было бы считать, что уровень доступа `private` «лучше», чем `protected`, поскольку у первого больше ограничений. Далее, по той же логике `protected` лучше, чем `public` (еще бы – `public` довольно низко опускает планку, про `export` можно и не говорить). При этом неясно, как сравнить `protected` и `package`. А главное, такой «качественный» анализ даже не намекает на то, какие потери понесет разработчик, решивший, к примеру, смягчить ограничения для идентификатора. К чему ближе спецификатор доступа `protected` – к `private` или `public`? Или он ровно посередине шкалы? И что это за шкала в конце концов?
Давным-давно, в декабре 1999 года, когда всех волновала лишь проблема 2000 года, Скотта Мейерса волновала инкапсуляция, точнее методы программирования, позволяющие ее максимизировать. Результатом его исследований стала статья, в которой Мейерс предложил простой критерий для оценки «степени инкапсуляции» сущности: если мы изменим сущность, сколько кода затронут наши изменения? Чем меньше кода будет затронуто, тем большая степень инкапсуляции достигнута.
Понимание смысла измерения степени инкапсуляции многое проясняет. В отсутствие системы измерения о спецификаторах доступа обычно судят так: `«private` – хорошо, `public` – плохо, а `protected` – нечто среднее между ними». Человек по своей природе оптимист, поэтому уровень защиты, предоставляемый спецификатором доступа `protected`, многие оценивали как «хороший в известных пределах», а-ля «умеренно пьющий».
Другой аспект, который можно использовать для оценки степени инкапсуляции, – это *контроль*, то есть ваше влияние на код, в который вносятся изменения. Знаете ли вы (или: легко ли вы отыщете) код, на котором отразятся изменения? Обладаете ли вы правами на изменение этого кода? Может ли кто-то еще добавлять в него что-то? Ответы на эти вопросы определяют степень вашего контроля над кодом.
Для начала рассмотрим спецификатор доступа `private`. Изменение закрытого идентификатора затрагивает ровно один файл. Обычный размер исходного кода – примерно тысяча строк, нередко встречаются файлы и меньшего размера; более объемные файлы (скажем, в 10 000 строк) труднее сопровождать. Поскольку вы изменяете только один файл, можно сделать вывод, что вы обладаете над ним полным контролем и легко ограничите доступ к нему для других людей с помощью его атрибутов, системы управления версиями или стандартов кодирования, принятых в команде. Итак, спецификатор доступа `private` предоставляет блестящую инкапсуляцию: изменения затрагивают небольшое количество кода, при этом степень вашего контроля над кодом достаточно высока. При использовании спецификатора доступа `package` изменения затронут все файлы в том же каталоге. Можно прикинуть, что объем содержимого файлов, объединенных в пакет, составит примерно на порядок больше строк (например, разумно считать, что пакет включает примерно десять модулей). Соответственно изменять символы пакета недешево: изменения затронут код на порядок большего размера, чем при аналогичных изменениях `private`-идентификаторов. К счастью, у вас все еще хороший контроль над кодом, на котором отразятся изменения, поскольку опять же операционная система и разнообразные инструменты управления версиями предоставляют контроль над добавлением и изменением файлов на уровне каталога.
К сожалению, «защищенный» спецификатор доступа `protected` предоставляет гораздо меньшую защиту, чем обещает его название. Во-первых, со спецификатора `protected` начинается ощутимое расширение границ доступа, определяемых спецификаторами `private` и `package`: любой класс, расположенный где угодно в программе, может получить доступ к защищенному идентификатору, просто создав потомок класса, определяющего этот идентификатор. У вас же из средств «мелкодисперсного» контроля за наследованием – только атрибут `final` с девизом «всё или ничего». Из этого следует, что изменив защищенный идентификатор, вы повлияете на неограниченное количество кода. Усугубляет ситуацию то, что вы не только не можете ограничить тех, кто наследует от вашего класса, но еще и можете испортить код, на исправление которого у вас нет прав. (Например, изменение идентификатора библиотеки повлияет на все использующие ее приложения.) Реальность становится столь же мрачной, сколь и хрупкой: начав изменять что-то помимо `private` и `package`, вы открыты всем ветрам. В «защищенном» режиме доступа `protected` вы практически беззащитны.
Сколько кода придется просмотреть при изменении защищенного идентификатора? Всех наследников класса, в котором этот идентификатор определен. Разумная приблизительная оценка – на порядок больше размера пакета, то есть несколько сотен тысяч строк. Здесь, конечно, очень помогут инструменты, индексирующие исходный код и отслеживающие наследников классов, но, что ни говори, изменение защищенного символа может затронуть огромные объемы кода.
Со спецификатором доступа `public` вы не заметите ощутимых перемен в контроле, но зато обнаружите, что затрагиваемый код вырос еще на порядок. Теперь это не только потомки классов, но и весь остальной код приложения. Наконец, спецификатор доступа `export` добавляет к сюжету еще один интересный поворот: изменяя экспортируемые идентификаторы, вы рискуете повлиять на все бинарные приложения, использующие ваш код как бинарную библиотеку, так что вы не просто смотрите на код, который не можете исправить, – это код, который нельзя даже увидеть, потому что он может быть недоступен в исходном виде.
На рис. 6.3 эти приблизительные оценки изображены в виде графика зависимости числа потенциально затронутых строк кода от каждого спецификатора доступа. Конечно, эти числа лишь ориентировочные, на практике значения могут варьироваться в широких пределах, но основные пропорции вряд ли сильно изменятся. Шкала вертикальной оси – логарифмическая, ступени роста обозначают линейный рост, так что снизив защиту доступа всего на йоту, вы будете работать примерно в десять раз усерднее, чтобы синхронизировать все части кода. Стрелки вверх означают потерю контроля над затронутым кодом. Один из выводов заключается в том, что `protected` находится не ровно посередине между `private` и `public`, а гораздо ближе к `public`, и относиться к нему нужно так же (то есть с животным страхом).
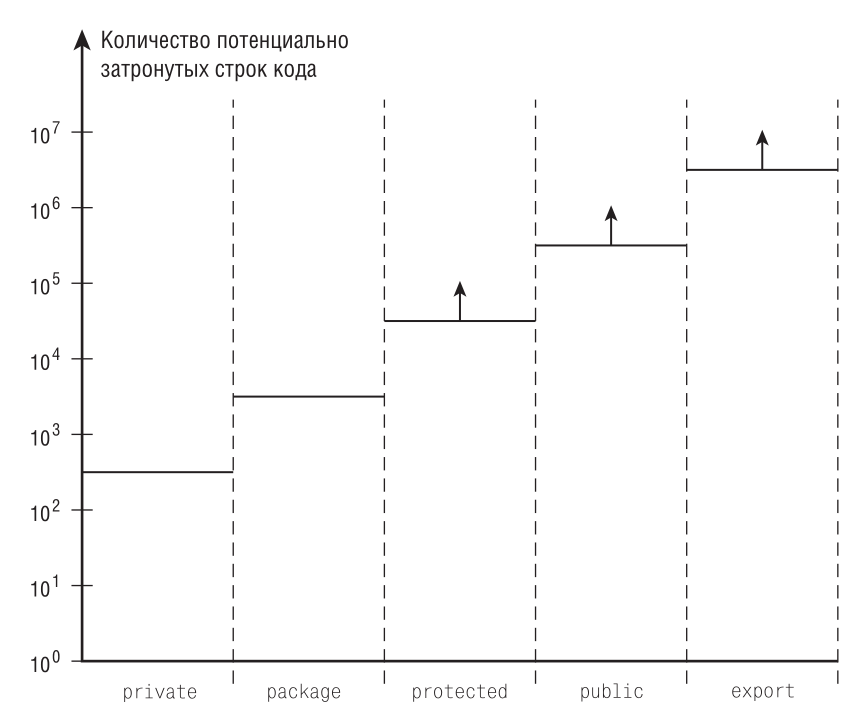
***Рис. 6.3.*** *Приблизительные оценки количества строк кода, которые может затронуть изменение идентификатора с соответствующим спецификатором доступа. Вертикальная ось – логарифмическая, так что каждый шаг ослабления инкапсуляции на порядок ухудшает положение дел. Стрелки вверх означают, что количество кода, затронутого при уровне защиты `protected`, `public` и `export`, неподвластно программисту, изменившему идентификатор*
[В начало ⮍](#6-7-6-сколько-инкапсуляции) [Наверх ⮍](#6-классы-объектно-ориентированный-стиль)
## 6.8. Основа безраздельной власти
В языке D, как и в некоторых других языках, определен корневой класс для всех остальных классов. Всеобщий корень называется `Object`. Когда вы определяете класс, например так:
```d
class C
{
...
}
```
компилятор распознает это как:
```d
class C : Object
{
...
}
```
Кроме этой автоматической перезаписи класс `Object` ничем не примечателен – он такой же, как все остальные классы. Ваша реализация определяет его в модуле `object.di` или `object.d`, автоматически включаемом в каждый модуль, который вы компилируете. Просмотрев каталог, где находится ваша реализация D, вы легко обнаружите этот модуль и убедитесь, что он содержит корневой объект.
Определение общего прародителя для всех классов имеет ряд положительных следствий. Очевидное благо – то, что класс `Object` может объявлять ряд повсеместно полезных методов. Вот немного упрощенное определение класса `Object`:
```d
class Object
{
string toString();
size_t toHash();
bool opEquals(Object rhs);
int opCmp(Object rhs);
static Object factory(string classname);
}
```
Познакомимся поближе с семантикой каждого из этих идентификаторов.
[В начало ⮍](#6-8-основа-безраздельной-власти) [Наверх ⮍](#6-классы-объектно-ориентированный-стиль)
### 6.8.1. string toString()
Этот метод возвращает текстовое представление объекта. По умолчанию метод `toString` возвращает имя класса:
```d
// Файл test.d
class Widget {}
unittest
{
assert((new Widget).toString() == "test.Widget");
}
```
Обратите внимание: вместе с именем класса возвращено и имя модуля, в котором класс был определен. По умолчанию модуль получает имя файла, в котором он расположен, но это умолчание можно изменить с помощью объявления с ключевым словом `module` (см. раздел 11.8).
[Исходный код](src/chapter-6-8-1/)
[В начало ⮍](#6-8-1-string-tostring) [Наверх ⮍](#6-классы-объектно-ориентированный-стиль)
### 6.8.2. size_t toHash()
Этот метод возвращает хеш объекта в виде целого числа без знака (размером в 32 разряда на 32-разрядной машине и в 64 разряда на 64-разрядной). По умолчанию хеш-сумма вычисляется на основе поразрядного представления объекта. Хеш является сжатым, но неточным представлением объекта. Одно из важных требований к функции, вычисляющей хеш-сумму, – *постоянство*: если метод `toHash` дважды вызывается с одной и той же ссылкой и между двумя вызовами объект, к которому привязана эта ссылка, не был изменен, то значения, возвращенные при первом и втором вызове, должны совпадать. Кроме того, хеш-коды двух одинаковых объектов тоже должны быть одинаковыми. А хеш-коды двух различных («неравных») объектов вряд ли будут равны. В следующем разделе подробно определено понятие равенства объектов.
[В начало ⮍](#6-8-2-size_t-tohash) [Наверх ⮍](#6-классы-объектно-ориентированный-стиль)
### 6.8.3. bool opEquals(Object rhs)
Этот метод возвращает `true`, если объект `this` сочтет, что значение `rhs`[^8] ему равно. Это намеренно странная формулировка. Эксперимент с аналогичной функцией `equals` из языка Java показал, что если есть наследование, то определить равенство объектов не так просто. Поэтому D подходит к этому вопросу достаточно своеобразно.
Начнем с того, что у нас уже есть одно определение равенства объектов: выражение `a1 is a2` (см. раздел 2.3.4.3), сравнивающее ссылки на объекты классов `a1` и `a2`, истинно тогда и только тогда, когда `a1` и `a2` ссылаются на один и тот же объект (см. рис. 6.1). Это разумное определение равенства объектов, но чересчур строгое, чтобы быть полезным. Обычно требуется, чтобы два физически разных объекта считались равными, если они находятся в одинаковых состояниях. В языке D логическое равенство вычисляется с помощью операторов `==` и `!=`. Вот как они работают.
Допустим, для выражений `‹lhs›` и `‹rhs›` можно записать: `‹lhs› == ‹rhs›`. Тогда если хотя бы одно из них имеет пользовательский тип, компилятор переписывает сравнение в виде `object.opEquals(‹lhs›, ‹rhs›)`. Аналогично сравнение `‹lhs› != ‹rhs›` заменяется на `!object.opEquals(‹lhs›, ‹rhs›)`. Вспомните, чуть выше уже говорилось, что `object` – стандартный модуль, определенный реализацией D и неявно включаемый с помощью инструкции import во все модули вашей сборки. Так что сравнения превращаются в вызовы свободной функции, предоставляемой вашей реализацией и расположенной в модуле `object`.
От отношения равенства ожидается подчинение определенным инвариантам, и выражение `object.opEquals(‹lhs›, ‹rhs›)` проходит долгий путь, доказывая свою корректность. Во-первых, сравнение пустых ссылок (`null`) должно возвращать `true`. Далее, для любых трех непустых ссылок `x`, `y`, `z` должны успешно выполняться следующие проверки:
```d
// Ссылка null уникальна; непустая ссылка не может быть равна null
assert(x != null);
// Рефлексивность
assert(x == x);
// Симметричность
assert((x == y) == (y == x));
// Транзитивность
if (x == y && y == z) assert(x == z);
// Отношение с toHash
if (x == y) assert(x.toHash() == y.toHash());
```
Более тонкое требованиее к методу `opEquals` – *постоянство*: вычисление равенства дважды с одними и теми же ссылками должно возвращать один и тот же результат, при условии что между первым и вторым вызовом `opEquals` объекты, к которым привязаны данные ссылки, не изменялись.
Типичная реализация `object.opEquals` сначала исключает некоторые простые или вырожденные случаи, а затем открывает дорогу конкретным версиям `opEquals`, определенным для типов выражений, участвующих в сравнении. Вот как может выглядеть `object.opEquals`:
```d
// В системном модуле object.d
bool opEquals(Object lhs, Object rhs)
{
// Если это псевдонимы одного и того же объекта
// или пустые ссылки, то они равны
if (lhs is rhs) return true;
// Если только один аргумент равен null, то не равны
if (lhs is null || rhs is null) return false;
// Если типы в точности совпадают, то вызываем метод opEquals один раз
if (typeid(lhs) == typeid(rhs)) return lhs.opEquals(rhs);
// В общем случае – симметричные вызовы метода opEquals
return lhs.opEquals(rhs) && rhs.opEquals(lhs);
}
```
Во-первых, если две ссылки ссылаются на один и тот же объект или обе пустые, то, как и можно было ожидать, результат – `true` (гарантируется рефлексивность). Далее, если установлено, что объекты индивидуальны, и если один из них равен `null`, сравнение возвращает `false` (гарантируется исключительность пустой ссылки `null`). Третья проверка устанавливает, имеют ли объекты один и тот же тип; если да, то системная функция поручает вычислить результат сравнения выражению `lhs.opEquals(rhs)`. И самый интересный момент: двойное вычисление в последней строке. Почему одного вызова недостаточно?
Вспомните изначальное, немного сложное для понимания описание метода `opEquals`: «возвращает `true`, если объект `this` сочтет, что значение `rhs` ему равно». Это определение заботится лишь о `this`, но не принимает во внимание мнение, которое может быть у `rhs`. Для достижения взаимного согласия необходимо рукопожатие – каждый из двух объектов должен утвердительно ответить на вопрос: «Считаете ли вы, что этот объект вам равен?» Может показаться, что разногласия относительно равенства – это лишь академическая проблема, но они довольно-таки часто возникают там, где на сцену выходит наследование. Впервые об этом заговорил Джошуа Блох (Joshua Bloch) в своей книге «Effective Java», а продолжил тему Тал Коэн (Tal Cohen) в своей статье. Попробуем проследить эту полемическую цепь рассуждений.
Вернемся к примеру с графическими пользовательскими интерфейсами. Пусть требуется определить графический виджет, связанный с окном:
```d
class Rectangle { ... }
class Window { ... }
class Widget
{
private Window parent;
private Rectangle position;
... // Собственные функции класса Widget
}
```
Затем определяем класс `TextWidget` – тот же `Widget`, но отображающий какой-то текст.
```d
class TextWidget : Widget
{
private string text;
...
}
```
Как реализовать метод `opEquals` для этих двух классов? В случае класса `Widget` один объект этого класса будет равен другому, если обладает тем же состоянием:
```d
// Внутри класса Widget
override bool opEquals(Object rhs)
{
// Второй объект должен быть экземпляром класса Widget
auto that = cast(Widget) rhs;
if (!that) return false;
// Сравнить всё
return parent == that.parent && position == that.position;
}
```
Выражение `cast(Widget)` пытается вытянуть объект типа `Widget` из `rhs`. Если `rhs` – это пустая ссылка или действительный, динамический тип `rhs` не `Widget` и не подкласс `Widget`, выражение с приведением типов возвращает `null`.
Класс `TextWidget` более тонко понимает равенство: правая часть сравнения должна также быть экземпляром класса `TextWidget` и содержать тот же текст.
```d
// Внутри класса TextWidget
override bool opEquals(Object rhs)
{
// Второй объект должен быть экземпляром TextWidget
auto that = cast(TextWidget) rhs;
if (!that) return false;
// Сравнить все имеющие отношение к делу состояния
return super.opEquals(that) && text == that.text;
}
```
Рассмотрим сравнение экземпляра `tw` класса `TextWidget` и экземпляра `w` класса `Widget`, у которого те же расположение и родительское окно. С точки зрения `w` между ним и `tw` наблюдается равенство. Однако с точки зрения `tw` ситуация выглядит иначе: равенство отсутствует, поскольку `w` не является экземпляром класса `TextWidget`. Если бы мы приняли вариант, когда `w == tw`, но `tw != w`, то оператор `==` лишился бы симметричности. Чтобы восстановить симметричность, рассмотрим вариант с менее строгим классом `TextWidget`: пусть внутри метода `TextWidget.opEquals` при обнаружении того, что `rhs` является экземпляром класса `Widget`, но не `TextWidget`, планка сравнения опускается до представления о равенстве класса `Widget`. Реализовать этот метод можно так:
```d
// Альтернативный метод TextWidget.opEquals – СЛОМАННЫЙ
override bool opEquals(Object rhs)
{
// Второй объект должен быть хотя бы экземпляром класса Widget
auto that = cast(Widget) rhs;
if (!that) return false;
// Они равны как экземпляры класса Widget? Если нет, мы закончили
if (!super.opEquals(that)) return false;
// Это экземпляр класса TextWidget?
auto that2 = cast(TextWidget) rhs;
// Если нет, сравнение закончено успешно
if (!that2) return true;
// Сравнить как экземпляры класса TextWidget
return text == that2.text;
}
```
К сожалению, стремление класса `TextWidget` быть более сговорчивым до добра не доведет. Теперь проблема в том, что «сломалась» транзитивность сравнения: легко создать два объекта класса `TextWidget` `tw1` и `tw2`, которые будут отличаться друг от друга (из-за разного текста), но в то же время оба окажутся равными простому экземпляру `w` класса `Widget`. Такое положение дел создало бы ситуацию, когда `tw1 == w` и `tw2 == w`, но `tw1 != tw2`.
Итак, в общем случае сравнение должно выполняться дважды: каждый из операндов сравнения должен подтвердить свое равенство другому операнду. Но есть и хорошие новости: свободная функция `object.opEquals(Object, Object)` избегает процедуры «рукопожатия» – при любом совпадении типов участвующих в сравнении объектов, а в других случаях иногда вообще не инициирует дополнительные вызовы.
[В начало ⮍](#6-8-3-bool-opequalsobject-rhs) [Наверх ⮍](#6-классы-объектно-ориентированный-стиль)
### 6.8.4. int opCmp(Object rhs)
Этот метод реализует упорядочивающее трехвариантное сравнение[^9], необходимое для использования объектов в качестве ключей ассоциативных массивов. Он возвращает некоторое отрицательное число, если `this` меньше `rhs`; некоторое положительное число, если `this` больше `rhs`; и `0`, если `this` и `rhs` считаются неупорядоченными. Так же как и `opEquals`, метод `opCmp` редко вызывают явно. В большинстве случаев вы инициируете его выполнение неявно одним из следующих выражений: `a < b`, `a <= b`, `a > b` и `a >= b`.
Замена производится по той же схеме, что и в случае метода `opEquals`: в качестве посредника во взаимодействии двух объектов-участников задействуется глобальное определение `object.opCmp`. Для каждого из операторов `<`, `<=`, `>` и `>=` компилятор D переписывает выражение `a ‹оп› b` в виде `object.opCmp(a, b) ‹оп› 0`. Например запись `a < b` превращается в `object.opCmp(a, b) < 0`.
Реализовывать метод `opCmp` необязательно. Реализация по умолчанию `Object.opCmp` порождает исключение. Если вы на самом деле реализуете его, метод `opCmp` должен задавать «строгий слабый порядок», то есть этот метод должен удовлетворять следующим инвариантам для непустых ссылок `x`, `y` и `z`:
```d
// 1. Рефлексивность
assert(x.opCmp(x) == 0);
// 2. Транзитивность знака
if (x.opCmp(y) < 0 && y.opCmp(z) < 0) assert(x.opCmp(z) < 0);
// 3. Транзитивность равенства нулю
if ((x.opCmp(y) == 0 && y.opCmp(z) == 0) assert(x.opCmp(z) == 0);
```
Эти три правила могут показаться странными, поскольку выражают аксиомы в терминах не очень знакомого понятия трехвариантного сравнения. Если же переписать их в терминах `<`, получатся знакомые свойства строгого слабого порядка, как они определены в математике:
```d
// 1. Отсутствие у < рефлексивности
assert(!(x < x));
// 2. Транзитивность <
if (x < y && y < z) assert(x < z);
// 3. Транзитивность !(x < y) && !(y < x)
if (!(x < y) && !(y < x) && !(y < z) && !(z < y))
assert(!(x < z) && !(z < x));
```
Третье условие необходимо, чтобы отношение `<` можно было считать строгим слабым порядком. Без этого условия `<` называют *частичным порядком*. Возможно, вам хватит и частичного порядка, но только для ограниченного числа случаев; большинство интересных алгоритмов рассчитаны на строгий слабый порядок. Определять частичный порядок гораздо лучше без синтаксического сахара – с помощью собственных именованных функций, отличных от `opCmp`.
Заметим, что указанные условия определены лишь для `<`, о других упорядочивающих сравнениях речь не идет, потому что они – лишь синтаксический сахар (`x > y` – то же самое, что `y < x`, а `x <= y` – то же самое, что `!(y > x)`, и т. д.).
Есть свойство, являющееся лишь следствием транзитивности и отсутствия рефлексивности, которое, тем не менее, иногда принимают за аксиому, – антисимметричность: из `x < y` следует, что `!(y < x)`. Используя метод *доказательства от противного*, легко удостовериться в том, что не существует такой пары значений `x` и `y`, что неравенства `x < y` и `y < x` будут справедливы одновременно: если бы это было не так, в предыдущей проверке транзитивности можно было бы заменить `z` на `x`, получив такую запись:
```d
if (x < y && y < x) assert(x < x);
```
Если следовать нашей гипотезе, это сравнение истинно, следовательно, проверка, организованная с помощью ключевого слова `assert`, должна пройти без проблем. Но этому не бывать из-за отсутствия рефлексивности, что противоречит гипотезе.
Кроме перечисленных ограничений есть еще одно: поведение метода `opCmp` должно быть согласовано с поведением метода `opEquals`:
```d
// Отношение к opEquals
if (x == y) assert(x <= y && y <= x);
```
Отношение к `opEquals` определено не слишком строго: вполне вероятна ситуация, когда для двух классов неравенства `x <= y` и `y <= x` истинны одновременно – здравый смысл продиктовал бы, что значения `x` и `y` равны. Тем не менее вовсе не обязательно, что `x == y`. Простым примером может послужить класс, определяющий равенство в терминах регистрочувствительных строк, а упорядочивание – в терминах строк, нечувствительных к регистру.
[В начало ⮍](#6-8-4-int-opcmpobject-rhs) [Наверх ⮍](#6-классы-объектно-ориентированный-стиль)
### 6.8.5. static Object factory (string className)
Это любопытный метод, позволяющий создавать объект по заданному имени его класса. Класс, участвующий в этой операции, должен иметь конструктор без аргументов; иначе метод `factory` порождает исключение. Посмотрим на `factory` в действии.
```d
// Файл test.d
import std.stdio;
class MyClass
{
string s = "Здравствуй, мир!";
}
void main()
{
// Создать экземпляр класса Object
auto obj1 = Object.factory("object.Object");
assert(obj1);
// Теперь создать экземпляр класса MyClass
auto obj2 = cast(MyClass) Object.factory("test.MyClass");
writeln(obj2.s); // Writes "Hello, world!"
// factory с именем несуществующего класса возвращает null
auto obj3 = Object.factory("Несуществующий");
assert(!obj3);
}
```
Возможность создавать объект по строке очень полезна для реализации множества идей, таких как шаблон проектирования «Фабрика» и сериализация объекта. Казалось бы, в записи
```d
void widgetize()
{
Widget w = new Widget;
.../* Использование w */...
}
```
нет ничего плохого. Однако позже вы, возможно, передумаете и решите, что для текущей задачи лучше подходит `TextWidget`, класс-наследник, значит, предыдущий код придется привести к следующему виду:
```d
void widgetize()
{
Widget w = new TextWidget;
.../* Использование w */...
}
```
Проблема в том, что придется *изменить код*. Хирургическое вмешательство в код ради внесения нового функционала – зло, поскольку, поступая так, вы сильно рискуете испортить уже имеющуюся функциональность. В идеале для добавления функциональности нужно только добавлять код; это позволяет надеяться, что существующий код продолжит работать как обычно. Это как раз тот случай, когда особенно ценны функции, которые можно переопределять, ведь они позволяют настраивать код, не изменяя его, а лишь внося свои дополнения в особых выверенных точках. Бертран Мейер в шутку по-дзэнски назвал это *принципом Открытости*/*Закрытости*: класс (единица инкапсуляции, в более общей формулировке) должен быть открыт для расширений, но закрыт для изменений. Оператор `new` работает с точностью до наоборот – требует, чтобы вы изменили инициализацию объекта `w`, если хотите корректировать его поведение. Гораздо лучшим решением послужила бы передача имени класса снаружи, ведь таким образом функция `widgetize` отделяется от определенного выбранного виджета:
```d
void widgetize(string widgetClass)
{
Widget w = cast(Widget) Object.factory(widgetClass);
... /* Использование w */...
}
```
Теперь функция `widgetize` освобождена от ответственности за выбор конкретного класса из цепочки наследования, которую образует класс `Widget`. Есть и другие пути достижения гибкости конструирования объектов, расширяющие пространство проектирования в разных направлениях. Чтобы познакомиться с всеобъемлющим описанием этой проблемы, внимательно прочтите статью с драматическим названием «Java’s new considered harmful» (Оператор new из Java опасен).
[В начало ⮍](#6-8-5-static-object-factory-string-classname) [Наверх ⮍](#6-классы-объектно-ориентированный-стиль)
## 6.9. Интерфейсы
Обычно объект (экземпляр класса) содержит состояние и определяет методы, работающие с этим состоянием. Выходит, объект одновременно действует по отношению к внешнему миру и как интерфейс (через свои общедоступные методы), и как инкапсулированная реализация этого интерфейса.
Тем не менее иногда полезно разграничить понятия интерфейса и реализации. Особенно полезно, когда требуется определить взаимодействие разнообразных частей большой программы. Функцию, оперирующую экземпляром класса `Widget`, должен интересовать исключительно интерфейс этого класса, а его реализация – по определению инкапсуляции – рассмотрению не подлежит. Таким образом, на первый план выносится понятие совершенно абстрактного набора методов, состоящего только из методов, которые класс *должен* реализовать, но лишенного всякой реализации. Такую сущность и называют *интерфейсом*.
Определение интерфейса в D выглядит почти как определение класса. Но кроме замены ключевого слова `class` на `interface` для него еще действуют определенные ограничения. В интерфейсе нельзя определять нестатические данные и реализовывать функции, допускающие переопределение. Внутри интерфейса разрешается определять статические данные и финальные функции с реализацией. Например:
```d
interface Transmogrifier
{
void transmogrify();
void untransmogrify();
final void thereAndBack()
{
transmogrify();
untransmogrify();
}
}
```
Этого достаточно, чтобы функция, использующая `Transmogrifier`, скомпилировалась. Например:
```d
void aDayInLife(Transmogrifier device, string mood)
{
if (mood == "играть")
{
device.transmogrify();
play();
device.untransmogrify();
}
else if (mood == "экспериментировать")
{
device.thereAndBack();
}
}
```
Разумеется, поскольку пока еще нет определений для элементов интерфейса `Transmogrifier`, разумного способа вызвать функцию `aDayInLife` тоже нет. Поэтому давайте создадим реализацию этого интерфейса:
```d
class CardboardBox : Transmogrifier
{
override void transmogrify()
{
// Залезть в коробку
...
}
override void untransmogrify()
{
// Вылезти из коробки
...
}
}
```
Для реализации интерфейса используется тот же синтаксис, что и в случае реализации обычного наследника. Класс `CardboardBox` позволяет инициировать такой вызов:
```d
aDayInLife(new CardboardBox, "играть");
```
Любая реализация интерфейса является подтипом этого интерфейса, так что она автоматически конвертируется в него. Мы воспользовались этим механизмом, просто передав объект `CardboardBox` вместо интерфейса `Transmogrifier`, ожидаемого функцией `aDayInLife`.
[В начало ⮍](#6-9-интерфейсы) [Наверх ⮍](#6-классы-объектно-ориентированный-стиль)
### 6.9.1. Идея невиртуальных интерфейсов (NVI)
Кое-что здесь может показаться странным: в интерфейсе `Transmogrifier` есть финальная функция. А как же возвышенная поэзия абстрактной, нереализованной функциональности? Ведь абстрактный интерфейс не должен определять реализацию!
В 2001 году Герб Саттер в своей статье выдвинул интересный тезис, который позже развил в книге. Определяемые интерфейсом методы, которые можно переопределять (такие как `transmogrify` и `untransmogrify` в нашем примере), играют две роли. Во-первых, они являются элементами самого интерфейса, то есть теми функциями, которые будет вызывать клиентский код, чтобы выполнить свою задачу. Во-вторых, такие методы также служат точками для внесения изменений, ведь именно их напрямую переопределяют классы-наследники. Как отметил Саттер, может оказаться полезным разделить методы интерфейса на две категории: абстрактные низкоуровневые методы, которые позже нужно будет реализовать, *плюс* высокоуровневые, видимые методы, которые может использовать клиентский код. Эти два множества могут пересекаться, а могут и не пересекаться, но считать их одинаковыми было бы значительной потерей.
У разделения методов на те, что видит клиентская сторона, и те, что определяет сторона реализующая, есть много достоинств. Такой подход позволяет разрабатывать интерфейсы, дружественные к реализации и к использованию одновременно. Интерфейсу, удовлетворяющему как нуждам реализации, так и нуждам клиентов, нужен компромисс между всеми предъявляемыми к нему требованиями. Слишком много внимания к реализации ведет к банальным, многословным, низкоуровневым интерфейсам, провоцирующим дублирование в клиентском коде, а слишком много внимания к клиентскому коду порождает большие, свободные, избыточные интерфейсы, определяющие помимо необходимых примитивов дополнительные функции, введенные для удобства пользователя. Идея невиртуальных[^10] интерфейсов (NVI) позволяет облегчить жизнь обеим сторонам. Так, интерфейс `Transmogrifier` предоставляет пользователям дополнительную функцию, которая для удобства введена как метод `thereAndBack`, определенный в терминах примитивных операций.
Нарождающаяся идея напоминала шаблон проектирования «Шаблонный метод», но все же казалась достаточно уникальной, чтобы обрести собственное имя – невиртуальный интерфейс (Non-Virtual Interface, NVI). К сожалению, несмотря на то что NVI со временем превратился в популярный шаблон проектирования, по статусу он оставался скорее соглашением между хорошими разработчиками, не достигнув уровня средства языка, позволяющего гарантировать постоянство разработки. Недостаточная поддержка NVI языками в основном связана с тем, что он появился уже после того, как были определены популярные языки программирования, способствовавшие лучшему пониманию техники ООП, которое и привело к возникновению NVI. Так что язык Java вообще не поддерживает NVI, C# поддерживает весьма ограниченно (хотя широко использует NVI в качестве руководящей идеи для разработки), а C++ предоставляет хорошую поддержку на основе соглашений, но при этом не дает серьезных гарантий ни вызывающему, ни реализующему коду.
D полностью поддерживает NVI, предоставляя особые гарантии, если интерфейсы используют спецификаторы доступа. Рассмотрим пример. Предположим, автор интерфейса `Transmogrifier` сильно обеспокоен тем, что его интерфейс могут некорректно использовать: что если метод `transmogrify` вызовут, а метод `untransmogrify` забудут? Давайте запретим клиентам использовать все, кроме метода `thereAndBack`, а реализацию обяжем определить методы `transmogrify` и `untransmogrify`:
```d
interface Transmogrifier
{
// Клиентский интерфейс
final void thereAndBack()
{
transmogrify();
untransmogrify();
}
// Интерфейс реализации
private:
void transmogrify();
void untransmogrify();
}
```
Интерфейс `Transmogrifier` закрыл два своих внутренних элемента. Такие настройки определяют любопытную структуру и поведение программы: класс, реализующий интерфейс `Transomgrifier`, должен определять методы `transmogrify` и `untransmogrify`, но не имеет права их вызывать. На самом деле, никто не сможет вызвать эти две функции извне модуля `Transmogrifier`. Единственный способ вызвать их – неявный вызов через высокоуровневый метод `thereAndBack`, в чем, собственно, и состоит цель разработки: тщательно определенные точки доступа и хорошо структурированный поток управления между вызовами, адресующими эти точки. Язык пресекает обычные попытки нарушить эти гарантии. Например, реализующий класс не может ослабить уровень защиты методов `transmogrify` и `untransmogrify`:
```d
class CardboardBox : Transmogrifier
{
override private void transmogrify() { ... } // Все в порядке
override void untransmogrify() { ... } // Ошибка! Нельзя изменить уровень защиты метода untransmogrify с закрытого на общедоступный!
}
```
Разумеется, поскольку это все же ваша реализация, вы можете сделать метод общедоступным, если захотите, но придется дать ему другое имя:
```d
class CardboardBox : Transmogrifier
{
override private void transmogrify() { ... } // Все в порядке
override private void untransmogrify() // Все в порядке
{
doUntransmogrify();
}
void doUntransmogrify() { ... } // Все в порядке
}
```
Теперь пользователи класса `CardboardBox` могут вызывать метод `doUntransmogrify`, который делает ровно то же самое, что и метод `untransmogrify`. Но важно то, что метод `void untransmogrify()` именно с этими именем и сигнатурой реализующий класс показать не может. Таким образом, клиентскому коду никогда не будет доступна закрытая функциональность с закрытым именем. Если реализация захочет определить и документировать дублирующую функцию, это ее право.
Второй принцип, с помощью которого D гарантирует постоянство реализации NVI, – запрет переопределения финальных методов: никакая реализация интерфейса `Transmogrifier` не может определить метод, который бы мог успешно переопределить `thereAndBack`. Например:
```d
class Broken : Transmogrifier
{
void thereAndBack()
{
// Почему бы не сделать это дважды?
this.Transmogrifier.thereAndBack();
this.Transmogrifier.thereAndBack();
}
// Ошибка! Нельзя переопределить
// финальный метод Transmogrifier.thereAndBack
...
}
```
Если бы такое перекрытие было разрешено, то клиент, знающий, что класс `Broken` реализует интерфейс `Transmogrifier`, не смог бы без колебаний сделать вызов `obj.thereAndBack()` применительно к объекту `obj` типа `Broken`; не было бы никакой уверенности в том, что метод `thereAndBack` делает то, что предписано и документировано интерфейсом `Transmogrifier`. Конечно, клиентский код мог бы вызвать `obj.Transmogrifier.thereAndBack()`, таким образом гарантируя, что вызов пойдет в нужном направлении, но подобные решения, основанные на сверхвнимательности, мало кого привлекут. В конце концов хороший код не ждет, пока вы ослабите бдительность, а просто вдруг начинает вести себя странно. И последнее: если интерфейс определяет общедоступную функцию, она остается видимой во всех его реализациях. Если реализация также является финальной, у реализующего класса нет способа перехватить вызов. Реализация при этом может определить функцию с тем же именем, если это не вызовет конфликта. Например:
```d
class Good : Transmogrifier
{
void thereAndBack(uint times)
{
// Почему бы не сделать это несколько раз?
foreach (i; 0 .. times)
{
thereAndBack();
}
}
...
}
```
Этот код корректен, потому конфликт невозможен: вызов будет выглядеть либо как `obj.thereAndBack()` – и направится к методу `Transmogrify.thereAndBack`, либо как `obj.thereAndBack(n)` – и направится к методу `Good.thereAndBack`. В частности, реализация `Good.thereAndBack` не обязана относить свой внутренний вызов к реализации одноименной функции интерфейса.
[В начало ⮍](#6-9-1-идея-невиртуальных-интерфейсов-nvi) [Наверх ⮍](#6-классы-объектно-ориентированный-стиль)
### 6.9.2. Защищенные примитивы
Иногда, сделав функцию интерфейса закрытой, мы накладываем больше ограничений, чем требуется. Например, следствием такого шага является запрет вызова функции `super` со стороны реализации:
```d
import std.exception;
class CardboardBox : Transmogrifier
{
private:
override void transmogrify() { ... }
override void untransmogrify() { ... }
}
class FlippableCardboardBox : CardboardBox
{
private:
bool flipped;
override void transmogrify()
{
enforce(!flipped, "Невозможно вызвать метод transmogrify: коробка работает в режиме машины времени");
super.transmogrify(); // Ошибка! Нельзя вызвать закрытый метод CardboardBox.transmogrify!
}
}
```
Когда коробка перевернута (`flipped`), она не может действовать как трансмогрификатор, поскольку – как всем известно – в этом случае она всего лишь скучная машина времени. И класс `FlippableCardboardBox` гарантирует такое поведение с помощью вызова функции `enforce`. Но если коробка не перевернута, то новый класс не сможет обратиться к версии метода `transmogrify` своего родителя. Что же делать?
Одно из возможных решений – фокус с переименованием, рассмотренный ранее на примере функции `doUntransmogrify`, но такая практика очень скоро надоедает, если приходится применять ее для нескольких методов. Более простое решение – ослабить уровень защиты двух открытых для переопределения методов класса `Transmogrifier`, заменив спецификатор доступа `private` на `protected`:
```d
interface Transmogrifier
{
final void thereAndBack() { ... }
protected:
void transmogrify();
void untransmogrify();
}
```
Защищенный уровень доступа позволяет реализации обращаться к родительской реализации. Заметим, что усиливать защиту так же некорректно, как и ослаблять. Если интерфейс определил метод, реализация не может наложить на него более строгие ограничения для обеспечения защиты. Например, при условии что интерфейс `Transmogrifier` определяет оба метода `transmogrify` и `untransmogrify` как защищенные, этот код окажется ошибочным:
```d
class BrokenInTwoWays : Transmogrifier
{
public void transmogrify() { ... } // Ошибка!
private void untransmogrify() { ... } // Ошибка!
}
```
Технически осуществимо как ослабление, так и ужесточение требований интерфейса к реализации, но эти возможности вряд ли можно использовать во благо. Интерфейс выражает цель, и должно быть достаточно ознакомиться лишь с определением интерфейса, чтобы полноценно использовать его независимо от доступности статического типа реализуемого класса.
[В начало ⮍](#6-9-2-защищенные-примитивы) [Наверх ⮍](#6-классы-объектно-ориентированный-стиль)
### 6.9.3. Избирательная реализация
Иногда два интерфейса определяют общедоступные финальные методы с одинаковой сигнатурой, что приводит к двусмысленности:
```d
interface Timer
{
final void run() { ... }
...
}
interface Application
{
final void run() { ... }
...
}
class TimedApp : Timer, Application
{
... // Невозможно определить метод run()
}
```
В подобных случаях класс `TimedApp` не может определить собственный метод `run()`, поскольку таким образом он попытался бы незаконно перехватить сразу два метода, а на двух стульях, как известно, не усидишь. Но избавление от одного из двух ключевых слов `final` (в интерфейсе `Timer` или в интерфейсе `Application`) ситуацию бы не спасло, поскольку одно переопределение все равно оставалось бы в силе. Вот если бы оба метода были виртуальными, то мы бы выиграли: метод `TimerApp.run` реализовывал бы методы `Timer.run` и `Application.run` *одновременно*.
Чтобы получить доступ к этим методам объекта `app` типа `TimedApp`, вам придется написать `app.Timer.run()` и `app.Application.run()` для версий интерфейсов `Timer` и `Application` соответственно. Класс `TimedApp` может определить собственные функции, которые будут делегировать вызов этим методам. Главное, чтобы такие функции не пытались подменить `run()`.
[В начало ⮍](#6-9-3-избирательная-реализация) [Наверх ⮍](#6-классы-объектно-ориентированный-стиль)
## 6.10. Абстрактные классы
Нередко бывает, что родительский класс не в состоянии предоставить какую-либо разумную реализацию для некоторых или даже всех своих методов. Можно было бы преобразовать этот класс в интерфейс, но иногда удобно, что такой класс определяет некоторое состояние и виртуальные методы (привилегии, не доступные интерфейсам). И тут на помощь приходят абстрактные классы: они почти такие же, как и обычные, отличие лишь в том, что им дозволено оставлять функции нереализованными – достаточно лишь объявить их с ключевым словом `abstract`.
В качестве иллюстрации рассмотрим проверенный временем пример с иерархией объектов-фигур, задействованных в векторном графическом редакторе. В основании иерархии – класс `Shape`. Любая фигура обладает ограничивающим ее прямоугольником, так что, возможно, класс `Shape` захочет определить его в качестве своего поля (интерфейс не смог бы этого сделать). С другой стороны, некоторые методы класса `Shape` (такие как `draw`) должны остаться нереализованными, поскольку он не может реализовать их осмысленно. Считается, что эти методы определят потомки класса `Shape`.
```d
class Rectangle
{
uint left, right, top, bottom;
}
class Shape
{
protected Rectangle _bounds;
abstract void draw();
bool overlaps(Shape that)
{
return _bounds.left <= that._bounds.right &&
_bounds.right >= that._bounds.left &&
_bounds.top <= that._bounds.bottom &&
_bounds.bottom >= that._bounds.top;
}
}
```
Метод `draw` – абстрактный, что означает три вещи. Во-первых, компилятор не ожидает от класса `Shape` реализации метода `draw`. Во-вторых, компилятор запрещает создавать экземпляры класса `Shape`. В-третьих, компилятор запрещает создавать экземпляры любых наследников класса `Shape`, не реализующих (явно или неявно, благодаря предку) метод `draw`. Слова «явно или неявно» означают, что требование реализации не является транзитивным; например, если определить наследника класса `Shape` с именем `RectangularShape`, который реализует метод `draw`, то заново реализовывать этот метод в потомках `RectangularShape` необязательно.
Компилятор *не ожидает* реализации абстрактного метода, но это не значит, что ее запрещается предоставлять. Например, вполне корректно предоставить реализацию метода `Shape.draw`. Клиентский код может вызывать этот метод, явно квалифицируя вызов, как здесь: `this.Shape.draw()`.
Интересно то, что метод `overlaps` одновременно реализован и открыт для переопределения. По умолчанию он дает приблизительный ответ на вопрос о пересечении двух фигур, понимая под пересечением фигур пересечение их ограничивающих прямоугольников. Из-за такой трактовки этот метод работает неточно применительно к большинству непрямоугольных фигур; например, два круга могут и не перекрывать друг друга, даже если их ограничивающие прямоугольники пересекаются.
Класс, обладающий хотя бы одним абстрактным методом, и сам называется *абстрактным*. Если класс `RectangularShape` является наследником абстрактного класса `Shape` и не переопределяет все абстрактные методы класса `Shape`, то класс `RectangularShape` также считается абстрактным и передает требование реализовать эти абстрактные методы по наследству своим потомкам. Вдобавок классу `RectangularShape` разрешается вводить новые абстрактные методы. Например:
```d
class Shape
{
// Как и ранее
abstract void draw();
...
}
class RectangularShape : Shape
{
// Наследует один абстрактный метод от класса Shape и вводит еще один
abstract void drawFrame();
}
class ARectangle : RectangularShape
{
override void draw() { ... }
// Класс ARectangle все еще абстрактен
}
class SolidRectangle : ARectangle
{
override void drawFrame() { ... }
// Класс SolidRectangle конкретен: больше не осталось нереализованных абстрактных функций
}
```
Самое интересное, что класс может решить заново объявить функцию абстрактной, даже если до него ее уже переопределили и реализовали! В следующем фрагменте кода определен абстрактный класс, от него порожден конкретный класс, а затем от конкретного класса снова порождается абстрактный класс – и все из-за одного-единственного метода.
```d
class Abstract
{
abstract void fun();
}
class Concrete : Abstract
{
override void fun() { ... }
}
class BornAgainAbstract : Concrete
{
abstract override void fun();
}
```
Можно сделать конечной реализацию абстрактного метода...
```d
class UltimateShape : Shape
{
// Вот и все о методе draw
override final void draw() { ... }
}
```
...но, по понятным причинам, нельзя определить метод одновременно и абстрактный, и финальный.
Если нужно объявить целую группу абстрактных методов, то можно использовать одну и ту же запись `abstract` несколько раз, как и спецификатор доступа (см. раздел 6.7.1):
```d
class QuiteAbstract
{
abstract
{
// В этом контексте все абстрактное
void fun();
int gun();
double hun(string);
}
}
```
Абстрактность никак нельзя «выключить» внутри блока `abstract`, поэтому следующее определение некорректно:
```d
class NiceTry
{
abstract
{
void fun();
final int gun(); // Ошибка! Определять финальные абстрактные функции нельзя!
}
}
```
Ключевое слово `abstract` можно использовать и в виде метки:
```d
class Abstractissimo
{
abstract:
// Ниже все абстрактное
void fun();
int gun();
double hun(string);
}
```
Применив однажды метку `abstract:`, ее действие невозможно «выключить».
Наконец, можно пометить с помощью `abstract` целый класс:
```d
abstract class AbstractByName
{
void fun() {}
int gun() {}
double hun(string) {}
}
```
В свете постепенного усиления приведенных вариантов ключевого слова `abstract` может показаться, что, сделав абстрактным целый класс, можно нанести удар и посерьезнее, сделав абстрактным каждый отдельный метод. Ничего подобного. Грубость действия такого средства исключила бы возможность его употребления. Ключевое слово `abstract` перед классом просто запрещает клиентскому коду создавать экземпляры этого класса – можно создавать только экземпляры его неабстрактных потомков. Продолжим начатый выше пример с классом `AbstractByName`:
```d
unittest
{
auto obj = new AbstractByName; // Ошибка! Нельзя создать экземпляр абстрактного класса AbstractByName!
}
class MakeItConcrete : AbstractByName { }
unittest
{
auto obj = new MakeItConcrete; // OK
}
```
[В начало ⮍](#6-10-абстрактные-классы) [Наверх ⮍](#6-классы-объектно-ориентированный-стиль)
## 6.11. Вложенные классы
Вложенные классы – интересное средство языка, заслуживающее особого внимания. Они полезны в качестве строительного материла для реализации более важных идей, таких как множественное порождение подтипов (которое рассматривается ниже).
Класс может определять другой класс прямо внутри себя:
```d
class Outer
{
int x;
void fun(int a) { ... }
// Определить внутренний класс
class Inner
{
int y;
void gun()
{
fun(x + y);
}
}
}
```
Вложенные классы – это просто обычные... *Минуточку*, как получилось, что метод `Inner.gun` обладает доступом к нестатическим полям и методам класса `Outer`? Если бы `Outer.Inner` было классическим определением класса в контексте класса `Outer`, из него было бы невозможно обращаться к данным и вызывать методы объекта `Outer`. В самом деле, откуда появляется доступ к этому объекту? Давайте просто создадим объект типа `Outer.Inner` и посмотрим, что произойдет:
```d
unittest
{
// Сработать не должно
auto obj = new Outer.Inner;
obj.gun(); // Тут наступит конец света, поскольку в поле зрения нет ни Outer.x, ни Outer.fun – здесь вообще нет никакого Outer!
}
```
Поскольку в этом коде создается лишь объект типа `Outer.Inner`, а о создании экземпляра класса `Outer` речь не идет, единственные данные, под которые будет выделена память, – это данные, которые определяет класс `Outer.Inner` (то есть `y`), но не класс `Outer` (то есть `x`).
Удивительным образом определение класса действительно компилируется, а тест модуля – нет. Что же происходит?
Начнем с того, что вы никогда не сможете создать объект класса `Inner`, не имея в своем распоряжении экземпляр класса `Outer`. Это ограничение очень осмысленно, учитывая что `Inner` обладает магическим доступом к состоянию и методам `Outer`. Вот пример корректного создания объекта типа `Outer.Inner`:
```d
unittest
{
Outer obj1 = new Outer;
auto obj = obj1.new Inner; // Ага!
}
```
Сам синтаксис выражения `new` указывает на то, что происходит: для создания объекта типа `Outer.Inner` необходимо, чтобы уже существовал объект типа `Outer`. Ссылка на этот объект (в нашем случае `obj1`) неявно сохраняется в объекте типа `Inner` в качестве значения свойства `outer`, определенного на уровне языка. Затем, когда бы вы ни решили воспользоваться внутренним элементом класса `Outer` (таким как `x`), компилятор переписывает обращение к нему (в случае `x` получится запись `this.outer.x`). Инициализация сохраняемой во вложенном объекте скрытой ссылки на внешний контекст[^11] происходит прямо перед вызовом конструктора этого вложенного объекта, так что у самого конструктора доступ ко внутренним элементам внешнего объекта уже есть. Наконец, протестируем все это, внеся несколько изменений в пример с классами `Outer` и `Inner`:
```d
class Outer
{
int x;
class Inner
{
int y;
this()
{
x = 42; // x – то же, что this.outer.x
assert(this.outer.x == 42);
}
}
}
unittest
{
auto outer = new Outer;
auto inner = outer.new Inner;
assert(outer.x == 42); // Вложенный объект inner изменил внешний объект outer
}
```
Если вы создаете объект типа `Outer.Inner` из нестатической функции-члена класса `Outer`, нет необходимости располагать перед оператором `new` префикс `this` – это делается неявно. Например:
```d
class Outer
{
class Inner { ... }
Inner _member;
this()
{
_member = new Inner; // То же, что this.new Inner
assert(member.outer is this); // Проверить связь
}
}
```
[Исходный код](src/chapter-6-11/)
[В начало ⮍](#6-11-вложенные-классы) [Наверх ⮍](#6-классы-объектно-ориентированный-стиль)
### 6.11.1. Вложенные классы в функциях
Как ни странно, вложение класса в функцию работает почти так же, как и вложение класса в другой класс. Класс, расположенный внутри функции, может обращаться к ее параметрам и локальным переменным:
```d
void fun(int x)
{
string y = "Здравствуй";
class Nested
{
double z;
this()
{
// Обратиться к параметру
x = 42;
// Обратиться к локальной переменной
y = "мир";
// Обратиться к собственной переменной-члену
z = 0.5;
}
}
auto n = new Nested;
assert(x == 42);
assert(y == "мир");
assert(n.z == 0.5);
...
}
```
Классы, вложенные в функции, особенно полезны, когда требуется корректировать поведение некоторого класса: имея функцию, возвращающую экземпляр этого класса, нужного наследника можно создать внутри нее. Приведем пример:
```d
class Calculation
{
double result()
{
double n;
...
return n;
}
}
Calculation truncate(double limit)
{
assert(limit >= 0);
class TruncatedCalculation : Calculation
{
override double result()
{
auto r = super.result();
if (r < -limit) r = -limit;
else if (r > limit) r = limit;
return r;
}
}
return new TruncatedCalculation;
}
```
Функция `truncate` переопределяет метод `result` класса `Calculation`: теперь этот метод возвращает значение в заданных пределах. В работе функции есть одна тонкость: обратите внимание на то, что переопределенный метод `result` использует параметр `limit`. Это не так уж странно, учитывая, что класс `TrancatedCalculation` используется внутри функции `truncate`, но ведь она возвращает экземпляр этого класса во внешний мир. Возникает простой вопрос: где остается значение параметра `limit` после того, как функция `truncate` вернет свой результат? В типичной ситуации компилятор помещает параметры и локальные переменные функции в стек, и после того как она вернула результат, они исчезают. Но в нашем примере значение параметра `limit` используется уже *после* того, как функция `truncate` вернула свой результат. То есть лучше бы параметру `limit` находиться где-то помимо стека, а иначе из-за небезопасного обращения к освобожденной памяти стека нарушится работа всего кода.
Но благодаря небольшой поддержке компилятора рассмотренный пример работает нормально. Когда бы компилятору ни приходилось компилировать функцию, он всегда просматривает ее в поисках нелокальных утечек (non-local escapes) – ситуаций, когда параметр или локальная переменная остается в использовании уже после того, как функция вернула результат[^12]. Если обнаружена такая утечка, компилятор изменяет способ выделения памяти под локальное состояние (параметры плюс локальные переменные): вместо выделения памяти в стеке в этом случае происходит динамическое выделение памяти.
[В начало ⮍](#6-11-1-вложенные-классы-в-функциях) [Наверх ⮍](#6-классы-объектно-ориентированный-стиль)
### 6.11.2. Статические вложенные классы
Посмотрим правде в глаза: вложенные классы – вовсе не то, чем кажутся. Мы воспринимаем их как обычные классы, определенные внутри классов или функций, но очевидно, что они необычны: особые синтаксис и семантика выражения `new`, магическое свойство `.outer`, другие правила поиска – вложенные классы определенно отличаются от обычных. Что если требуется определить внутри класса или функции именно обычный класс? И вновь на помощь приходит ключевое слово `static` – достаточно поместить его перед определением этого класса. Например:
```d
class Outer
{
static int s;
int x;
static class Ordinary
{
void fun()
{
writeln(s); // Все в порядке, доступ к статическому значению разрешен
writeln(x); // Ошибка! Нельзя обратиться к нестатическому внутреннему элементу x!
}
}
}
unittest
{
auto obj = new Outer.Ordinary; // Все в порядке
}
```
Будучи обычным классом, статический внутренний класс не имеет доступа к внешнему объекту просто за отсутствием таковых. Зато благодаря контексту определения статический внутренний класс обладает доступом к статическим внутренним элементам внешнего класса.
[В начало ⮍](#6-11-2-статические-вложенные-классы) [Наверх ⮍](#6-классы-объектно-ориентированный-стиль)
### 6.11.3. Анонимные классы
Если в определении класса, заданном внутри спецификации суперкласса, отсутствуют имя и `:`, то это определение *анонимного класса*[^13]. Такой класс всегда должен быть (нестатически) вложенным в функцию, и единственный способ использования этого класса – непосредственное создание его экземпляра:
```d
class Widget
{
abstract uint width();
abstract uint height();
}
Widget makeWidget(uint w, uint h)
{
return new class Widget
{
override uint width() { return w; }
override uint height() { return h; }
...
};
}
```
Это средство языка работает почти так же, как анонимные функции. Создание анонимного класса эквивалентно созданию нового именованного класса с последующим созданием его экземпляра. Эти два шага сливаются в один. Такое малопонятное средство может показаться бесполезным, но на практике многие проектные решения широко его используют для связи наблюдателей и субъектов.
[В начало ⮍](#6-11-3-анонимные-классы) [Наверх ⮍](#6-классы-объектно-ориентированный-стиль)
## 6.12. Множественное наследование
D моделирует простое (одиночное) наследование классов и множественное наследование интерфейсов. Примерно так же поступают Java и C#, а такие языки, как C++ и Eiffel, идут другим путем.
Интерфейс может наследовать от любого числа интерфейсов. Поскольку он не может реализовать ни одну из функций, открытых для переопределения, интерфейс-наследник – это всего лишь усовершенствованный интерфейс, который требует реализации методов всех своих предков и, возможно, некоторых собственных. Пример:
```d
interface DuplicativeTransmogrifier : Transmogrifier
{
Object duplicate(Object whatever);
}
```
Интерфейс `DuplicativeTransmogrifier` является наследником интерфейса `Transmogrifier`, так что теперь любой класс, реализующий интерфейс `DuplicativeTransmogrifier`, должен также реализовывать все методы интерфейса `Transmogrifier`, помимо только что объявленного метода `duplicate`. Отношение наследования работает как обычно: всюду, где ожидается интерфейс `Transmogrifier`, можно передавать интерфейс `DuplicativeTransmogrifier`, но не наоборот.
В общем случае интерфейс может стать наследником любого числа интерфейсов, как положено, накапливая примитивы, требующие реализации. Класс также может реализовать любое число интерфейсов. Например:
```d
interface Observer
{
void notify(Object data);
...
}
interface VisualElement
{
void draw();
...
}
interface Actor
{
void nudge();
...
}
interface VisualActor : Actor, VisualElement
{
void animate();
...
}
class Sprite : VisualActor, Observer
{
void draw() { ... }
void animate() { ... }
void nudge() { ... }
void notify(Object data) { ... }
...
}
```
На рис. 6.4 изображена только что закодированная иерархия наследования. Интерфейсы представлены овалами, а классы – прямоугольниками.
***Рис. 6.4.*** *Простая иерархия наследования, иллюстрирующая множественное наследование интерфейсов*
Теперь определим класс `Sprite2`. Автор `Sprite2` забыл, что интерфейс `VisualActor` уже является наследником интерфейса `Actor`, поэтому помимо интерфейсов `Observer` и `VisualActor` сделал родителем `Sprite2` еще и интерфейс `Actor`. Полученная иерархия представлена на рис. 6.5.
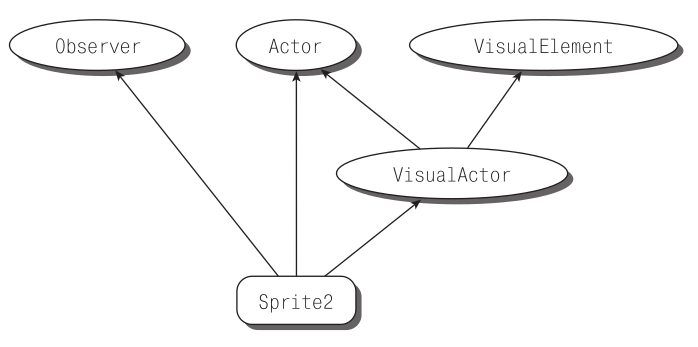
***Рис. 6.5.*** *Иерархия наследования с лишней ветвью (в данном случае это связь между `Sprite2` и `Actor`). Удалять лишние связи необязательно, но большого труда это обычно не требует, а в результате получается более чистая структура и уменьшается размер объекта*
Лишняя ветвь в иерархии тут же распознается как непосредственная связь с интерфейсом, от которого объект также наследует косвенно. Дублирующие связи не вызывают особых проблем, но в большинстве реализаций они увеличивают размер итогового объекта, в данном случае `Sprite2`.
Бывает, что один и тот же интерфейс наследуется через разные ветви, и ни одну из них удалить нельзя. Предположим, что сначала мы добавили интерфейс `ObservantActor`, наследующий от интерфейсов `Observer` и `Actor`:
```d
interface ObservantActor : Observer, Actor
{
void setActive(bool active);
}
interface HyperObservantActor : ObservantActor
{
void setHyperActive(bool hyperActive);
}
```
Затем мы определили класс `Sprite3`, реализующий интерфейсы `HyperObservantActor` и `VisualActor`:
```d
class Sprite3 : HyperObservantActor, VisualActor
{
override void notify(Object) { ... }
override void setActive(bool) { ... }
override void setHyperActive(bool) { ... }
override void nudge() { ... }
override void animate() { ... }
override void draw() { ... }
...
}
```
Такие условия несколько меняют положение дел (рис. 6.6). Если `Sprite3` хочет реализовать как `HyperObservantActor`, так и `VisualActor`, ему неизбежно придется реализовывать интерфейс `Actor` дважды (по разным связям). К счастью, для компилятора это не проблема – повторное наследование одного и того же интерфейса разрешено. Тем не менее повторное наследование одного и того же класса запрещено, поэтому и любое множественное наследование классов в D тоже запрещено.
Почему такая дискриминация? Что именно делает интерфейсы более податливыми для множественного наследования, чем классы? Подробное объяснение вышло бы довольно замысловатым, а если вкратце, то значимая разница между интерфейсом и классом в том, что последний может содержать состояние. И что гораздо важнее, класс может содержать модифицируемое состояние. Интерфейс же, напротив, не содержит собственного состояния; с каждым реализованным интерфейсом ассоциирована своя бухгалтерия (во многих реализациях это указатель на «виртуальную таблицу» – массив указателей на функции), но этот указатель идентичен для всех вхождений интерфейса в класс, никогда не меняется и находится под контролем компилятора. Компилятор использует эти ограничения с выгодой для себя: он размещает множество копий этой «бухгалтерской» информации в классе, но класс об этом никогда не узнает.
***Рис. 6.6.*** *Иерархия с множественными путями между узлами (в данном случае между узлами `Sprite3` и `Actor`). Такую структуру обычно называют «ромбовидной иерархией наследования», поскольку при отсутствии узла `HyperObservantActor` пути между `Sprite3` и `Actor` образовали бы ромб. В общем случае такие иерархии могут принимать разные формы. Их характерная особенность – множество путей от одного узла к другому*
О достоинствах и недостатках множественного наследования спорят давно. Дебаты продолжаются и вряд ли прекратятся в ближайшем будущем, но в одном оппоненты сошлись: реализовать множественное наследование так, чтобы оно одновременно было простым, эффективным и полезным, непросто. Одни языки, придавая меньшее значение эффективности, делают выбор в пользу дополнительной выразительности, которую привносит множественное наследование. Другие языки, заложив основу высокой производительности (например, с помощью непрерывных объектов и скоростной диспетчеризации функций), ради этого ограничивают гибкость возможных программных решений. Интересное решение, позволяющее задействовать большинство преимуществ множественного наследования без свойственных ему проблем, – примеси в языке Scala (по сути, это интерфейсы, укомплектованные реализациями по умолчанию). Подход языка D заключается в разрешении множественного *порождения подтипов*, то есть порождения подтипов без наследования. Посмотрим, как это работает.
[В начало ⮍](#6-12-множественное-наследование) [Наверх ⮍](#6-классы-объектно-ориентированный-стиль)
## 6.13. Множественное порождение подтипов
Продолжим достраивать программу, использующую класс `Shape`. Допустим, требуется определить объекты класса `Shape`, которые можно было бы хранить в базе данных. Мы нашли отличную библиотеку, которая обеспечивает постоянство объектов с помощью базы данных, что прекрасно нам подходит, кроме одного: она требует, чтобы каждый сохраняемый объект наследовал от класса `DBObject`.
```d
class DBObject
{
private:
... // Состояние
public:
void saveState() { ... }
void loadState() { ... }
...
}
```
Подобную ситуацию можно смоделировать по-разному, но согласитесь, если бы не ограничения языка, вполне естественно было бы определить класс `StorableShape`, который «являлся» бы классом `Shape` и `DBObject` одновременно. Основанием иерархии фигур в таком случае стал бы класс `StorableShape`. И любой объект типа `StorableShape` на экране выглядел и вел бы себя как объект типа `Shape`, а при переносе обратно в базу данных – как объект типа `DBObject`. Но это было бы множественное наследование классов, что в D *запрещено*, так что придется нам поискать альтернативное решение.
К счастью, язык приходит на помощь, предоставляя общий и очень полезный механизм – множественное порождение подтипов. Класс может указать, что он является подтипом любого другого класса, и для этого классу-подтипу не требуется становиться наследником класса-супертипа. Все, что нужно сделать, – указать объявление `alias this`. Простейший пример:
```d
class StorableShape : Shape
{
private DBObject _store;
alias _store this;
this()
{
_store = new DBObject;
}
...
}
```
Класс `StorableShape` наследует от и «является» классом `Shape`, но также является и классом `DBObject`. Когда бы ни потребовалось привести экземпляр класса `StorableShape` к экземпляру класса `DBObject` и когда бы ни выполнялся поиск элемента в классе `StorableShape`, поле `_store` тоже имеет право голоса. Запросы, сопоставляемые с `DBObject`, автоматически перенаправляются от `this` к `this._store`. Например:
```d
unittest
{
auto s = new StorableShape;
s.draw(); // Вызывает метод класса Shape
s.saveState(); // Вызывает метод класса DBObject
// Перезаписывается в виде s._store.saveState()
Shape sh = s; // Обычное приведение "вверх" вида потомок -> предок
DBObject db = s; // Перезаписывается в виде DBObject db = s._store
}
```
По сути, `StorableShape` – это подтип типа `DBObject`, а поле `_store` – это подобъект типа `DBObject` объекта типа `StorableShape`.
В классе может быть неограниченное число объявлений `alias this`, таким образом, класс может стать подтипом неограниченного числа типов[^14].
[В начало ⮍](#6-13-множественное-порождение-подтипов) [Наверх ⮍](#6-классы-объектно-ориентированный-стиль)
### 6.13.1. Переопределение методов в сценариях множественного порождения подтипов
Но ведь не может все быть так просто, правда? И все непросто, потому что класс `StorableShape` все это время мошенничал. Да, обладая объявлением `alias this`, тип `StorableShape` номинально является типом `DBObject`, но не может напрямую переопределить ни один из методов класса `DBObject`. Очевидно, что методы класса `Shape` могут переопределяться как обычно, но где то место, где может быть переопределен метод `DBObject.saveState`? Возвращая `_store` в качестве псевдоподобъекта, мы уклоняемся от решения проблемы – на самом деле, ко внешнему объекту `StorableShape` привязано совсем немного информации о `_store`, по крайней мере, пока мы ничего не сделали, чтобы это изменить. Так посмотрим, что в наших силах.
Точное место, где смошенничало исходное определение класса `StorableShape`, – инициализация поля `_store` выражением `new DBObject`. Это полностью отделяет подобъект `_store` от внешнего объекта класса `StorableShape`, которому нужно переопределить методы `DBObject`. Итак, что нам необходимо сделать, так это определить новый класс `MyDBObject` внутри класса `StorableShape`. Этот класс сохранит обратную ссылку на внешний объект `StorableShape` и переопределит все методы, которые требуется переопределить. Наконец, внутри переопределенных методов класс `MyDBObject` обладает доступом ко всему классу `StorableShape`, и все можно делать так, будто в нашем распоряжении полноценное множественное наследование. Круто!
Если слова «внешний объект» напоминают вам что-то, уже прозвучавшее в этой главе, поздравляю: вы заметили одно из самых счастливых совпадений в анналах программирования. Вложенные классы (см. раздел 6.11) так хорошо подходят для «эмуляции» множественного наследования, что их можно принять за *deus ex machina*[^15]. На самом деле, вложенные классы (на создание которых вдохновил язык Java) появились задолго до конструкции `alias this`.
Использование вложенных классов делает переопределение с `alias this` удивительно простым. Все, что нужно сделать в этом случае, – определить вложенный класс и сделать его наследником класса `DBObject`. Внутри такого класса можно переопределить какой угодно метод `DBObject`, и здесь вы обладаете полным доступом к общедоступным и защищенным определениям класса `DBObject` и ко всем определениям класса `StorableShape`. Если бы это было чуть легче, то было бы запрещено по крайней мере в нескольких штатах.
```d
class StorableShape : Shape
{
private class MyDBObject : DBObject
{
override void saveState()
{
// Доступ к DBObject и StorableShape
...
}
}
private MyDBObject _store;
alias _store this;
this()
{
// Вот решающий момент установления связи
_store = this.new MyDBObject;
}
...
}
```
Ключевым моментом является получение полем `_store` доступа ко внешнему объекту `StorableShape`. Как показано в разделе 6.11, создание вложенного класса позволяет чудесным образом сохранить внешний объект (в данном случае `this`) внутри вложенного класса. С помощью нотации `this.new MyObject` всего лишь предпринята попытка прояснить, что `this` обуславливает создание нового объекта `MyDBObject`. (На самом деле, `this.` и так подставляется неявно, поэтому в данном случае это можно не указывать.)
Единственным камнем преткновения служит то, что внутренние элементы `DBObject` будут перекрывать внутренние элементы `StorableShape`. Предположим, что оба класса `DBObject` и `Shape` определили поле с именем `_name`:
```d
class Shape
{
protected string _name;
abstract void draw();
...
}
class DBObject
{
protected string _name;
void saveState() { ... }
void loadState() { ... }
...
}
```
При реализации множественного порождения подтипов с помощью класса `MyDBObject`, вложенного в класс `StorableShape`, поле `DBObject._name` перекрывает поле `StorableShape._name`. Таким образом, если код внутри `MyDBObject` будет использовать просто `_name`, то через этот идентификатор он будет обращаться к `DBObject._name`.
```d
class StorableShape : Shape
{
private class MyDBObject : DBObject
{
override void saveState()
{
// Изменить Shape._name внешнего объекта Shape
this.outer._name = "A";
// Изменить DBObject._name объекта-родителя
_name = "B";
// Просто для наглядности
assert(super._name == "B");
}
}
private MyDBObject _store;
alias _store this;
this()
{
_store = new MyDBObject;
}
...
}
```
[Исходный код](src/chapter-6-13-1/)
[В начало ⮍](#6-13-1-переопределение-методов-в-сценариях-множественного-порождения-подтипов) [Наверх ⮍](#6-классы-объектно-ориентированный-стиль)
## 6.14. Параметризированные классы и интерфейсы
Иногда требуется параметризировать некоторый класс или интерфейс с помощью сущности, известной во время компиляции. Рассмотрим, например, определение интерфейса стека. Во избежание дублирования кода (`StackInt`, `StackDouble`, `StackWidget`, ...) необходимо параметризировать этот интерфейс типом сохраняемых в стеке элементов. Определение параметризированного интерфейса в D:
```d
interface Stack(T)
{
@property bool empty();
@property ref T top();
void push(T value);
void pop();
}
```
С помощью синтаксиса `(T)` в интерфейс `Stack` вводится параметр типа. В теле интерфейса `T` можно использовать так же, как любой другой тип. Обращаясь к интерфейсу `Stack` в клиентском коде, нужно указать аргумент. Такой аргумент можно передать с помощью бинарного оператора `!`, как здесь:
```d
unittest
{
alias Stack!(int) StackOfInt;
alias Stack!int SameAsAbove;
...
}
```
Там, где используется всего один параметр (как и в нашем случае с интерфейсом `Stack`), круглые скобки можно опустить.
Логично было бы реализовать интерфейс в классе. В идеале реализация тоже должна быть обобщенной (не должна быть настроена на какой-либо конкретный тип элементов). Следовательно, определяем параметризированный класс `StackImpl`, который принимает параметр `T`, передает его в `Stack` и использует внутри своей реализации. А теперь реализуем стек на основе массива:
```d
import std.array;
class StackImpl(T) : Stack!T
{
private T[] _store;
@property bool empty()
{
return _store.empty;
}
@property ref T top()
{
assert(!empty);
return _store.back;
}
void push(T value)
{
_store ~= value;
}
void pop()
{
assert(!empty);
_store.popBack();
}
}
```
Работать с `StackImpl` так же весело, как и реализовывать его:
```d
unittest
{
auto stack = new StackImpl!int;
assert(stack.empty);
stack.push(3);
assert(stack.top == 3);
stack.push(5);
assert(stack.top == 5);
stack.pop();
assert(stack.top == 3);
stack.pop();
assert(stack.empty);
}
```
Как только вы создадите экземпляр параметризированного класса, он превратится в обычный класс, так что `StackImpl!int` – это такой же класс, как и любой другой. Именно этот конкретный класс реализует `Stack!int`, поскольку в формочку для вырезания `StackImpl(T)` под видом `T` вставили `int` по всему телу этого класса.
[Исходный код](src/chapter-6-14/)
[В начало ⮍](#6-14-параметризированные-классы-и-интерфейсы) [Наверх ⮍](#6-классы-объектно-ориентированный-стиль)
### 6.14.1. И снова гетерогенная трансляция
Теперь, раз уж мы заговорили о выведении настоящих типов из параметризированных типов, приглядимся к процессу подстановки. Впервые мы обсуждали понятие гетерогенной трансляции (которая противоположна гомогенной трансляции) в разделе 5.3 в контексте функций с обобщенными типами. Освежим в памяти основные моменты: в случае гомогенной трансляции инфраструктура языка предполагает, что все значения имеют один и тот же тип (например, все они объекты – `Object`), и автоматически подгоняет обобщенный (содержащий аргументы типов) код к этому общему типу. Подгонка может включать приведение типов в обе стороны, а также «упаковку» значений некоторых типов (чтобы заставить их соблюдать некоторый общий формат данных) и последующую их «распаковку» (когда пользовательский код захочет использовать упакованные значения). Этот процесс безопасен для типов и полностью прозрачен. Языки Java и C# используют гомогенную трансляцию для своих параметризированных типов.
В соответствии с гомогенным подходом все стеки `StackImpl` разделяют один и тот же код для реализаций своих методов. И, что более важно, на уровне типов не существует никаких различий: динамические типы `StackImpl!int` и `StackImpl!double` одинаковы. Транслятор, по сути, определяет *один* интерфейс для всех `Stack!T` и *один* класс для всех `StackImpl!T`. Такие типы называют *очищенными*, поскольку любая информация, специфичная для `T`, стирается. Затем транслятор искусно заменяет код, использующий `Stack` и `StackImpl` c разными `T`, чтобы использовались только упомянутые очищенные типы. Статическая информация о типах, которые клиентский код вставляет в `Stack` и `StackImpl`, надолго не сохраняется; эта информация служит для статической проверки типов, а затем сразу же забывается – или, лучше сказать, стирается. При таком подходе возникает ряд проблем – по той простой причине, что часть информации теряется. Вот простой пример: нельзя перегрузить функцию `Stack!int` функцией `Stack!double` и наоборот, поскольку у них один и тот же тип. Есть и более глубокие вопросы безопасности, подлежащие обсуждению. Отчасти они рассмотрены в научной литературе.
Гетерогенный транслятор (такой как механизм шаблонов C++) подходит к проблеме по-другому. Для гетерогенного транслятора `Stack` – не тип, а лишь средство для создания типа. (Еще одно иносказание для ясности: тип – это схема значения, а параметризированный тип – схема типа.) Каждое воплощение `Stack!int`, `Stack!string`, стек любых других значений, которые могут понадобиться в вашем приложении, породит отдельный, отличный от других тип. Гетерогенный транслятор генерирует все эти типы, копируя и вставляя тело интерфейса `Stack` при замене `T` любым типом, который вы решили использовать с интерфейсом `Stack`. При таком подходе, скорее всего, будет сгенерировано больше кода, но все же это более мощное решение, поскольку статическая информация о типах сохраняется во всей полноте. Кроме того, при гетерогенной трансляции в каждом случае код генерируется индивидуально, следовательно, этот код может оказаться более быстрым.
D везде использует гетерогенную трансляцию, а это значит, что `Stack!int` и `Stack!double` – разные интерфейсы, а `StackImpl!int` и `StackImpl!double` – разные типы. Кроме общего происхождения от одного и того же параметризированного типа эти типы никак друг с другом не связаны. (Но вы, конечно, можете связать их некоторым образом, например, сделав все реализации интерфейса `Stack` наследниками общего интерфейса.) Поскольку класс `StackImpl` генерирует отдельную комбинацию методов для каждого подставленного в него типа, происходит частичное дублирование бинарного кода, что особенно раздражает, так как сгенерированный код часто оказывается полностью идентичным. Умный компилятор объединил бы все эти идентичные функции в одну (на момент написания этой книги D не обладает такими способностями, но в более зрелых компиляторах С++ такое объединение уже является принятой технологией).
Конечно же, у класса может быть больше одного параметра типа. Покажем это на примере класса `StackImpl`, наделив его одной интересной особенностью. Вместо того чтобы привязывать структуру хранения к массиву, вынесем это решение за пределы `StackImpl`. Из всей функциональности массивов `StackImpl` использует только `empty`, `back`, `~=` и `popBack`. Так сделаем решение о выборе контейнера деталью реализации `StackImpl`:
```d
class StackImpl(T, Backend) : Stack!T
{
private Backend _store;
@property bool empty()
{
return _store.empty;
}
@property ref T top()
{
assert(!empty);
return _store.back;
}
void push(T value)
{
_store ~= value;
}
void pop()
{
assert(!empty);
_store.popBack();
}
}
```
[В начало ⮍](#6-14-1-и-снова-гетерогенная-трансляция) [Наверх ⮍](#6-классы-объектно-ориентированный-стиль)
## 6.15. Переопределение аллокаторов и деаллокаторов[^16]
Как мы помним, D является языком для системного программирования. Иногда бывает нужно воспользоваться преимуществами объектно-ориентированного программирования, применяя при этом собственную стратегию выделения памяти. Текущие реализации D любезно предоставляют возможность определить для класса собственные *аллокатор* (от англ. allocate – назначать, размещать) – функцию для выделения памяти и *деаллокатор* – функцию для ее освобождения. Вот как это выглядит:
```d
import std.c.stdlib;
import core.exception;
class StdcClass
{
...
new(size_t obj_size)
{
void* ptr = malloc(obj_size);
if (ptr is null)
throw new OutOfMemoryError(__FILE__, __LINE__);
return ptr;
}
delete(void* ptr)
{
if (ptr)
free(ptr);
}
}
```
Аллокатор объявляется как метод класса `new` без указания возвращаемого типа. Аллокатор всегда должен возвращать пустой указатель (`void*`). Аллокатор имеет минимум один аргумент – размер экземпляра класса в байтах типа `size_t`. В нашем примере память выделяется функцией `malloc` стандартной библиотеки языка C. Эта функция принимает в качестве аргумента размер выделяемой памяти и в случае успеха возвращает адрес выделенного блока памяти, иначе возвращает `null`. После вызова этой функции мы проверяем полученный адрес. Если он равен `null`, то порождаем исключение, в которое передаем имя текущего файла и номер текущей строки – информацию, полезную при отладке. Если указатель корректный, мы передаем его инструкции `return` аллокатора.
Деаллокатор объявляется с помощью ключевого слова `delete` и имеет один аргумент – указатель на блок памяти, в котором размещен объект. В приведенном примере, если указатель не пустой, мы освобождаем память, выделенную под объект.
Все. Мы получили класс, который не использует сборщик мусора. Теперь мы можем создавать и уничтожать экземпляры этого класса привычным для программистов на C++ образом:
```d
StdcClass obj = new StdcClass();
...
delete obj;
```
Но будьте внимательны. Если вы уже успели расслабиться, полагаясь на сборщик мусора D, то соберитесь. Вам придется самостоятельно отслеживать созданные объекты и уничтожать их, когда в них пропадает необходимость, с помощью оператора `delete`. Каждому вызову `new` должен соответствовать вызов `delete`. Теперь от утечек памяти вас не спасет никто, кроме вас самих. Это плата за более быстрое и экономное создание объектов.
Но предположим, что мы предоставим пользователю класса право самому выделить память удобным для него образом и очистить ее также самостоятельно:
```d
import std.c.stdlib;
import core.exception;
class StdcClass
{
...
new(size_t obj_size)
{
void* ptr = malloc(obj_size);
if (ptr is null)
throw new OutOfMemoryError(__FILE__, __LINE__);
return ptr;
}
new(size_t, void* ptr)
{
if (ptr is null)
throw new OutOfMemoryError(__FILE__, __LINE__);
return ptr;
}
delete(void* ptr)
{
if (ptr)
free(ptr);
}
}
```
Попробуем его использовать.
```d
static void[__traits(classInstanceSize, StdcClass)] data = void;
auto i_1 = new(data.ptr) StdcClass(); // Разместить объект в статическом буфере
auto i_2 = new StdcClass(); // Выделить память встроенным аллокатором
...
delete i_2;
```
Как видим, аллокаторы могут быть перегружены обычным образом. Первый аргумент (размер экземпляра) обязателен, он передается конструктору автоматически. Остальные аргументы передаются выражению `new`. Деаллокатор перегружать нельзя.
Аллокаторы и деаллокаторы классов считаются устаревшей возможностью, и ее планируют убрать из самого языка, так как, не считая особого синтаксиса, ее можно запросто перевоплотить как простые функции в пользовательском коде. Например в стандартной библиотеке есть функция `emplace`:
```d
import std.conv;
class C
{
int i;
this() { i = 42; }
}
unittest
{
void[__traits(classInstanceSize, C)] data = void;
auto c = emplace!C(data[]);
assert(c.i == 42);
}
```
К тому же, как всегда, при большой силе – большая ответственность: если вы будете выделять память под классы, не используя кучу под контролем сборщика мусора, и ваш класс содержит указатели (в том числе неявные, унаследованные от классов-родителей) на данные, выделенные в памяти сборщика мусора, вы обязаны декларировать их создание сборщику мусора вызовом функции `core.memory.GC.addRange()`. Иначе сборщик мусора не будет знать о ссылках на данные, хранящихся в ваших классах, и может счесть мусором данные, на которые ваши классы все еще ссылаются. Это может повлечь за собой порчу данных и трудноуловимые ошибки программы, так как в случаях порчи данных сбой может произойти уже спустя пару минут после порчи в совершенно постороннем, невинном коде, который всего лишь пытался использовать свою ненароком испорченную область памяти. Мы вас предупредили!
[В начало ⮍](#6-15-переопределение-аллокаторов-и-деаллокаторов-16) [Наверх ⮍](#6-классы-объектно-ориентированный-стиль)
## 6.16. Объекты scope[^17]
В C++ есть возможность создать экземпляр класса как автоматическую переменную. При создании экземпляра память выделяется в стеке и запускается конструктор, а после выхода экземпляра из области видимости автоматически запускается деструктор.
Эта возможность полезна при использовании небольших классов, создаваемых для выполнения какой-то одной задачи, выполнив которую, они становятся не нужны. При использовании автоматических переменных нет необходимости вызывать деструктор, поскольку он запускается автоматически. Такая техника в языках ООП называется RAII (Resource Acquisition Is Initialization – «получение ресурса есть его инициализация»), так как она относится и к инициализации при создании объекта, и к его уничтожению при покидании области видимости.
Для поддержки RAII язык D предоставляет структуры с деструкторами, которые будут описаны в следующей главе, и похожую конструкцию `scope(exit)`. Но еще до того как D стал поддерживать структуры с деструкторами, подход RAII был реализован в объектах `scope`. Эта возможность присутствует и в текущих реализациях, но считается устаревшей и небезопасной.
По сути, объект `scope` – это класс памяти, и используется примерно так же:
```d
scope obj = new SomeClass(arg_1);
scope SomeClass obj_2 = new SomeClass(arg_1);
```
Обе записи делают одно и то же. Они создают временный экземпляр класса, который автоматически будет уничтожен при выходе из области видимости. Память под него может быть выделена в стеке (а может, и нет), но в любом случае нельзя передавать ссылку за пределы области видимости переменной. При объявлении собственных аллокатора и деаллокатора будут использованы они. Гарантируется, что сразу после выхода из области видимости будет вызвана инструкция `delete`.
В отличие от C++, в D объект `scope` сохраняет ссылочную семантику.
Как следствие того, что память выделяется в стековом фрейме функции, объект `scope` не может быть возвращен функцией. Если это делается явно, компилятор генерирует ошибку:
```d
Object oo()
{
scope t = new Object;
return t; // Ошибка времени компиляции
}
```
Однако если объект `scope` возвращается неявно, отследить это компилятор не сможет:
```d
Object foo()
{
scope t = new Object;
Object p = t;
return p; // Компилятор пропустит это, но результат ни к чему хорошему не приведет
}
```
Чтобы избежать подобных конфликтов, D вводит понятие *класса* `scope`. Экземпляры класса `scope` могут быть только объектами `scope`. Объявления не `scope`-ссылки на объект компилятор не допустит. Для объявления класса `scope` нужно добавить в его объявление атрибут `scope`. Атрибут `scope` является транзитивным, то есть все подклассы класса `scope` также являются классами `scope`.
Объявим абстрактный класс для нахождения дайджеста (хеш-суммы). Конкретная реализация, произведенная от данного класса, может реализовывать алгоритм нахождения MD5-дайджеста, SHA-256 или любого другого, но интерфейс от этого не изменится.
```d
import std.stdio;
abstract scope class Digest
{
abstract void update (void[] data);
abstract ubyte[] result();
}
class Md5: Digest // Тоже scope
{
...
}
```
Приведем пример функции для вычисления MD5-суммы какого-то файла:
```d
ubyte[] calculateHash(string filename)
{
scope digest = new Md5();
auto fd = File(filename, "r");
ubyte[] buff = new ubyte[4096];
ubyte[] readBuff;
do {
readBuff = fd.rawRead(buff);
digest.update(readBuff);
} while (readBuff.length);
return digest.result();
}
void main(string[] args)
{
ubyte[] hash = calculateHash(args[1]);
...
}
```
Однако даже при использовании классов `scope` компилятор не может отследить сохранение ссылки на объект при передаче ее функции с неявным приведением типов:
```d
scope class C { }
Object saved;
void save(Object c) {
saved = c;
}
void derp()
{
scope c = new C;
save(c);
}
void main()
{
derp();
// Куда сейчас указывает глобальная переменная saved?
}
```
Использование объектов `scope` может повысить производительность. Если класс не переопределяет аллокатор по умолчанию, память под объект может быть выделена в стеке. Выделить память в стеке гораздо быстрее, чем динамическую память. Кроме того, объект `scope` использует память ровно столько, сколько нужно, автоматически освобождая ее. В случае же со сборщиком мусора память будет освобождена когда-нибудь. Чем больше памяти будет выделяться и освобождаться не через сборщик мусора, тем чаще будет производиться сбор. Во время сбора мусора приостанавливаются все потоки выполнения и производится поиск блоков памяти, на которые нет ни одной ссылки. Такие блоки памяти освобождаются.
Класс памяти `scope` и классы `scope` считаются устаревшими и небезопасными, и их планируют убрать из самого языка. Вместо них в стандартную библиотеку была добавлена очень похожая конструкция `scoped!T`:
```d
import std.typecons;
unittest
{
class A { int x; }
auto a1 = scoped!A();
auto a2 = scoped!A();
a1.x = 42;
a2.x = 53;
assert(a1.x == 42);
}
```
Конструкция `scoped!T`, которую можно найти в модуле `std.typecons`, столь же небезопасна, но не засоряет очередной излишней возможностью язык (осложняя этим жизнь авторам компиляторов D).
[В начало ⮍](#6-16-объекты-scope-17) [Наверх ⮍](#6-классы-объектно-ориентированный-стиль)
## 6.17. Итоги
Классы – это основное средство для реализации объектно-ориентированных решений в D. Они повсюду используют ссылочную семантику и утилизируются сборщиком мусора.
Наследование позволяет использовать динамический полиморфизм. Разрешено только одиночное наследование, но класс может стать наследником нескольких интерфейсов. Интерфейсы не обладают собственным состоянием, но могут определять финальные методы.
Правила защиты соответствуют правилам защиты, принятым в операционной системе (каталоги и файлы).
Все классы обладают общим предком – классом `Object`, определенным в модуле `object`, который является частью реализации D. Класс `Object` определяет несколько важных примитивов, а модуль `object` – функции, на которые опирается сравнение объектов.
Класс может определять вложенные классы, автоматически сохраняющие ссылку на свой внешний класс, и статические вложенные классы, которые не сохраняют ссылку на внешний класс.
D полностью поддерживает технику невиртуальных интерфейсов, а также полуавтоматический механизм для множественного порождения подтипов.
[В начало ⮍](#6-17-итоги) [Наверх ⮍](#6-классы-объектно-ориентированный-стиль)
[🢀 5. Данные и функции. Функциональный стиль](../05-%D0%B4%D0%B0%D0%BD%D0%BD%D1%8B%D0%B5-%D0%B8-%D1%84%D1%83%D0%BD%D0%BA%D1%86%D0%B8%D0%B8-%D1%84%D1%83%D0%BD%D0%BA%D1%86%D0%B8%D0%BE%D0%BD%D0%B0%D0%BB%D1%8C%D0%BD%D1%8B%D0%B9-%D1%81%D1%82%D0%B8%D0%BB%D1%8C/) **6. Классы. Объектно-ориентированный стиль** [7. Другие пользовательские типы 🢂](../07-%D0%B4%D1%80%D1%83%D0%B3%D0%B8%D0%B5-%D0%BF%D0%BE%D0%BB%D1%8C%D0%B7%D0%BE%D0%B2%D0%B0%D1%82%D0%B5%D0%BB%D1%8C%D1%81%D0%BA%D0%B8%D0%B5-%D1%82%D0%B8%D0%BF%D1%8B/)
[^1]: Язык D также предоставляет возможность «ручного» управления памятью (manual memory management) и на данный момент позволяет принудительно уничтожать объекты с помощью оператора delete: `delete obj;`, при этом значение ссылки `obj` будет установлено в `null` (см. ниже), а память, выделенная под объект, будет освобождена. Если `obj` уже содержит `null`, ничего не произойдет. Однако следует соблюдать осторожность: повторное уничтожение одного объекта или обращение к удаленному объекту по другой ссылке приведет к катастрофическим последствиям (сбои и порча данных в памяти, источники которых порой очень трудно обнаружить), и эта опасность усугубляет необходимость в сборщике мусора. Из-за этих рисков оператор `delete` планируют убрать из самого языка, оставив в виде функции в стандартной библиотеке. Но при этом ручное управление памятью позволяет более эффективно ее использовать. Вердикт: задействуйте эту возможность, если уверены, что на момент вызова `delete` объект `obj` точно не удален и `obj` – последняя ссылка на данный объект, и не удивляйтесь, если в один прекрасный день `delete` исчезнет из реализаций языка. – *Прим. науч. ред.*
[^2]: На данный момент реализации D предоставляют средства выделения памяти под классы в стеке (с помощью класса памяти `scope`) или вообще в любом фрагменте памяти (с помощью классовых аллокаторов и деаллокаторов). Но поскольку эти возможности небезопасны, они могут быть удалены из языка, так что не рассчитывайте на их вечное существование. – *Прим. науч. ред.*
[^3]: В текущих реализациях использование `void` не влияет на производительность, так как все поля класса инициализируются «одним махом» копированием памяти из `.init` для экземпляров класса. – *Прим. науч. ред.*
[^4]: В соответствии с предыдущим примечанием сегодня этот тест не пройдет. – *Прим. науч. ред.*
[^5]: Описание этой части языка намеренно не было включено в оригинал книги, но поскольку эта возможность имеется в языке, мы включили ее описание в перевод. – *Прим. науч. ред.*
[^6]: Образ из книги «Краткая история времени» Стивена Хокинга: Вселенная как плоский мир, стоящий на спине гигантской черепахи, «та – на другой черепахе, та – тоже на черепахе, и так все ниже и ниже». – *Прим. ред.*
[^7]: Ф. Брукс «Мифический человеко-месяц». – Символ-Плюс, 2000.
[^8]: `rhs` (от right hand side – справа от) – значение, в выражении расположенное справа от оператора. Аналогично `lhs` (от left hand side – слева от) – значение, в выражении расположенное слева от оператора. – *Прим. ред.*
[^9]: Интересно, что семантика использования `opCmp` та же, что и в функциях сравнения памяти и строк в языке C. – *Прим. науч. ред.*
[^10]: Виртуа льный метод – метод, который переопределяет другой метод или сам может быть переопределен. – *Прим. науч. ред.*
[^11]: Это напоминает виртуа льное наследование в С++. – *Прим. науч. ред.*
[^12]: Сходный механизм используется при возвращении функцией делегата и образовании замыканий, однако следует учитывать, что компилятор выполняет описанные действия строго для предопределенных языком случаев (таких как внутренние классы и делегаты). Попытка функции вернуть указатель на локальную переменную ни к чему хорошему не приведет. – *Прим. науч. ред.*
[^13]: Аргументы конструктора при создании анонимного класса передаются сразу после ключевого слова `class`, а если создается анонимный класс, реализующий список интерфейсов, то эти интерфейсы указываются через запятую после имени суперкласса. Пример: `new class(arg1, arg2) BaseClass, Interface1, Interface2 {};`. – *Прим. науч. ред.*
[^14]: К сожалению, текущая на момент выхода книги версия компилятора допускала только одно объявление `alias this`. – *Прим. науч. ред.*
[^15]: Deus ex machina («бог из машины») – в древнегреческом театре: бог, спускающийся с небес (изображающий его актер мог «летать» при помощи механического крана) и решающий все проблемы героев. В переносном смысле – неожиданная удачная развязка неразрешимой ситуации. – *Прим. ред.*
[^16]: Описание этой части языка намеренно не было приведено в оригинале книги, но поскольку эта возможность присутствует в текущих реализациях языка, мы добавили ее описание в перевод. – *Прим. науч. ред.*
[^17]: Описание этой части языка намеренно не было приведено в оригинале книги, но поскольку эта возможность присутствует в текущих реализациях языка, мы добавили ее описание в перевод. – *Прим. науч. ред.*